Введение в работу с библиотекой requests в python
Содержание:
JSON
JSON (JavaScript Object Notation) is a lightweight
data-interchange format. It is easy for humans to read and write and for
machines to parse and generate.
JSON data is a collection of key/value pairs; in Python, it is realized by a dictionary.
Read JSON
In the first example, we read JSON data from a PHP script.
send_json.php
<?php
$data = ;
header('Content-Type: application/json');
echo json_encode($data);
The PHP script sends JSON data. It uses the
function to do the job.
read_json.py
#!/usr/bin/env python3
import requests as req
resp = req.get("http://localhost/send_json.php")
print(resp.json())
The reads JSON data sent by the PHP script.
print(resp.json())
The method returns the json-encoded
content of a response, if any.
$ ./read_json.py
{'age': 17, 'name': 'Jane'}
This is the output of the example.
Send JSON
Next, we send JSON data to a PHP script from a Python script.
parse_json.php
<?php
$data = file_get_contents("php://input");
$json = json_decode($data , true);
foreach ($json as $key => $value) {
if (!is_array($value)) {
echo "The $key is $value\n";
} else {
foreach ($value as $key => $val) {
echo "The $key is $value\n";
}
}
}
This PHP script reads JSON data and sends back a message with
the parsed values.
send_json.py
#!/usr/bin/env python3
import requests as req
data = {'name': 'Jane', 'age': 17}
resp = req.post("http://localhost/parse_json.php", json=data)
print(resp.text)
This script sends JSON data to the PHP application and
reads its response.
data = {'name': 'Jane', 'age': 17}
This is the data to be sent.
resp = req.post("http://localhost/parse_json.php", json=data)
The dictionary containing JSON data is passed to the
parameter.
$ ./send_json.py The name is Jane The age is 17
This is the example output.
Python requests head method
The method retrieves document headers.
The headers consist of fields, including date, server, content type,
or last modification time.
head_request.py
#!/usr/bin/env python3
import requests as req
resp = req.head("http://www.webcode.me")
print("Server: " + resp.headers)
print("Last modified: " + resp.headers)
print("Content type: " + resp.headers)
The example prints the server, last modification time, and content type
of the web page.
$ ./head_request.py Server: nginx/1.6.2 Last modified: Sat, 20 Jul 2019 11:49:25 GMT Content type: text/html
This is the output of the program.
Setting base URLs
Suppose you are only using one API hosted at api.org. You’ll end up repeating
the protocol and domain for every http call:
requests.get('https://api.org/list/')
requests.get('https://api.org/list/3/item')
You can save yourself some typing by using
.
This allows you to specify the base url for the HTTP client and to only specify
the resource path at the time of the request.
from requests_toolbelt import sessions
http = sessions.BaseUrlSession(base_url="https://api.org")
http.get("/list")
http.get("/list/item")
Note that the requests toolbelt isn’t
included in the default requests installation, so you’ll have to install it
separately.
Response Headers¶
We can view the server’s response headers using a Python dictionary:
>>> r.headers
{
'content-encoding': 'gzip',
'transfer-encoding': 'chunked',
'connection': 'close',
'server': 'nginx/1.0.4',
'x-runtime': '148ms',
'etag': '"e1ca502697e5c9317743dc078f67693f"',
'content-type': 'application/json'
}
The dictionary is special, though: it’s made just for HTTP headers. According to
, HTTP Header names
are case-insensitive.
So, we can access the headers using any capitalization we want:
>>> r.headers'Content-Type'
'application/json'
>>> r.headers.get('content-type')
'application/json'
It is also special in that the server could have sent the same header multiple
times with different values, but requests combines them so they can be
represented in the dictionary within a single mapping, as per
:
Коды состояния
Прежде всего мы проверим код состояния. Коды HTTP находятся в диапазоне от 1XX до 5XX. Наверняка вы уже знакомы с кодами состояния 200, 404 и 500.
Далее мы приведем краткий обзор значений кодов состояния:
- 1XX — информация
- 2XX — успешно
- 3XX — перенаправление
- 4XX — ошибка клиента (ошибка на вашей стороне)
- 5XX — ошибка сервера (ошибка на их стороне)
Обычно при выполнении наших собственных запросов мы хотим получить коды состояния в диапазоне 200.
Библиотека Requests понимает, что коды состояния 4XX и 5XX сигнализируют об ошибках, и поэтому при возврате этих кодов состояния объекту ответа на запрос присваивается значение .
Проверив истинность ответа, вы можете убедиться, что запрос успешно обработан. Например:
script.py
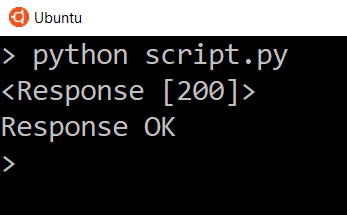
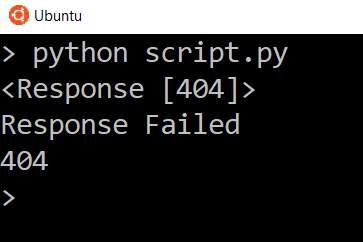
Сообщение Response Failed появится только при возврате кода состояния 400 или 500. Попробуйте заменить URL на несуществующий, чтобы увидеть ошибку ответа 404.
Чтобы посмотреть код состояния, добавьте следующую строку:
script.py
Так вы увидите код состояния и сможете сами его проверить.
Объект Response
Response — это объект для проверки результатов запроса.
Давайте сделаем тот же запрос, но на этот раз сохраним его в переменную, чтобы мы могли более подробно изучить его атрибуты и поведение:
В этом примере вы захватили значение, возвращаемое значение , которое является экземпляром Response, и сохранили его в переменной response. Название переменной может быть любым.
Код ответа HTTP
Первый кусок данных, который можно получить из ответа — код состояния (он же код ответа HTTP). Код ответа информирует вас о состоянии запроса.
Например, статус означает, что ваш запрос был успешно выполнен, а статус означает, что ресурс не найден. Есть множество других ответов сервера, которые могут дать вам информацию о том, что произошло с вашим запросом.
Используя вы можете увидеть статус, который вернул вам в ответ сервер:
вернул 200 — это значит, что запрос успешно выполнен и сервер отдал вам запрашиваемые данные.
Иногда эту информацию можно использовать в коде для принятия решений:
Если сервер возвращает 200, то программа выведет , если код ответа 400, то программа выведет .
Requests делает еще один шаг к тому, чтобы сделать это проще. Если вы используете экземпляр Response в условном выражении, то он получит значение , если код ответа между 200 и 400, и False во всех остальных случаях.
Поэтому вы можете сделать проще последний пример, переписав :
Помните, что этот метод не проверяет, что код состояния равен 200.
Причиной этого является то, что ответы с кодом в диапазоне от 200 до 400, такие как и , тоже считаются истинными, так как они дают некоторый обрабатываемый ответ.
Например, статус 204 говорит о том, что запрос был успешным, но в теле ответа нет содержимого.
Поэтому убедитесь, что вы используете этот сокращенный вид записи, только если хотите узнать был ли запрос успешен в целом. А затем обработать код состояния соответствующим образом.
Если вы не хотите проверять код ответа сервера в операторе , то вместо этого вы можете вызвать исключение, если запрос был неудачным. Это можно сделать вызвав :
Если вы используете , то HTTPError сработает только для определенных кодов состояния. Если состояние укажет на успешный запрос, то исключение не будет вызвано и программа продолжит свою работу.
Теперь вы знаете многое о том, что делать с кодом ответа от сервера. Но когда вы делаете GET-запрос, вы редко заботитесь только об ответе сервера — обычно вы хотите увидеть больше.
Далее вы узнаете как просмотреть фактические данные, которые сервер отправил в теле ответа.
Content
Ответ на Get-запрос, в теле сообщения часто содержит некую ценную информацию, известную как «полезная нагрузка» («Payload»). Используя атрибуты и методы Response, вы можете просматривать payload в разных форматах.
Чтобы увидеть содержимое ответа в байтах, используйте :
Пока дает вам доступ к необработанным байтам полезной нагрузки ответа, вы можете захотеть преобразовать их в строку с использованием кодировки символов UTF-8. Response это сделает за вас, когда вы укажите :
Поскольку для декодирования байтов в строки требуется схема кодирования, Requests будет пытаться угадать кодировку на основе заголовков ответа. Вы можете указать кодировку явно, установив перед указанием :
Если вы посмотрите на ответ, то вы увидите, что на самом деле это последовательный JSON контент. Чтобы получить словарь, вы можете взять строку, которую получили из и десериализовать ее с помощью . Однако, более простой способ сделать это — использовать .
Тип возвращаемого значения — это словарь, поэтому вы можете получить доступ к значениям в объекте по ключу.
Вы можете делать многое с кодом состояний и телом сообщений. Но если вам нужна дополнительная информация, такая как метаданные о самом ответе, то вам нужно взглянуть на заголовки ответа.
Заголовки
Заголовки ответа могут дать вам полезную информацию, такую как тип ответа и ограничение по времени, в течение которого необходимо кэшировать ответ.
Чтобы посмотреть заголовки, укажите :
возвращает похожий на словарь объект, позволяющий получить доступ к значениям объекта по ключу. Например, чтобы получить тип содержимого ответа, вы можете получить доступ к Content-Type:
Используя ключ или — вы получите одно и то же значение.
Теперь вы узнали основное о Response. Вы увидели его наиболее используемые атрибуты и методы в действии. Давайте сделаем шаг назад и посмотрим как изменяются ответы при настройке Get-запросов.
Migrating to 2.x¶
Compared with the 1.0 release, there were relatively few backwards
incompatible changes, but there are still a few issues to be aware of with
this major release.
For more details on the changes in this release including new APIs, links
to the relevant GitHub issues and some of the bug fixes, read Cory’s blog
on the subject.
API Changes
-
There were a couple changes to how Requests handles exceptions.
is now a subclass of rather than
as that more accurately categorizes the type of error.
In addition, an invalid URL escape sequence now raises a subclass of
rather than a .requests.get('http://%zz/') # raises requests.exceptions.InvalidURLLastly, exceptions caused by incorrect chunked
encoding will now raise a Requests instead. -
The proxy API has changed slightly. The scheme for a proxy URL is now
required.proxies = { "http" "10.10.1.10:3128", # use http://10.10.1.10:3128 instead } # In requests 1.x, this was legal, in requests 2.x, # this raises requests.exceptions.MissingSchema requests.get("http://example.org", proxies=proxies)
Behavioural Changes
- Keys in the dictionary are now native strings on all Python
versions, i.e. bytestrings on Python 2 and unicode on Python 3. If the
keys are not native strings (unicode on Python 2 or bytestrings on Python 3)
they will be converted to the native string type assuming UTF-8 encoding. - Values in the dictionary should always be strings. This has
been the project’s position since before 1.0 but a recent change
(since version 2.11.0) enforces this more strictly. It’s advised to avoid
passing header values as unicode when possible.
POST Multiple Multipart-Encoded Files¶
You can send multiple files in one request. For example, suppose you want to
upload image files to an HTML form with a multiple file field ‘images’:
<input type="file" name="images" multiple="true" required="true"/>
To do that, just set files to a list of tuples of :
>>> url = 'https://httpbin.org/post'
>>> multiple_files =
... ('images', ('foo.png', open('foo.png', 'rb'), 'image/png')),
... ('images', ('bar.png', open('bar.png', 'rb'), 'image/png'))]
>>> r = requests.post(url, files=multiple_files)
>>> r.text
{
...
'files': {'images': 'data:image/png;base64,iVBORw ....'}
'Content-Type': 'multipart/form-data; boundary=3131623adb2043caaeb5538cc7aa0b3a',
...
}
Задержка
Часто бывает нужно ограничить время ожидания ответа. Это можно сделать с помощью параметра timeout
Перейдите на
раздел — / #/ Dynamic_data / delete_delay__delay_
и изучите документацию — если делать запрос на этот url можно выставлять время, через которое
будет отправлен ответ.
Создайте файл
timeout_demo.py
следующего содержания
Задержка равна одной секунде. А ждать ответ можно до трёх секунд.
python3 timeout_demo.py
<Response >
Измените код так, чтобы ответ приходил заведомо позже чем наш таймаут в три секунды.
Задержка равна семи секундам. А ждать ответ можно по-прежнему только до трёх секунд.
python3 timeout_demo.py
Traceback (most recent call last):
File «/usr/lib/python3/dist-packages/urllib3/connectionpool.py», line 421, in _make_request
six.raise_from(e, None)
File «<string>», line 3, in raise_from
File «/usr/lib/python3/dist-packages/urllib3/connectionpool.py», line 416, in _make_request
httplib_response = conn.getresponse()
File «/usr/lib/python3.8/http/client.py», line 1347, in getresponse
response.begin()
File «/usr/lib/python3.8/http/client.py», line 307, in begin
version, status, reason = self._read_status()
File «/usr/lib/python3.8/http/client.py», line 268, in _read_status
line = str(self.fp.readline(_MAXLINE + 1), «iso-8859-1»)
File «/usr/lib/python3.8/socket.py», line 669, in readinto
return self._sock.recv_into(b)
File «/usr/lib/python3/dist-packages/urllib3/contrib/pyopenssl.py», line 326, in recv_into
raise timeout(«The read operation timed out»)
socket.timeout: The read operation timed out
During handling of the above exception, another exception occurred:
Traceback (most recent call last):
File «/usr/lib/python3/dist-packages/requests/adapters.py», line 439, in send
resp = conn.urlopen(
File «/usr/lib/python3/dist-packages/urllib3/connectionpool.py», line 719, in urlopen
retries = retries.increment(
File «/usr/lib/python3/dist-packages/urllib3/util/retry.py», line 400, in increment
raise six.reraise(type(error), error, _stacktrace)
File «/usr/lib/python3/dist-packages/six.py», line 703, in reraise
raise value
File «/usr/lib/python3/dist-packages/urllib3/connectionpool.py», line 665, in urlopen
httplib_response = self._make_request(
File «/usr/lib/python3/dist-packages/urllib3/connectionpool.py», line 423, in _make_request
self._raise_timeout(err=e, url=url, timeout_value=read_timeout)
File «/usr/lib/python3/dist-packages/urllib3/connectionpool.py», line 330, in _raise_timeout
raise ReadTimeoutError(
urllib3.exceptions.ReadTimeoutError: HTTPSConnectionPool(host=’httpbin.org’, port=443): Read timed out. (read timeout=3)
During handling of the above exception, another exception occurred:
Traceback (most recent call last):
File «timeout_demo.py», line 4, in <module>
r = requests.get(‘https://httpbin.org/delay/7’, timeout=3)
File «/usr/lib/python3/dist-packages/requests/api.py», line 75, in get
return request(‘get’, url, params=params, **kwargs)
File «/usr/lib/python3/dist-packages/requests/api.py», line 60, in request
return session.request(method=method, url=url, **kwargs)
File «/usr/lib/python3/dist-packages/requests/sessions.py», line 533, in request
resp = self.send(prep, **send_kwargs)
File «/usr/lib/python3/dist-packages/requests/sessions.py», line 646, in send
r = adapter.send(request, **kwargs)
File «/usr/lib/python3/dist-packages/requests/adapters.py», line 529, in send
raise ReadTimeout(e, request=request)
requests.exceptions.ReadTimeout: HTTPSConnectionPool(host=’httpbin.org’, port=443): Read timed out. (read timeout=3)
Если такая обработка исключений не вызывает у вас восторга — измените код используя try except
python3 timeout_demo.py
Response is taking too long.
Quick Overview of HTTP Requests
HTTP requests are how the web works. Every time you navigate to a web page, your browser makes multiple requests to the web page’s server. The server then responds with all the data necessary to render the page, and your browser then actually renders the page so you can see it.
The generic process is this: a client (like a browser or Python script using Requests) will send some data to a URL, and then the server located at the URL will read the data, decide what to do with it, and return a response to the client. Finally, the client can decide what to do with the data in the response.
Part of the data the client sends in a request is the request method. Some common request methods are GET, POST, and PUT. GET requests are normally for reading data only without making a change to something, while POST and PUT requests generally are for modifying data on the server. So for example, the Stripe API allows you to use POST requests to create a new charge so a user can purchase something from your app.
This article will cover GET requests only because we won’t be modifying any data on a server.
When sending a request from a Python script or inside a web app, you, the developer, gets to decide what gets sent in each request and what to do with the response. So let’s explore that by first sending a request to Scotch.io and then by using a language translation API.
Headers
Another thing you can get from the response are the headers. You can take a look at them by using the headers dictionary on the response object.

Headers are sent along with the request and returned in the response. Headers are used so both the client and the server know how to interpret the data that is being sent and received in the response/response.
We see the various headers that are returned. A lot of times you won’t need to use the header information directly, but it’s there if you need it.
The content type is usually the one you may need because it reveals the format of the data, for example HTML, JSON, PDF, text, etc. But the content type is normally handled by Requests so you can easily access the data that gets returned.
Streaming Requests¶
With you can easily
iterate over streaming APIs such as the Twitter Streaming
API. Simply
set to and iterate over the response with
:
import json
import requests
r = requests.get('https://httpbin.org/stream/20', stream=True)
for line in r.iter_lines():
# filter out keep-alive new lines
if line
decoded_line = line.decode('utf-8')
print(json.loads(decoded_line))
When using decode_unicode=True with
or
, you’ll want
to provide a fallback encoding in the event the server doesn’t provide one:
r = requests.get('https://httpbin.org/stream/20', stream=True)
if r.encoding is None
r.encoding = 'utf-8'
for line in r.iter_lines(decode_unicode=True):
if line
print(json.loads(line))
Производительность
При использовании , особенно в продакшене, важно учитывать влияние на производительность. Такие функции, как контроль времени ожидания, сеансы и ограничения повторных попыток, могут обеспечить вам бесперебойную работу приложения
Время ожидания
Когда вы отправляете запрос во внешнюю службу, вашей системе потребуется дождаться ответа, прежде чем двигаться дальше. Если ваше предложение слишком долго ожидает ответа — запросы к службе могут быть скопированы, пользовательский интерфейс может пострадать или фоновые задания могут зависнуть.
По умолчанию, будет ждать ответа до бесконечности, поэтому вы почти всегда должны указывать время ожидания. Чтобы установить время ожидания, используйте параметр . Тайм-аут может быть целым числом или числом с плавающей запятой, представляющим количество секунд ожидания ответа:
В первом запросе, время ожидания истекает через одну секунду. Во втором — через 3,05 секунд.
Вы также можете передать кортеж тайм-ауту. Первый элемент в кортеже является тайм-аутом соединения (время, которое позволяет установить клиенту соединение с сервером), а второй элемент — время ожидания чтения (время ожидания ответа после того, как клиент установил соединение):
Если запрос устанавливает соединение в течение 2 секунд и получает данные в течение 5 секунд после установки соединения, то ответ будет возвращен. Если время ожидания истекло — функция вызовет исключение :
Ваша программа может перехватить исключение и ответить соответствующим образом.
Объект Session
До сих пор вы имели дело с интерфейсами API высокого уровня, такими как и . Эти функции являются абстракциями над тем, что происходит когда вы делаете свои запросы. Они скрывают детали реализации, такие как управление соединениями, так что вам не нужно беспокоиться о них.
Под этими абстракциями находится класс . Если вам необходимо настроить контроль над выполнением запросов и повысить производительность вашего приложения — вам может потребоваться использовать экземпляр напрямую.
Сеансы используются для сохранения параметров в запросах. Например, если вы хотите использовать одну и ту же аутентификацию для нескольких запросов, вы можете использовать сеанс:
Каждый раз, когда вы делаете запрос в сеансе, после того, как он был инициализирован с учетными данными аутентификации, учетные данные будут сохраняться.
Первичная оптимизация производительности сессий происходит в форме постоянных соединений. Когда ваше приложение устанавливает соединение с сервером, используя , оно сохраняет это соединение в пуле с остальными соединениями. Когда ваше приложение снова подключиться к тому же серверу, оно будет повторно использовать соединение из пула, а не устанавливать новое.
Максимальное количество попыток
В случае сбоя запроса, вы можете захотеть, чтобы приложение отправило запрос повторно. Однако не делает этого за вас по умолчанию. Чтобы реализовать эту функцию, вам необходимо реализовать собственный .
Транспортные адаптеры позволяют вам определять набор конфигураций для каждой службы , с которой вы взаимодействуете. Например, вы хотите, чтобы все запросы к https://api.github.com, повторялись по три раза, прежде чем вызовется исключение . Вы должны сконструировать транспортный адаптер, установить его параметр и подключить его к существующему сеансу:
Когда вы монтируете и в — будет придерживаться этой конфигурации в каждом запросе к https://api.github.com.
Время ожидания, транспортные адаптеры и сеансы, предназначены для обеспечения эффективности вашего кода и отказоустойчивости приложения.
Transport Adapters¶
As of v1.0.0, Requests has moved to a modular internal design. Part of the
reason this was done was to implement Transport Adapters, originally
described here. Transport Adapters provide a mechanism to define interaction
methods for an HTTP service. In particular, they allow you to apply per-service
configuration.
Requests ships with a single Transport Adapter, the . This adapter provides the default Requests
interaction with HTTP and HTTPS using the powerful urllib3 library. Whenever
a Requests is initialized, one of these is
attached to the object for HTTP, and one
for HTTPS.
Requests enables users to create and use their own Transport Adapters that
provide specific functionality. Once created, a Transport Adapter can be
mounted to a Session object, along with an indication of which web services
it should apply to.
>>> s = requests.Session()
>>> s.mount('https://github.com/', MyAdapter())
The mount call registers a specific instance of a Transport Adapter to a
prefix. Once mounted, any HTTP request made using that session whose URL starts
with the given prefix will use the given Transport Adapter.
Many of the details of implementing a Transport Adapter are beyond the scope of
this documentation, but take a look at the next example for a simple SSL use-
case. For more than that, you might look at subclassing the
.
Более сложные POST запросы
Зачастую вы хотите послать некоторые данные также как это делается в HTML форме. Чтобы сделать это, просто передайте соответствующий словарь в аргументе . Ваш словарь данных в таком случае будет автоматически закодирован как HTML форма, когда будет сделан запрос:
>>> payload = {'key1': 'value1', 'key2': 'value2'}
>>> r = requests.post("http://httpbin.org/post", data=payload)
>>> print(r.text)
{ ... "form": { "key2": "value2", "key1": "value1" }, ... }
Но есть много случаев, когда вы можете захотеть отправить данные, которые не закодированы методом . Если вы передадите в запрос строку вместо словаря, то данные будут отправлены в неизменном виде. Например, API v3 GitHub принимает JSON-закодированные данные:
>>> import json url = 'https://api.github.com/some/endpoint'
>>> payload = {'some': 'data'}
>>> r = requests.post(url, data=json.dumps(payload))
Аутентификация
Аутенфикация помогает сервисам понять кто вы. Как правило, вы предоставляете свои учетные данные на сервер, передавая данные через заголовок авторизации или пользовательский заголовок, определенный службой.
Все функции запроса, которые вы видели до этого момента, предоставляют параметр , который позволяет передавать вам свои учетные данные.
Одним из примеров API, которые требует аутентификации, является GitHub’s Authenticated User API. Это конечная точка предоставляет информацию о профиле аутентифицированного пользователя. Чтобы сделать запрос к Authenticated User API, вы можете передать свое имя пользователя и пароль в кортеже :
Запрос будет успешно выполнен, если учетные данные, которые вы передали в кортеже верны. Если вы попробуете сделать запрос не указав учетные данные, то получите в ответ от сервера код состояния .
Когда вы передаете имя пользователя и пароль в кортеже параметру , применяет учетные данные с использованием базовой схемы аутентификации доступа HTTP.
Таким образом, вы можете сделать тот же запрос, передав учетные данные, используя :
Вам не обязательно использовать , вы можете аутентифицироваться и другим способом. из коробки предоставляют и другие методы аутентификации, такие как и .
Вы даже можете использовать свой собственный механизм аутентификации. Для этого, вы должны создать подкласс , затем внедрить :
Здесь ваш пользовательский механизм получает токен, а затем включает этот токен в заголовок вашего запроса.
Плохие механизмы проверки подлинности могут привести к уязвимостям в безопасности. Поэтому, если вашему сервису, по какой-либо причине не требуется настраиваемый механизм проверки подлинности, то лучше использовать готовые схемы проверки подлинности, такие как или .
Пока вы думаете о безопасности, давайте рассмотрим работу с SSL-сертификатами в библиотеке .