Http
Содержание:
HTTP-сервис «ОписанияТоваров»
HTTP-сервис «ОписанияТоваров» предназначен для получения и редактирования информации о товарах. Он написан в RPC (Remote Procedure Call) стиле, похожем на SOAP. В качестве дополнительного условия также предположим, что заказчик, для которого мы разрабатываем конфигурацию, потребовал предусмотреть наличие нескольких версий API где-то в будущем.
Обращение к сервису выполняется при помощи запросов с использование метода POST к URL следующего вида:
http://localhost:8090/Platform8Demo/hs/ProductDescriptions/v1/SetDescription?Article=Kol67
Рассмотрим, из чего состоит путь:
- http://localhost:8090/Platform8Demo/ — путь публикации информационной базы,
- hs – обязательный сегмент пути, сообщающий серверу, что будет происходить работа с http-сервисами,
- ProductDescriptions –корневой URL http-сервиса,
- v1 – идентификатор версии. В рассматриваемой реализации всегда v1,
- SetDescription — имя метода. В данном случае – установка описания товара. Для получения описания товара предусмотрен метод GetDescription,
- ?Article=Kol67 – строка с параметрами запроса. В общем виде выглядит как «?Параметр1=Значений1&Параметр2=Значение2& Параметр3=Значение3» и т.д. В нашем случае единственный параметр это артикул товара.
Испытаем наш сервис. К сожалению, это нельзя сделать из браузера (браузер, если не предпринять дополнительных усилий, отправляет запрос с использованием метода GET), поэтому мы воспользуемся бесплатной программой Fiddler (http://www.telerik.com/fiddler). Для создания запроса вручную достаточно перейти на вкладку Composer.
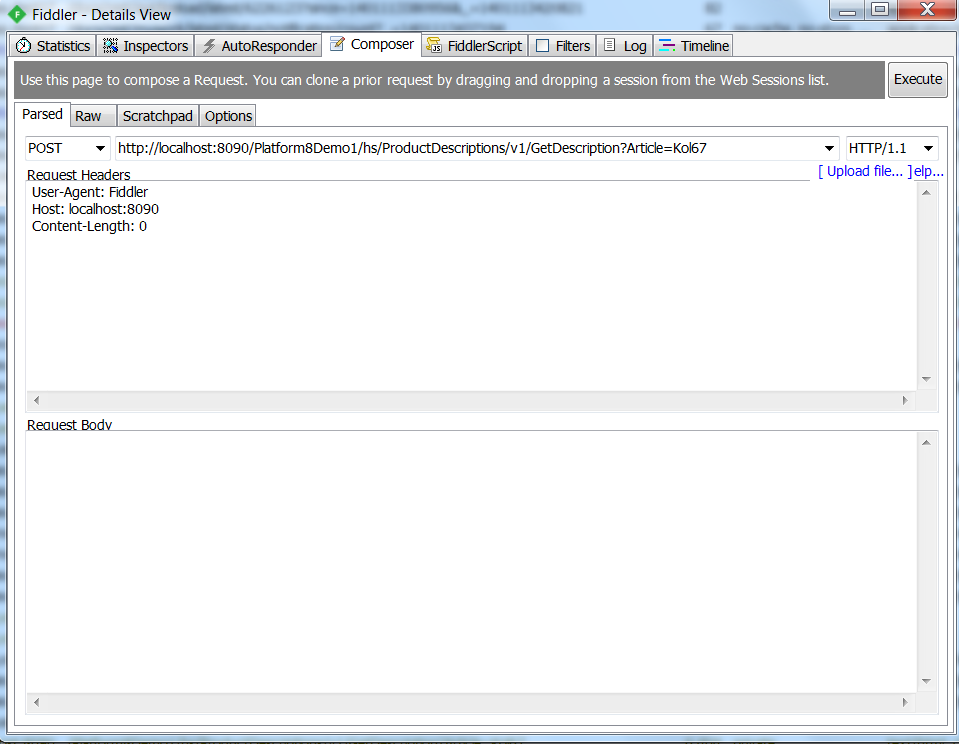
В результате выполнения запроса на вкладке Inspectors можно будет увидеть примерно следующее (в верхней части экрана – выполненный запрос, в нижней — ответ сервера):

Видно, что сервер передал описание товара в формате html.
Рассмотрим, как реализован сервис. Объект метаданных HTTP-сервиса имеет единственный дочерний шаблон URL, в котором прописан следующий шаблон:
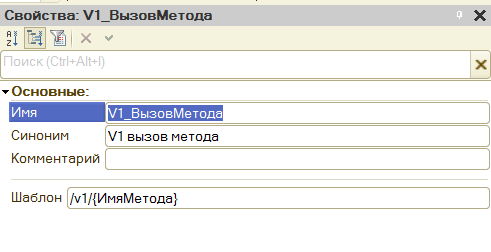
Т.к. у нас пока нет разных версий сервиса, сегмент с номером версии фиксирован, а вот второй сегмент может принимать разные значения, соответствующие именам методов. В коде получение имени метода выглядит следующим образом:
ИмяМетода = Запрос.ПараметрыURL"ИмяМетода";
Если ИмяМетода = "SetDescription" Тогда
ИначеЕсли ИмяМетода = "GetDescription" Тогда
Иначе
Ответ = Новый HTTPСервисОтвет(404);
Ответ.УстановитьТелоИзСтроки("Неизвестное имя метода");
КонецЕсли;
Обращаем внимание, что коллекция «ПараметрыURL» запроса содержит единственное значение – согласно количеству сегментов, которые могут принимать разные значение. Аналогично извлекается артикул, только используется свойство «ПараметрыЗапроса», а не «ПараметрыURL»
Аналогично извлекается артикул, только используется свойство «ПараметрыЗапроса», а не «ПараметрыURL».
Артикул = Запрос.ПараметрыЗапроса.Получить("Article");
Если Артикул = Неопределено Тогда
Ответ = Новый HTTPСервисОтвет(400);
Ответ.УстановитьТелоИзСтроки("Не задан параметр Article");
Возврат Ответ;
КонецЕсли;
Для возврата описания товара мы устанавливаем тело запроса:
ИначеЕсли ИмяМетода = "GetDescription" Тогда Ответ = Новый HTTPСервисОтвет(200); Ответ.УстановитьТелоИзСтроки(Товар.Описание); Ответ.Заголовки"Content-Type" = "text/html";
Аналогично, для установки описания товара мы получаем его из запроса:
Если ИмяМетода = "SetDescription" Тогда
ТипСодержимого = Запрос.Заголовки.Получить("Content-Type");
Если ТипСодержимого <> "text/html" И ТипСодержимого <> "text/plain" Тогда
// Сообщаем клиенту, что не поддерживаем такой тип содержимого
Ответ = Новый HTTPСервисОтвет(415);
Иначе
Товар.Описание = Запрос.ПолучитьТелоКакСтроку();
Товар.Записать();
Ответ = Новый HTTPСервисОтвет(204);
КонецЕсли;
При установке описания из тела запроса мы проводим минимальную проверку корректности того, что прислал нам клиент, в данном случае – только типа содержимого, изучая заголовок «Content-type».
Для того чтобы протестировать установку тела запроса достаточно заполнить его в Fiddler:

2 Метод GET
Напишем наш запрос.
GET http://www.site.ru/news.html HTTP/1.0\r\n Host: www.site.ru\r\n Referer: http://www.site.ru/index.html\r\n Cookie: income=1\r\n \r\n
Данный запрос говорит нам о том, что мы хотим получить содержимое страницы по адресу http://www.site.ru/news.html, использую метод GET. Поле Host говорит о том, что данная страница находится на сервере www.site.ru, поле Referer говорит о том, что за новостями мы пришли с главной страницы сайта, а поле Cookie говорит о том, что нам была присвоена такая-то кука. Почему так важны поля Host, Referer и Сookie? Потому что нормальные программисты при создании динамических сайтов проверяют данные поля, которые появляются в скриптах (РНР в том числе) в виде переменных. Для чего это надо? Для того, например, чтобы сайт не грабили, т.е. не натравливали на него программу для автоматического скачивания, или для того, чтобы зашедший на сайт человек всегда попадал бы на него только с главной страницы и.т.д.
Теперь давайте представим, что нам надо заполнить поля формы на странице и отправить запрос из формы, пусть в данной форме будет два поля: login и password (логин и пароль),- и, мы естественно знаем логин и пароль.
GET http://www.site.ru/news.html?login=Petya%20Vasechkin&password=qq HTTP/1.0\r\n Host: www.site.ru\r\n Referer: http://www.site.ru/index.html\r\n Cookie: income=1\r\n \r\n
Логин у нас «Petya Vasechkin» Почему же мы должны писать Petya%20Vasechkin? Это из=за того, что специальные символы могут быть распознаны сервером, как признаки наличия нового параметра или конца запроса и.т.д. Поэтому существует алгоритм кодирования имен параметров и их значений, во избежание оштбочных ситуаций в запросе. Полное описание данного алгоритма можно найти здесь, а в PHP есть функции rawurlencode и rawurldecode для кодирования и декодирования соответственно. Хочу отметеить, что декодирование РНР делает сам, если в запросе были переданы закодированные параметры. На этом я закону первую главу знакомства c протоколом HTTP. В следуючей главе мы рассмотрим построение запросов типа POST (в переводе с английского — «отправить»), что будет гораздо интереснее, т.к. именно данный тип запросов используется при отправке данных из HTML форм.
Уровни, глубина, прародители, циклы и аналоги запросом Промо
В продолжение публикации «Транзитивное замыкание запросом» [http://infostart.ru/public/158512/] добавлены другие варианты использования того же приема. Приведены запросы для быстрого определения уровней всех элементов справочника, максимальной глубины справочника, прародителей произвольных элементов справочника, запрос для быстрого определения циклов (на примере справочника спецификаций «1С:Управление производственным предприятием») и определения множеств аналогов номенклатуры (также на примере конфигурации «1С:Управление производственным предприятием»).
1 стартмани
Как работает HTTP, и зачем нам это знать
Программировать на PHP можно и без знания протокола HTTP, но есть ряд ситуаций, когда для решения задач нужно знать, как именно работает веб-сервер. Ведь PHP — это, в первую очередь, серверный язык программирования.
Протокол HTTP очень прост и состоит, по сути, из двух частей:
- Заголовков запроса/ответа;
- Тела запроса/ответа.
Сначала идёт список заголовков, затем пустая строка, а затем (если есть) тело запроса/ответа.
И клиент, и сервер могут посылать друг другу заголовки и тело ответа, но в случае с клиентом доступные заголовки будут одни, а с сервером — другие. Рассмотрим пошагово, как будет выглядеть работа по протоколу HTTP в случае, когда пользователь хочет загрузить главную страницу социальной сети «Вконтакте».
1. Браузер пользователя устанавливает соединение с сервером vk.com и отправляет следующий запрос:
GET / HTTP/1.1 Host: vk.com
2. Сервер принимает запрос и отправляет ответ:
3. Браузер принимает ответ и показывает готовую страницу
Больше всего нам интересен самый первый шаг, где браузер инициирует запрос к серверу vk.com
Рассмотрим подробнее, что там происходит. Первая строка запроса определяет несколько важных параметров, а именно:
- Метод, которым будет запрошен контент;
- Адрес страницы;
- Версию протокола.
— это метод (глагол), который мы применяем для доступа к указанной странице. является самым часто используемым методом, потому что он говорит серверу о том, что клиент всего лишь хочет прочитать указанный документ. Но помимо есть и другие методы, один из них мы рассмотрим уже в следующем разделе.
После метода идет указание на адрес страницы — URI (универсальный идентификатор ресурса). В нашем случае мы запрашиваем главную страницу сайта, поэтому используется просто слэш — .
Последним в этой строке идет версия протокола и почти всегда это будет
После строки с указанием основных параметров всегда следует перечисление заголовков, которые передают серверу дополнительную полезную информацию: название и версию браузера, язык, кодировку, параметры кэширования и так далее.
Среди всех этих заголовков, которые передаются при каждом запросе, есть один обязательный и самый важный — это заголовок . Он определяет адрес домена, который запрашивает браузер клиента.
Сервер, получив запрос, ищет у себя сайт с доменом из заголовка , а также указанную страницу.
Если запрошенный сайт и страница найдены, клиенту отправляется ответ:
Такой ответ означает, что всё хорошо, документ найден и будет отправлен клиенту. Если говорить более обобщённо, стартовая строка ответа имеет следующую структуру:
Больше всего здесь интересен именно код состояния, он же код ответа сервера.
В этом примере код ответа — 200, что означает: сервер работает, документ найден и будет передан клиенту. Но не всегда всё идет гладко.
Например, запрошенный документ может отсутствовать или сервер будет перегружен, в таком случае клиент не получит контент, а код ответа будет отличным от 200.
- 404 — если сервер доступен, но запрошённый документ не найден;
- 503 — если сервер не может обрабатывать запросы по техническим причинам.
Спецификация HTTP 1.1 определяет 40 различных кодов HTTP.
После стартовой строки следуют заголовки, а затем тело ответа.
HTTP-заголовки
HTTP-сообщение состоит из начальной строки, за которой следуют набор заголовков, пустая строка и некоторые данные. Начальная строка задает действие, требуемое от сервера, тип возвращаемых данных или код состояния.
HTTP-заголовки можно подразделить на три крупные категории: заголовки, посылаемые в запросе, заголовки, посылаемые в ответе, и те, которые можно включать как в запросы, так и в ответы. Заголовки запросов указывают возможности клиента, например, типы документов, которые может обработать клиент, в то время как заголовки ответов предоставляют информацию о возвращенном документе.
Заголовки запросов
К числу наиболее важных HTTP-заголовков, которые можно включать в запросы, но нельзя включать в ответы, относятся:
- Заголовок Accept
-
Это список MIME-типов, принимаемых клиентом, в формате тип/подтип. Элементы списка должны разделяться запятыми:
Accept: text/html, image/gif, */*
Элемент */* указывает, что все типы будут приняты и обработаны клиентом. Если тип запрошенного файла не может быть обработан клиентом, возвращается ошибка HTTP 406 «Not acceptable» (недопустимо).
- Заголовок From
-
Указывает адрес электронной почты в Интернете учетной записи пользователя, под которой работает клиент, направивший запрос:
From: alexerohinzzz@gmail.com
- Заголовок Referer
-
Позволяет клиенту указать адрес (URI) ресурса, из которого получен запрашиваемый URI. Этот заголовок дает возможность серверу сгенерировать список обратных ссылок на ресурсы для будущего анализа, регистрации, оптимизированного кэширования и т.д. Он также позволяет прослеживать с целью последующего исправления устаревшие или введенные с ошибками ссылки:
Referer: http://www.professorweb.ru
- Заголовок User-Agent
-
Представляет собой строку, идентифицирующую приложение-клиент (обычно браузер) и платформу, на которой оно выполняется. Общий формат имеет вид: программа/версия библиотека/версий, но это не неизменный формат:
User-Agent: Mozilla/5.0 (Windows NT 6.1) AppleWebKit/537.17 (KHTML, like Gecko) Chrome/24.0.1312.56 Safari/537.17
Эта информация может использоваться в статистических целях, для отслеживания нарушений протокола и для автоматического распознавания клиента. Она позволяет приспособить ответ так, чтобы не нарушить ограниченные возможности конкретного клиента, например неспособность поддерживать HTML-таблицы.
Заголовки ответов
В ответы могут включаться следующие заголовки:
- Заголовок Content-Type
-
Используется для указания типа данных, отправляемых получателю или, в случае метода HEAD, тип данных, который был бы отправлен в ответ на запрос GET:
Content-Type: text/html
- Заголовок Expires
-
Представляет собой момент времени, после которого информация в документе становится недостоверной. Клиенты, использующие кэширование, в частности прокси-серверы, не должны хранить в кэше эту копию ресурса после заданного времени, если только состояние копии не было обновлено более поздним обращением к исходному серверу:
Expires: Fri, 19 Aug 2012 16:00:00 GMT
- Заголовок Location
-
Определяет точное расположение другого ресурса, к которому может быть перенаправлен клиент. Если это значение представляет собой полный URL, сервер возвращает клиенту «redirect» для непосредственного извлечения указанного объекта:
Location: http://www.samplesite.com
Если ссылка на другой файл относится к серверу, должен указываться частичный URL.
- Заголовок Server
-
Содержит информацию о программном обеспечении, используемом исходным сервером для обработки запроса:
Server: Microsoft-IIS/7.0
Общие заголовки
Несколько заголовков могут включаться как в запрос, так и в ответ, например:
- Заголовок Date
-
Используется для установки даты и времени создания сообщения:
Date: Tue, 16 Aug 2012 18:12:31 GMT
- Заголовок Connection
-
В НТТР/1.0 мы могли использовать в запросе заголовок Connection, указывая, что хотим сохранить соединение после отправки ответа. Теперь такое поведение принято по умолчанию, и в HTTP/1.1 можно использовать заголовок Connection, чтобы указать, что постоянное соединение не нужно:
Connection: close
Работа со схемой запроса Промо
Стандартом взаимодействия с реляционной базой данных стал язык SQL. Приемником SQL в 1С является язык запросов. Язык запросов, также как и SQL, является структурированным. Составляющие структуры запроса отвечают на разные вопросы о том, какие данные требуется получить и какие манипуляции с множествами данных необходимо произвести при получении. В простых случаях текст запроса можно написать вручную, однако в сложных случаях, а также при программном формировании, — лучше воспользоваться объектной моделью запроса и использовать объект «Схема запроса». В статье дается описание объектной модели и особенностей работы с ней, а также приводится решение, упрощающее взаимодействие с объектом «Схема запроса».
1 стартмани
POST Method
The POST method is used when you want to send some data to the server, for example, file update, form data, etc. The following example makes use of POST method to send a form data to the server, which will be processed by a process.cgi and finally a response will be returned:
POST /cgi-bin/process.cgi HTTP/1.1 User-Agent: Mozilla/4.0 (compatible; MSIE5.01; Windows NT) Host: www.tutorialspoint.com Content-Type: text/xml; charset=utf-8 Content-Length: 88 Accept-Language: en-us Accept-Encoding: gzip, deflate Connection: Keep-Alive
<?xml version="1.0" encoding="utf-8"?> <string xmlns="http://clearforest.com/">string</string>
The server side script process.cgi processes the passed data and sends the following response:
HTTP/1.1 200 OK Date: Mon, 27 Jul 2009 12:28:53 GMT Server: Apache/2.2.14 (Win32) Last-Modified: Wed, 22 Jul 2009 19:15:56 GMT ETag: "34aa387-d-1568eb00" Vary: Authorization,Accept Accept-Ranges: bytes Content-Length: 88 Content-Type: text/html Connection: Closed
<html> <body> <h1>Request Processed Successfully</h1> </body> </html>
HTTP DELETE
As the name applies, DELETE APIs are used to delete resources (identified by the Request-URI).
A successful response of DELETE requests SHOULD be HTTP response if the response includes an entity describing the status, if the action has been queued, or if the action has been performed but the response does not include an entity.
DELETE operations are idempotent. If you DELETE a resource, it’s removed from the collection of resources. Repeatedly calling DELETE API on that resource will not change the outcome – however, calling DELETE on a resource a second time will return a 404 (NOT FOUND) since it was already removed. Some may argue that it makes the DELETE method non-idempotent. It’s a matter of discussion and personal opinion.
If the request passes through a cache and the Request-URI identifies one or more currently cached entities, those entries SHOULD be treated as stale. Responses to this method are not cacheable.
Example request URIs
- HTTP DELETE http://www.appdomain.com/users/123
- HTTP DELETE http://www.appdomain.com/users/123/accounts/456
OPTIONS Method
The OPTIONS method is used by the client to find out the HTTP methods and other options supported by a web server. The client can specify a URL for the OPTIONS method, or an asterisk (*) to refer to the entire server. The following example requests a list of methods supported by a web server running on tutorialspoint.com:
OPTIONS * HTTP/1.1 User-Agent: Mozilla/4.0 (compatible; MSIE5.01; Windows NT)
The server will send an information based on the current configuration of the server, for example:
HTTP/1.1 200 OK Date: Mon, 27 Jul 2009 12:28:53 GMT Server: Apache/2.2.14 (Win32) Allow: GET,HEAD,POST,OPTIONS,TRACE Content-Type: httpd/unix-directory
HEAD Method
The HEAD method is functionally similar to GET, except that the server replies with a response line and headers, but no entity-body. The following example makes use of HEAD method to fetch header information about hello.htm:
HEAD /hello.htm HTTP/1.1 User-Agent: Mozilla/4.0 (compatible; MSIE5.01; Windows NT) Host: www.tutorialspoint.com Accept-Language: en-us Accept-Encoding: gzip, deflate Connection: Keep-Alive
The server response against the above HEAD request will be as follows:
HTTP/1.1 200 OK Date: Mon, 27 Jul 2009 12:28:53 GMT Server: Apache/2.2.14 (Win32) Last-Modified: Wed, 22 Jul 2009 19:15:56 GMT ETag: "34aa387-d-1568eb00" Vary: Authorization,Accept Accept-Ranges: bytes Content-Length: 88 Content-Type: text/html Connection: Closed
You can notice that here server the does not send any data after header.
Implement HTTP client in Console application
Before proceeding, let’s clarify some basic concepts. What is the classic example of HTTP client? Yes, our browser. The browser knows very well how to form a HTTP request. It does not matter which kind of request it is. It set header information (not one header, many are there, like time-date, preferred data type) set host address and proper HTTP protocol type and send it to a destination, that happens behind the cenes. But in this example we will implement it from scratch (not from scratch exactly, because we will be using the Httpclient class of the .NET class library). Have a look at the following example.
- using System;
- using System.Collections.Generic;
- using System.Linq;
- using System.Text;
- using System.Threading.Tasks;
- using System.Net.Http;
- using System.Net.Http.Headers;
- namespace HttpClientAPP
- {
- class Program
- {
- staticvoid Main(string[] args)
- {
- HttpClient client = new HttpClient();
- client.BaseAddress = new Uri(«http://localhost:11129/»);
- client.DefaultRequestHeaders.Accept.Add(new MediaTypeWithQualityHeaderValue(«application/json»));
- HttpResponseMessage response = client.GetAsync(«api/Values»).Result;
- if (response.IsSuccessStatusCode)
- {
- var products = response.Content.ReadAsStringAsync().Result;
- }
- else
- {
- Console.WriteLine(«{0} ({1})», (int)response.StatusCode, response.ReasonPhrase);
- }
- }
- }
- }
Here we have set a base address that is nothing but the RESTful URL of our service application. Then we are requesting the server to return data in JSON format by setting the expected content type header. Then we are reading the response information asynchronously.
In the output we are getting data in JSON format, which is what is expected.
Cheers, we have created our first HTTP client that has made a GET request to the Web API. That’s fine and cool, now we are interested in seeing the request and response message that we made at the time of the API call and that we got in response. Here is the sample implementation for that.
- using System;
- using System.Collections.Generic;
- using System.Linq;
- using System.Text;
- using System.Threading.Tasks;
- using System.Net.Http;
- using System.Net.Http.Headers;
- namespace HttpClientAPP
- {
- class Program
- {
- staticvoid Main(string[] args)
- {
- HttpClient client = new HttpClient();
- client.BaseAddress = new Uri(«http://localhost:11129/»);
- client.DefaultRequestHeaders.Accept.Add(new MediaTypeWithQualityHeaderValue(«application/json»));
- HttpResponseMessage response = client.GetAsync(«api/Values»).Result;
- if (response.IsSuccessStatusCode)
- {
- Console.WriteLine(«Request Message Information:- \n\n» + response.RequestMessage + «\n»);
- Console.WriteLine(«Response Message Header \n\n» + response.Content.Headers + «\n»);
- }
- else
- {
- Console.WriteLine(«{0} ({1})», (int)response.StatusCode, response.ReasonPhrase);
- }
- Console.ReadLine();
- }
- }
- }
The green box shows the request message format that out HttpClient class has formed for us. We are seeing that the request type is GET and the HTTP protocol version is 1.1. In the header part only one header information is there. The request is expecting JSON data in the body of the response message.
The red box shows the response message.
Резюме¶
Протокол HTTP это:
- однонаправленный (запрос/ответ)
- текстовый протокол
- не хранит состояния
- работает на сетевом уровне только через TCP
- может передавать любые данные
- используется не только в браузерах
- обслуживает львиную долю Интернет трафика
Достоинства
-
Простота. Протокол HTTP позволяет легко создавать необходимые клиентские
приложения. -
Расширяемость. Исходные возможности протокола можно расширить,
внедрив свои собственные заголовки, с помощью которых можно добиться
необходимой функциональности, которая может потребоваться при решении
специфических задач. Совместимость с другими серверами и клиентами от
этого никак не пострадает: они будут игнорировать неизвестные им
заголовки. -
Распространённость. Протокол поддерживается в качестве клиента
многими программами и есть возможность выбирать среди хостинговых
компаний с серверами HTTP. По этой причине протокол широко используют для
решения различных задач. Кроме этого, существует документация на многих
языках, что существенно облегчает работу с протоколом.
Недостатки
-
Избыточность передаваемой информации, и как следствие, большой размер
сообщений по сравнению с передачей двоичных данных. Это нивелируется
внедрением кэширования на стороне клиента, компрессии передаваемых данных
от сервера. Также улучшает ситуацию использование прокси-серверов,
позволяющих передавать информацию клиенту с наиболее близкого сервера,
diff-кодирование, благодаря которому клиенту передается не весь объем
данных, а только измененная их часть. -
Отсутствие навигации. У протокола отсутствую средства навигации среди
ресурсов сервера. Клиент не может, как в FTP запросить список доступных
файлов. Протокол предполагает, что пользователю уже известен URI
интересующего его ресурса.Эта особенность достаточно прозрачна для пользователя, но неудобна для
приложения, которому это иногда требуется. Разработчиками это решается
вводом дополнительных компонентов. Со стороны клиента это может быть
например веб-паук, проходящий по всем гиперссылкам документа, и
собирающий данную информации. Со стороны сервера это например, карта
сайта—специальная страница с перечислением доступных клиенту ресурсов.Карта сайта может использоваться как пользователем, так и
роботами-пауками поисковых систем, уменьшая для них глубину
просмотра—минимально необходимое количество переходов с главной страницы.
Аналогичную функцию выполняют и файлы sitemap, но только для
приложений. Данная проблема полностью решена в протоколе более высокго
уровня WebDAV с помощью добавленного метода PROPFIND, который
позволяет получить не только дерево каталогов, но и список параметров
каждого ресурса. -
Отсутствие поддержки распределённости. Изначально протокол HTTP
разрабатывался для решения типичных бытовых задач, где само по себе время
обработки запроса должно занимать незначительное время или вовсе не
приниматься в расчёт. Однако со временем стало очевидно, что при
промышленном использовании с применением распределённых вычислений при
высоких нагрузках на сервер протокол HTTP оказывается непригоден. В
связи с этим с 1998 году был предложен альтернативный протокол HTTP-NG (англ. HTTP Next
Generation), но этот протокол до сих пор находится на стадии разработки.