Вордстат яндекса
Содержание:
Описание
Wordstat Yandex или Подбор слов — это бесплатный сервис Яндекса, предназначенный для оценки пользовательского интереса к различным тематикам и подбора ключевых слов для SEO-оптимизации и контекстной рекламы. Кроме того, с помощью Яндекс Вордстат можно оценить сезонность и географическую зависимость поисковых запросов.
Особенности работы сервиса
- Wordstat не работает без регистрации. Ранее такая возможность была, однако с недавних пор инструмент запускается только после авторизации в Яндекс. Почте.
- Вордстат фильтрует пользователей. Под фильтры системы можно попасть из-за нарушения лицензии на использование Яндекса, а также из-за DDOS-атак на сервис с вашего компьютера в результате деятельности вируса. Стоит отметить, что в качестве атаки на сервер может быть воспринята работа специальных парсеров – программ, собирающих ключевые словосочетания в автоматическом режиме (например, Key Collector).
- Периодически при работе может выскакивать Captcha, приостанавливающая работу с Вордстатом. Возникает это из-за некорректного IP-адреса (для пользователей из не постсоветских стран), закрытых файлов cookie или отсутствии поддержки JS-скриптов на компьютере.
В Яндекс Wordstat доступны срезы по типам устройств пользователей:
- Срез «Десктопы» для запросов, введенных с компьютеров и ноутбуков,
- Срез «Мобильные» для запросов, введенных с планшетов и смартфонов,
- Срез «Только телефоны» – запросы исключительно со смартфонов,
- Срез «Только планшеты» – запросы, введенные только с планшетов.
Операторы Вордстат
- Оператор «-» (минус-слово). Позволяет исключить слово из статистики запросов. Применяется отдельно для каждого слова. Чтобы исключить словосочетание, необходимо добавлять оператор минус перед каждым словом в поисковой строке сервиса.
- Оператор «+» (учет стоп-слов). Позволяет учитывать в статистике союзы и предлоги во всех словоформах, которые игнорируются поисковой системой. При детализации запроса (левая колонка) оператор «+» по умолчанию используется во всех фразах, содержащих стоп-слова.
- Оператор «|» (логическое «или»). Позволяет получить статистику одновременно по нескольким условиям. Работает по правилу логического «или».
- Оператор «()» (логическое «и»). Необходим для группировки запросов, а в паре с оператором «|» позволяет создать регулярное выражение и получить список поисковых фраз по комбинации условий.
- Оператор «» (словоформа). В данном случае фиксируется запрос, поэтому из статистики удаляются дополнительные слова. Учитываются различные окончания, стоп-слова, но не учитывается порядок слов.
- Оператор «!» (точное вхождение). Его использование запускает фиксацию словоформы, т.е. будет учтена фраза только с текущим окончанием слов, но не учитывается порядок слов в запросе.
- Оператор «[]» (учет порядка слов). Необходим чтобы зафиксировать порядок слов в запросе. При этом будут учитываться словоформы и стоп-слова.
История запросов: смотрим сезонность и отслеживаем тренды
Сервис выдаёт информацию только за прошлые годы, возможности получить статистику за текущий период нет. Инструмент «История запросов» выводит данные за два года и наглядно показывает, в какие месяца товар или услуга наиболее востребованы. Эта опция особенно полезна для сезонных предложений.
По запросу «кирпич купить» мы видим, что спрос возрастает с приходом весны и достигает минимального значения зимой. Это простой пример сезонного спроса на товар. Группировать данные можно не только по месяцам, но и по неделям для более детального рассмотрения.

Синим и красным цветом на графике отображаются абсолютный и относительный показатели. Абсолютное значение – это цифра, наглядно показывающая, сколько запросов по этому слову/словосочетанию было фактически за данный период. А вот относительное значение указывает на популярность анализируемого запроса среди всех запросов в поисковой системе.
Здесь же можно определять тренды – запросы, постепенно набирающие популярность. Так, после выпуска селфи-дрона, появился неустойчивый, но возрастающий периодами спрос. При этом запрос «селфи дрон» и «купить селфи дрон» имеют примерно одинаковую статистику. Вполне можно ожидать повышение коммерческих запросов на данный продукт.


World Population (2020 and historical)
| Year (July 1) | Population | Yearly % Change | Yearly Change | Median Age | Fertility Rate | Density (P/Km²) | Urban Pop % | Urban Population |
|---|---|---|---|---|---|---|---|---|
| 2020 | 7,794,798,739 | 1.05 % | 81,330,639 | 30.9 | 2.47 | 52 | 56.2 % | 4,378,993,944 |
| 2019 | 7,713,468,100 | 1.08 % | 82,377,060 | 29.8 | 2.51 | 52 | 55.7 % | 4,299,438,618 |
| 2018 | 7,631,091,040 | 1.10 % | 83,232,115 | 29.8 | 2.51 | 51 | 55.3 % | 4,219,817,318 |
| 2017 | 7,547,858,925 | 1.12 % | 83,836,876 | 29.8 | 2.51 | 51 | 54.9 % | 4,140,188,594 |
| 2016 | 7,464,022,049 | 1.14 % | 84,224,910 | 29.8 | 2.51 | 50 | 54.4 % | 4,060,652,683 |
| 2015 | 7,379,797,139 | 1.19 % | 84,594,707 | 30 | 2.52 | 50 | 54.0 % | 3,981,497,663 |
| 2010 | 6,956,823,603 | 1.24 % | 82,983,315 | 28 | 2.58 | 47 | 51.7 % | 3,594,868,146 |
| 2005 | 6,541,907,027 | 1.26 % | 79,682,641 | 27 | 2.65 | 44 | 49.2 % | 3,215,905,863 |
| 2000 | 6,143,493,823 | 1.35 % | 79,856,169 | 26 | 2.78 | 41 | 46.7 % | 2,868,307,513 |
| 1995 | 5,744,212,979 | 1.52 % | 83,396,384 | 25 | 3.01 | 39 | 44.8 % | 2,575,505,235 |
| 1990 | 5,327,231,061 | 1.81 % | 91,261,864 | 24 | 3.44 | 36 | 43.0 % | 2,290,228,096 |
| 1985 | 4,870,921,740 | 1.79 % | 82,583,645 | 23 | 3.59 | 33 | 41.2 % | 2,007,939,063 |
| 1980 | 4,458,003,514 | 1.79 % | 75,704,582 | 23 | 3.86 | 30 | 39.3 % | 1,754,201,029 |
| 1975 | 4,079,480,606 | 1.97 % | 75,808,712 | 22 | 4.47 | 27 | 37.7 % | 1,538,624,994 |
| 1970 | 3,700,437,046 | 2.07 % | 72,170,690 | 22 | 4.93 | 25 | 36.6 % | 1,354,215,496 |
| 1965 | 3,339,583,597 | 1.93 % | 60,926,770 | 22 | 5.02 | 22 | N.A. | N.A. |
| 1960 | 3,034,949,748 | 1.82 % | 52,385,962 | 23 | 4.90 | 20 | 33.7 % | 1,023,845,517 |
| 1955 | 2,773,019,936 | 1.80 % | 47,317,757 | 23 | 4.97 | 19 | N.A. | N.A. |
Source: Worldometer (www.Worldometers.info) Elaboration of data by United Nations, Department of Economic and Social Affairs, Population Division. World Population Prospects: The 2019 Revision. (Medium-fertility variant).
Вордстат: как с ним работать и какие операторы использовать
Для того, чтобы работать с Вордстатом и использовать все его операторы, необходимо помнить несколько важных правил. Первое и самое главное то, что это очень просто, и каждый сможет справиться с поставленной задачей.
Остальные пункты звучат так:
- Яндекс Вордстат абсолютно бесплатный;
- Для пользования нужно зарегистрироваться в Яндексе;
- С помощью Вордстата удобно подбирать ключевые слова для контента;
- Выдача зависит от сезонности;
- В Вордстате не обязательно пользоваться только разделом «По словам».
Удобно то, что в Вордстате можно сделать сортировку по регионам. В отличие от разработки сайта-визитки под ключ, это делается довольно просто.
Для этого нужно будет нажать кнопку «Все регионы» и в появившемся окошке проставить необходимые галочки. Кстати, здесь же справа, Вы найдете очень удобную опцию «Быстрый выбор». С её помощью можно в один клик обозначить для подбора слов наиболее распространенные географические варианты: Москва и область; Санкт-Петербург и область; Украина; Россия, СНГ и Грузия.
Как и в поисковых системах, в Вордстате можно использовать синтаксические знаки для уточнения запроса. Ниже мы рассмотрим, как использовать операторы в Вордстате и какую функцию выполняет каждый из них. В приведённой таблице наглядно продемонстрированы распространённые символы и их значения, где ххх и ууу — это любые слова.
| СИМВОЛ | ЗНАЧЕНИЕ |
| -ххх | Неиспользование слова |
| +ххх | Обязательное использование слова |
| «ххх ууу» | Вхождение только этих слов, но их порядок и окончания могут быть различными |
| !ххх | Точное вхождение слова (фиксация окончания) |
Знак минус («-») перед словом помогает убрать из полученного списка все словосочетания, где оно находится. Например, вбив в Вордстат «популярные запросы –слова», мы уберём из выдачи словосочетания вроде «популярные слова запроса», «популярные слова в запросах» и другие.
Знак плюс («+») даёт обратный эффект и подразумевает наличие слова, перед которым он стоит в выдаче. Это относится к предлогам и союзам, так как в обычном режиме Вордстат полностью игнорирует многие служебные части речи.
Если точнее, то сервис НЕ замечает короткие союзы и предлоги («и», «к»…), хотя более длинные удостаивает вниманиям («перед», «также»…). Например, мы вводим в поиск фразу «популярные запросы в яндексе», то в списке среди прочих запросов находим и «популярные поисковые запросы яндекс», и «топ популярных запросов яндекс», и другие словосочетания без предлога «в». А если мы вобьем «популярные запросы +в яндексе», то получим лишь то, что искали.
Знак кавычки («») позволяет уточнить выдачу, ведь в ней Вы увидите «закавыченные». Однако, их порядок и окончания могут отличаться.
Восклицательный знак («!») поможет получить точное «вхождение» в слова с нужным нам числом и падежом.
Яндекс Вордстат считается одним из полезнейших сервисов, который, несомненно, подкупает своей простотой. Благодаря этому, будь Вы новичком или же продвинутым пользователем, методы СЕО-продвижения сайта с использованием Вордстата станут понятны каждому.
Программы парсеры
Для точной обработки ключевых слов рекомендуется использовать программные комплексы. Преимущество – они работают напрямую с базами данных Ворстат. Полная версия платная, некоторые разработчики предоставляют демо-режим с ограниченным функционалом.
Кей Коллектор
Программа «Кей Коллектор» популярна среди разработчиков и СЕО-оптимизаторов. Причины – работа с популярными поисковыми системами, сегментация выборок по параметрам пользователя. Предоставляется только на платной основе, стоимость зависит от количества приобретаемых лицензий.
Особенности «Кей Коллектор»:
- Анализируется только актуальная статистика, сбор информации ведется напрямую из баз данных (БД) Яндекса.
- Ключевые слова подбираются по региону, частоте, сезонности.
- Учитываются стоп-слова.
Возможен многопоточный режим работы. Но есть вероятность получения бана или многократного ввода капчи при формировании нескольких потоков запроса информации с одного IP. Возможен сбор информации через Яндекс.Директ, что уменьшает скорость обработки.
Словоёб
Бесплатная альтернатива Кей Коллектор, но с меньшими функциональными возможностями. Отличие – «Словоёб» работает только с Вордстат. При анализе некоторых ключевых фраз могут не учитываться низкочастотные запросы, которые есть в статистике Яндекс.Директ. Глубина эффективного парсинга ограничена 40 страницами.
Особенности программы «Словоёб»:
- меньшие возможности работы с таблицами;
- нет «поисковых подсказок»;
- отсутствует сбор главных страниц выдачи;
- нет позиций по запросам.
Программа подходит для формирования СЯ небольшого проекта. Причина – скорость обработки полученных данных, нет углубленного анализа запросов.
Магадан
Технические ограничения в бесплатном варианте программы:
- нельзя выбрать региональность для запросов;
- отключены фильтры по количеству символов, слов;
- нет импорта файлов со стоп-словами;
- нельзя задавать правила к генерируемым ключевым фразам;
- отключен экспорт КС.
Несмотря на такие ограничения «Магадан» можно использовать для формирования СЯ 1-3 проектов. Но по отзывам пользователей по сравнению с ручной обработкой Вордстата теряются низкочастотные запросы.
Инструменты для упрощения работы с «Вордстатом» – расширения и программы
Работать с «Вордстатом» просто – научиться сносно пользоваться пятью операторами можно за полчаса. А вот собирать большие объемы данных и работать с ними – уже сложнее. В первой части статьи были рассмотрены основы работы с «Вордстатом», потому что без понимания какие данные и почему отдаются сервисом, невозможно эффективно использовать средства автоматизации. Вот три самых популярных программы:
- «Яндекс Вордстат Ассистент»;
- «Яндекс Вордстат Хелпер»;
- «Кей Коллектор» (и его бесплатная версия).
«Яндекс Вордстат Ассистент»
На официальном сайте https://semantica.in/tools/yandex-wordstat-assistant выбираем браузер, который используется для работы. После установки возле каждого запроса появится возможность добавить или удалить его из списка:
Все «проплюсованные» запросы добавляются в список. После того, как все нужные запросы скопированы в список, можно:
- Посмотреть в списке количество добавленных фраз и их суммарную частотность (цифры 2 и 25 над списком на скриншоте выше).
- Скопировать фразы в буфер обмена.
- Скопировать фразы и их частотность в буфер обмена.
- Отсортировать запросы по убыванию или по возрастанию в алфавитном порядке, по порядку добавления в список или по частотности.
Основной плюс – простота использования, дополнение бесплатное. Основной минус – инструмент собирает только фразу и базовую частотность запроса.
«Яндекс Вордстат Хелпер»
Установить дополнение можно также выбрав браузер на странице официального сайта https://arcticlab.ru/yandex-wordstat-helper/
Фактически, это полный аналог предыдущего дополнения, но чуть более удобный (сортировку можно сделать в 1 клик).
Еще один недостаток обоих дополнений – муторная ручная работа при работе с большим количеством запросов. Я уже писал ранее, что популярный запрос может отдавать данные на 40 страницах по убыванию частотности. Чтобы только собрать эти данные, нужно будет произвести более 80 кликов (40 переходов на следующую страницу и 40 добавлений запросов в дополнение).
«Кей Коллектор», описание и настройка парсера данных из «Яндекс.Вордстат»
По сути, это комбайн для работы с данными. Я не буду пересказывать справку программы, а напишу только о плюсах и минусах «Кей Коллектора» при работе с «Вордстатом».
Сначала о минусах. Их всего четыре:
- Как я уже писал, программа платная.
- Потребуется завести отдельные аккаунты в «Яндексе» для «Кей Коллектора», так как при частых автоматических запросах может быть затруднен доступ к «Вордстату» (будет выбиваться несколько капч на каждый запрос).
- Нужно будет 1 раз настроить программу по справке или по скриншотам моих настроек для быстрого сбора данных.
- Потребуется оплатить 1 из сервисов антикапчи, чтобы можно было поставить программу на сбор данных и забыть о ней. Хотя я собираю данные в промышленных объемах (сотни тысяч запросов в месяц), мне на 3 компьютера хватает 150–350 рублей в месяц на оплату антикапча-сервисов.
Теперь интерфейс:
Полный обзор возможностей программы лежит за рамками темы о «Вордстате», потому что краткий видео обзор возможностей программы занимает около полутора часов. Я обозначу только настройки, которые нужны для того, чтобы быстро начать работать с «Вордстатом».
Три волшебных кнопки:
- Сбор фраз из «Яндекс Вордстат». Аналогично тому, как если бы вы руками с каждой страницы копировали запрос и частотность в таблицу.
- Сбор поисковых подсказок. Если вы каждую фразу будете вставлять в поиск и выписывать для нее поисковые подсказки – получите такой же результат, как и программа.
- Сбор частотностей в кавычках «» и с уточнением словоформы «!». Работает так же, как если бы вы каждый запрос вбивали с этими операторами и записывали цифры.
Порядок действий – сначала собираем запросы (1), затем частотность (3). По интересующим запросам собираем подсказки (2) и снова частотность (3).
Полученный результат:
Фактически, сбор десятков тысяч запросов со всеми данными занимает 2-3 часа.
Я приведу настройки, которые нужно сделать, чтобы собирать данные с лучшим сочетанием скорости и дешевизны (не супер быстро, но с небольшим расходом на антикапчу). По порядку:
Сбор разных видов частотностей проходит через «Яндекс.Директ» – настраиваем и его:
Кроме этого в верхней части этого окна нужно добавить несколько аккаунтов «Яндекса»:
И последнее что нужно сделать – зарегистрироваться в любом из совместимых сервисов разгадки капчи, получить в нем код для работы и ввести его в настройках:
Я пробовал разные схемы настроек, эта – самая эффективная и простая.
Остальные 200 кнопок и настроек я предлагаю вам освоить самостоятельно (-:
Существует и бесплатная версия «Кей Коллектора» – программа «Словоеб», которая так же позволяет полноценно работать с «Вордстатом». Ссылка на сайт программы.
Ответы на вопросы, хитрости при работе с «Вордстатом»
За годы работы с «Вордстатом» у меня накопилась небольшая методичка по ответам на часто задаваемые неочевидные вопросы. Думаю, вы найдете что-то полезное.
Собрали кучу данных
Как проводить анализ запросов? На что обращать внимание?. В первую очередь обращаем внимание на коммерческие запросы, у которых частота без кавычек и в кавычках отличается плюс-минус в 2 раза или менее
Если при еще и слабая выдача (нет нормальных предложений), вообще отлично
В первую очередь обращаем внимание на коммерческие запросы, у которых частота без кавычек и в кавычках отличается плюс-минус в 2 раза или менее. Если при еще и слабая выдача (нет нормальных предложений), вообще отлично
Чем больше расхождение в цифрах, тем больше у вас шанс не угадать намерение пользователя. Например, запрос «боковое стекло хендай» плохой, потому вообще непонятно, что ищут. Дефлектор бокового стекла? Само стекло? Левое? Правое? Переднее? Купить или продать?
Пример хорошего запроса:
2. Как посмотреть статистику запросов для одного города?
Выберите свой город в настройках региона. Помимо города хорошо бы понимать целевую аудиторию и дополнительно затачивать сайт под целевую аудиторию. Например, эвакуатор или вскрытие дверей почти наверняка будут искать со смартфона или планшета.
3. Как обойти ограничение на длину запроса в 8 слов?
Через «Вордстат» такие данные собрать нельзя. Запросы из 8 и более слов можно собрать в поисковых подсказках, найти в различных базах запросов или получить в статистике своего сайта.
4. Что означают абсолютные и относительные данные в истории запросов?
Абсолютный показатель – это фактическое цифровое значение, сколько было таких запросов за период. Относительное значение показывает популярность запроса среди всех запросов в поиске.
5. Что делать, если «Вордстат» собрал 2000 запросов, но нужно больше?
В широких нишах на 40-й странице «Вордстата» только начинается самое интересное:
Если в «Вордстат» ввести запрос в кавычках, повторяя основное слово, вы увидите все запросы из Х слов, содержащих нужное слово. Х – количество слов во фразе в кавычках. Пример:
Используя поочередно конструкции:
- «налог налог налог налог налог налог налог»
- «налог налог налог налог налог налог»
- «налог налог налог налог налог»
- «налог налог налог налог»
- «налог налог налог»
- «налог налог»
- налог
Можно собрать все запросы, которые содержат слово «налог» или его склонения.
6. Как провести массовую проверку частотности запросов из «Вордстат»?
Массово проверить все частотности фраз можно сделать в «Кей Коллекторе» или его бесплатном аналоге – программе «Словоеб».
7. Как убрать капчу в «Вордстате»?
Причина появления капчи – большое количество запросов с 1 IP адреса. Вы можете или сменить айпишник, или использовать программы для работы с «Вордстатом» вместе с сервисами разгадывания капчи.
8. Почему у «Вордстата» ограничение длины в 7 слов?
«Вордстат» изначально был создан как сервис статистики для «Яндекс Директа», в котором максимальное количество слов в рекламной фразе – 7. Никаких других причин для ограничения запроса нет.
Источник статьи
Как работать с Вордстатом
Сервис подбора слов помогает просматривать обобщенную статистику по запросам, а также оценивать частотность в зависимости от различных факторов. В Wordstat также есть набор операторов, с помощью которых можно узнать реальное число запросов для определенной формы слова или фразы.
Фильтры
Чтобы посмотреть статистику в срезе по устройствам, используйте фильтр. Он доступен в каждом разделе. Wordstat разделяет мобильные устройства на телефоны и планшеты.
Для просмотра данных по разным регионам, нажмите «Все регионы». Откроется окно, где можно уточнить регион показов.
Переключитесь на вкладку «По регионам», чтобы узнать число показов страниц по запросам из конкретного города, страны или региона, а также по все регионам вместе. Здесь можно посмотреть статистику на карте, если удобно. Также можно применить фильтры по устройствам, чтобы сузить поиск.
Здесь доступны два столбца с цифрами:
- «показов в месяц» — количество показов из региона за месяц;
- «региональная популярность» — доля, которую занимает регион в показах по данному слову, деленная на долю всех показов результатов поиска в этом регионе.
100% — это среднее значение. Если оно меньше 100%, то интерес пользователей к этому слову понижен, и наоборот.
Яндекс уточняет, что региональная популярность — это affinity index в отчетах Яндекс.Метрики.
Следующий раздел в интерфейсе — «История запросов». В первую очередь он помогает подобрать слова для бизнесов, где ярко выражена сезонность и не получается собрать семантику на основе статистики за месяц. В «Истории запросов» показывается динамика показов за два года.
Статистику можно смотреть в абсолютных или относительных значениях. Для получения относительного значения абсолютная цифра нормируется на количество показов результатов поиска Яндекса за соответствующий месяц.
Операторы
Операторы в Wordstat помогают уточнить запросы и получить более детальную статистику по ним. Их можно применить только во вкладках «По словам» и «По регионам». Рассмотрим основные операторы, которые пригодятся специалисту на начальном этапе работе.
-
Кавычки фиксируют количество слов в запросе. Это помогает посмотреть, сколько раз пользователи вводили эту фразу. Система учитывает разный порядок слов и разные окончания. Повторяющиеся слова считаются за одно слово.
- Восклицательный знак нужен, чтобы посмотреть статистику по конкретной форме слова. Он ставится перед словом, которое не должно видоизменяться.
- С помощью оператора «Плюс» можно включать в запрос предлоги или другие служебные слова.
- «Минус» исключает слова из запроса.
- Если заключить ключевую фразу в квадратные скобки, система выдаст число запросов для фразы с сохранением порядка слов. При этом учитываются разные словоформы и предлоги.
Посмотрим на примеры использования. Если нужно узнать точное количество запросов исключительно по заданной фразе без дополнительных слов и без учета словоформ, нужно использовать два оператора: кавычки и восклицательный знак.
Чтобы исключить запросы, не совпадающие с тематикой продвижения, используйте оператор минус вместе с восклицательным знаком. Как в известном примере, вы не будете показывать рекламу бильярдного кия пользователям, которые интересуются покупкой машины Kia и ошиблись в правописании.
Как правильно пользоваться Вордстатом
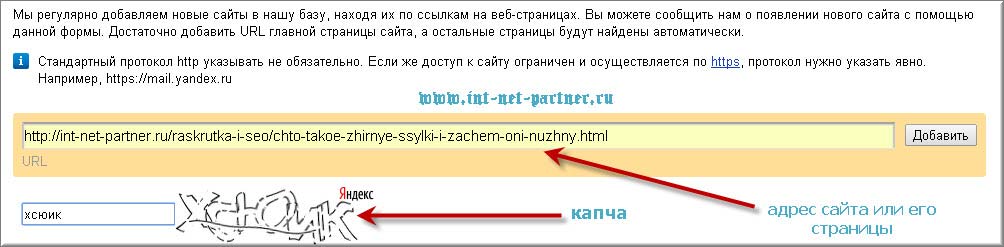
Сначала там нужно зарегистрироваться. Вот ссылка на сервис, вы можете и без регистрации вводить в нем слова, но вот результаты узнавать сможете только после регистрации. Иначе будет всплывать такая херня:
После того, как зарегаетесь, вводите там слово и жмите кнопку «Подобрать». Вы получите такие результаты:
Как видите, мы ввели слово «браток», и в левой колонке будут запросы, в которых присутствует фраза «браток». Эти запросы вводят реальные пользователи. В правой колонке — похожие запросы. Цифры рядом с каждым запросом — это их частотность (то есть насколько часто пользователи их вводят). Но это не точная частотность, а приблизительная. То есть саму фразу «браток» именно в такой форме может вводили раз 20 всего (то есть точная частотность у нее 20 тогда), но вместе с фразами «братки», «братки 90», «давай браток» и другими у нее частотность 27 080. Точную же частотность мы научимся определять далее.
Давайте теперь смотреть остальные функции интерфейса:
В блоке 1 — переключение между типом устройств. Я лично не использую. Я свои сайты делаю удобными для всех типов устройств.В блоке 2 — очень полезный переключатель. С его помощью можно посмотреть, во-первых, региональность запроса (в каком регионе его вводят чаще, в каком — реже). Можно серьезно залипнуть на этом инструменте. А во-вторых, тут можно посмотреть «Историю запроса» — и это действительно иногда очень нужно бывает для определения сезонности запроса и для отслеживания тренда.В блоке 3 — дата, когда последний раз Яндекс обновлял статистику по запросам. В большинстве случаев нам это не нужно.В блоке 4 — выбираем регион/регионы.
По регионам
Можно посмотреть, что где ищут. Забавная штука. Тут, например, можно выяснить, что блатные песни в среднем на душу населения больше всего ищут вовсе на в РФ, а в Греции и таки в Израиле:
А если вы нажмете на Россию, то увидите, что блатняк востребован в общем-то везде, но особенно — в Дагестане:
История запроса
В истории запроса можно определять сезонные запросы и тренды, как я уже говорил. Например, мы можем лишь завидовать тем вебмастерам, кто успел написать статьи про Трампа, потому что сейчас (конец 2016) у них начался рост трафика:
Но самое профессиональное начинается, когда вы работаете с операторами.
Базовые операторы
Два базовых оператора — восклицательное слово и кавычки. Это азы азов.
Смотрите, без них у нас 25 655 показов. Это показы всех фраз со словом «браток».
С кавычками же всего 832. Кавычки фиксируют фразу. Это значит, что 832 показа — у фраз «браток», «братка», «братку», вместе взятых, то есть у этой фразы с разным порядком слов и окончаниями, но без добавления к этой фразе других слов. То есть сюда не включаются показы фраз «мы братки», «завалили братка» и так далее.
С восклицательным знаком — 7409 показов. Он фиксирует словоформу. То есть сюда включаются показы фраз «браток», «ништяк браток», «держись браток» и других с таким же окончанием. А показы фраз «позвонить братку», «скачать песню про братка» и так далее — не включаются.
А тут мы имеем всего 152 показа. Это потому, что с восклицательным знаком и кавычками учитываются показы только этой фразы и только в этой форме. Но с разным порядком слов в фразе. То есть если мы введем «ништяк браток», то Вордстат нам покажет сумму показов «ништяк браток» и «браток ништяк».
Вспомогательные операторы
Плюс. Символ «+» принудительно учитывает стоп-слова. По умолчанию Вордстат не учитывает предлоги, и по запросу «как купить телевизор» покажет вам в основном коммерческие запросы:
Если вам важна частица «как», то зафиксируйте её плюсом и Wordstat даст уже такие данные:
Оператор «ИЛИ». Прямой слэш «|» — если две фразы разделить этим оператором, он покажет все вариации с этими двумя фразами.
Минус. Символ «-» исключает конкретное слово из запроса. Пример: «купить машину в Москве -бу». Будут показаны запросы без употребления слова «бу».
Круглые скобки «()» — группирует использование нескольких операторов.
Квадратные скобки «[]» — фиксирует последовательность слов в поисковой фразе. Этот оператор ввели не так давно. То есть мы получаем возможность узнать, с каким порядком слов фразу вводят чаще всего:
Как видим, с неправильным порядком фразу почти никто не вводит:
Зачем нужен Вордстат?
Инструмент незаменим в таких случаях:
предстоит писать SEO-оптимизированные тексты, для которых важно определить состав ключевых фраз и частотность употребления;
необходимо составить структуру для новой страницы или для всего сайта;
нужно уточнить, какие слова в Вордстат вводят представители целевой аудитории, обращаясь к поисковой системе для решения проблемы, и как именно они формулируют мысли;
требуется выяснить, какие дополнительные интересы имеются у представителей целевой аудитории, чтобы грамотно составить ассортимент товаров и выкладывать максимально полезный контент.
Операторы для работы с Wordstat Yandex
1. Оператор кавычки
Поставив запрос в кавычки, мы фиксируем слова, которые есть в запросе. Например, если запрос «лыжные палки» взять в кавычки, то будет показано суммарное число запросов, которое включает следующие варианты:
Порядок слов и окончания могут изменяться.
2. Оператор восклицательный знак
Чтобы зафиксировать нужное нам окончание есть специальный оператор восклицательного знака. Для того чтобы воспользоваться им необходимо перед словом (или словами) поставить восклицательный знак. Таким образом, мы получим нужную словоформу. Например, «!лыжные !палки».
Оператор кавычек и восклицательного знака используются часто и являются самыми ходовыми и востребованными.
3. Оператор квадратные скобки
Оператор [] появился недавно. Он позволяет зафиксировать порядок слов. Многие вебмастера и оптимизаторы хотели его появления и спустя много лет Яндекс их услышал и реализовал. Например, «».
4. Оператор плюс (+)
Ставя плюс перед словом, оно становится обязательным. Это скорее относится к предлогам, поскольку они часто не учитываются. Например, для предлогов «как», «что», «когда», «куда» и т.п. это будет критичным. Например «+как заработать на сайте». Будет обязательно учитывать слово «как». Если мы не поставим плюс, то будут учитываться частотности для запроса «заработать на сайте».
5. Оператор или (|)
Оператор или (|) полезен в тех случаях, когда слово может быть написано на английском или русском. Например, (биткоин|bitcoin).
Программы для упрощённой работы с Wordstat Yandex
Чтобы делать более быстро выгрузки данных из сервиса Яндекс Вордстат использует различные программы. Например, Кейколлектор.
Статистика ключевых слов в Яндекс Вордстат по регионам
Очень полезный раздел для всех, кто продвигается в конкретном регион или ищет данные с точной ГЕО- привязкой.
По умолчанию «Поиск по словам» позволяет получить данные по всем регионам. Если вам нужно провести анализ поисковой фразы с учётом региона, прямо под поисковой строкой (справа), кликаем «Все регионы»:
Откроется окно выбора региона. Скорее всего, вы будете искать данные о частотности по какому-то российскому региону, поэтому, раскрываем регион Россия:
…и далее выбираем округ:
Допустим, нас интересует Москва. Раскрываем «Центр», выбираем «Москва и область» и область, кликаем «Москва»:
Не забываем кликнуть «Выбрать» (вверху страницы), чтобы сохранить настройки поиска:
Теперь Wordstat Yandex будет учитывать популярность той или иной поисковой фразы только у тех пользователей, которые пользуются поиском из Москвы (обратите внимание — без учёта Щербинки, Зеленограда и Троицка).
Вы также, можете получить данные по частотности выбранной фразы в виде рейтинга-списка. Чтобы сделать это, достаточно отметить чекбокс «По регионам»:
Видим, что фраза “москва что посмотреть” наиболее популярна у пользователей ЦФО, если быть точнее — у пользователей из Москвы и Московской области:
Удобно, что все данные по популярности фразы можно посмотреть, как отдельно для списка конкретных городов, так и для списка регионов:
Кроме суммарного количества показов, здесь также есть метрика «Региональная популярность»:
Данная метрика представляет из себя affinity index – позволяющая судить об уровне интереса поисковой фразы в конкретном регионе
Необходимо обратить внимание на процентное значение, если % превышает 100, то можно говорить о повышенном интересе к запросу в выбранном регионе (относительно иных запросов), если менее 100% — о пониженном.. Данные по частотности поисковой фразы, с учётом регионов, доступны не только в виде списка, но и на интерактивной карте, что очень удобно
Особенно если вы цените наглядное представление:
Данные по частотности поисковой фразы, с учётом регионов, доступны не только в виде списка, но и на интерактивной карте, что очень удобно. Особенно если вы цените наглядное представление:
Каждый регион кликабелен:
Россия детальнее:
На что стоит обращать внимание в статистике?
Первое, на что нужно обратить внимание — три разных рейтинга, объективно показывающие успехи танкиста. Это РЭ, WN8, а также рейтинг от Wargaming
Винрейт — святая святых почти любого игрока. Если винтейт выше 50%, это значит, что танкист приносит пользу команде.
Третий важный показатель — это дамаг за бой. Большинство танкистов предпочитают наносящие урон классы, поэтому можно оценить танкиста и его среднюю эффективность.
Средний уровень боев — если у игрока средний уровень пятый или, например, шестой, то сразу становится понятно, что на десятых уровнях ездить ему не очень нравится. Благодаря этой информации можно оценивать претендентов на вступление в клан, часто воюющий на ГК.
Два соотношения — убил\убит и нанес\получил урона. У опытных танкистов этот показатель будет выше, чем 1, ибо игрок приносит пользу в бою. Если этот показатель меньше, то становится понятно, что чаще всего не игрок тащит сражение, а команда тащит игрока. Но если на аккаунте больше всего боев на ЛТ, соотношения не будут объективно показывать эффективность танкиста.
Особенности расширенной статистики на нашем сайте
Статистика встретит вас таким окном, в котором нужно указать свой игровой никнейм:
Откроется главное окно статистики, в котором можно увидеть три рейтинга, а также другую информацию, например, винрейт, количество боев, полученный дамаг и.т.д. Благодаря этому можно оценить успешность любого игрока.
Интересная особенность нашей статистики в том, что можно увидеть сколько всего времени было потрачено на все сражения. Данные приблизительные, для расчета была взята средняя продолжительность боя (учитывалось больше двух миллионов сражений).
Вы задумывались над тем, сколько раз видели щелкающий таймер перед началом боя? В нашей статистике можно посмотреть, сколько в итоге времени вы потратили на щелчки таймера. И да, будьте осторожны, правда просто поражает, например, на демонстрационном аккаунте отсчет занял почти пять дней. Невероятно много, верно?