Регрессионный анализ в microsoft excel
Содержание:
Расчет коэффициента корреляции
Теперь давайте попробуем посчитать коэффициент корреляции на конкретном примере. Имеем таблицу, в которой помесячно расписана в отдельных колонках затрата на рекламу и величина продаж. Нам предстоит выяснить степень зависимости количества продаж от суммы денежных средств, которая была потрачена на рекламу.
Способ 1: определение корреляции через Мастер функций
Одним из способов, с помощью которого можно провести корреляционный анализ, является использование функции КОРРЕЛ. Сама функция имеет общий вид КОРРЕЛ(массив1;массив2).
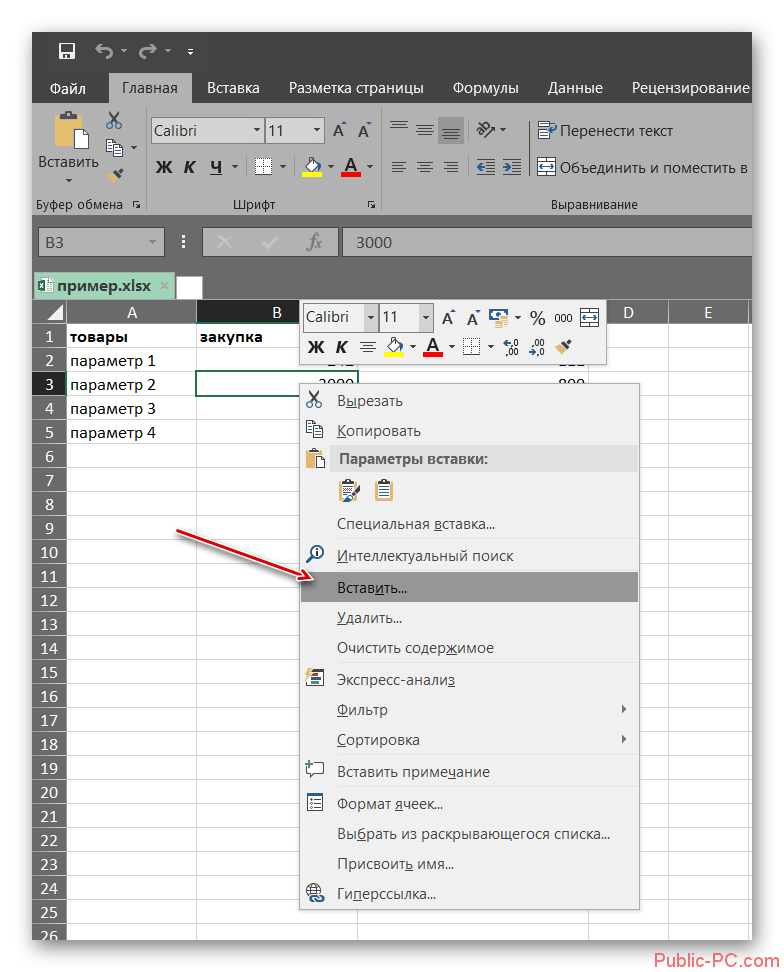
- Выделяем ячейку, в которой должен выводиться результат расчета. Кликаем по кнопке «Вставить функцию», которая размещается слева от строки формул.
В списке, который представлен в окне Мастера функций, ищем и выделяем функцию КОРРЕЛ. Жмем на кнопку «OK».
Открывается окно аргументов функции. В поле «Массив1» вводим координаты диапазона ячеек одного из значений, зависимость которого следует определить. В нашем случае это будут значения в колонке «Величина продаж». Для того, чтобы внести адрес массива в поле, просто выделяем все ячейки с данными в вышеуказанном столбце.
В поле «Массив2» нужно внести координаты второго столбца. У нас это затраты на рекламу. Точно так же, как и в предыдущем случае, заносим данные в поле.
Жмем на кнопку «OK».
Как видим, коэффициент корреляции в виде числа появляется в заранее выбранной нами ячейке. В данном случае он равен 0,97, что является очень высоким признаком зависимости одной величины от другой.
Способ 2: вычисление корреляции с помощью пакета анализа
Кроме того, корреляцию можно вычислить с помощью одного из инструментов, который представлен в пакете анализа. Но прежде нам нужно этот инструмент активировать.
- Переходим во вкладку «Файл».
В открывшемся окне перемещаемся в раздел «Параметры».
Далее переходим в пункт «Надстройки».
В нижней части следующего окна в разделе «Управление» переставляем переключатель в позицию «Надстройки Excel», если он находится в другом положении. Жмем на кнопку «OK».
В окне надстроек устанавливаем галочку около пункта «Пакет анализа». Жмем на кнопку «OK».
После этого пакет анализа активирован. Переходим во вкладку «Данные». Как видим, тут на ленте появляется новый блок инструментов – «Анализ». Жмем на кнопку «Анализ данных», которая расположена в нем.
Открывается список с различными вариантами анализа данных. Выбираем пункт «Корреляция». Кликаем по кнопке «OK».
Открывается окно с параметрами корреляционного анализа. В отличие от предыдущего способа, в поле «Входной интервал» мы вводим интервал не каждого столбца отдельно, а всех столбцов, которые участвуют в анализе. В нашем случае это данные в столбцах «Затраты на рекламу» и «Величина продаж».
Параметр «Группирование» оставляем без изменений – «По столбцам», так как у нас группы данных разбиты именно на два столбца. Если бы они были разбиты построчно, то тогда следовало бы переставить переключатель в позицию «По строкам».
В параметрах вывода по умолчанию установлен пункт «Новый рабочий лист», то есть, данные будут выводиться на другом листе. Можно изменить место, переставив переключатель. Это может быть текущий лист (тогда вы должны будете указать координаты ячеек вывода информации) или новая рабочая книга (файл).
Когда все настройки установлены, жмем на кнопку «OK».
Так как место вывода результатов анализа было оставлено по умолчанию, мы перемещаемся на новый лист. Как видим, тут указан коэффициент корреляции. Естественно, он тот же, что и при использовании первого способа – 0,97. Это объясняется тем, что оба варианта выполняют одни и те же вычисления, просто произвести их можно разными способами.
Как видим, приложение Эксель предлагает сразу два способа корреляционного анализа. Результат вычислений, если вы все сделаете правильно, будет полностью идентичным. Но, каждый пользователь может выбрать более удобный для него вариант осуществления расчета.
Опишите, что у вас не получилось.
Наши специалисты постараются ответить максимально быстро.
Анализ результатов
Чтобы решить, адекватно ли полученное уравнения линейной регрессии, используются коэффициенты множественной корреляции (КМК) и детерминации, а также критерий Фишера и критерий Стьюдента. В таблице «Эксель» с результатами регрессии они выступают под названиями множественный R, R-квадрат, F-статистика и t-статистика соответственно.
КМК R дает возможность оценить тесноту вероятностной связи между независимой и зависимой переменными. Ее высокое значение свидетельствует о достаточно сильной связи между переменными «Номер месяца» и «Цена товара N в рублях за 1 тонну». Однако, характер этой связи остается неизвестным.
Квадрат коэффициента детерминации R 2 (RI) представляет собой числовую характеристику доли общего разброса и показывает, разброс какой части экспериментальных данных, т.е. значений зависимой переменной соответствует уравнению линейной регрессии. В рассматриваемой задаче эта величина равна 84,8%, т. е. статистические данные с высокой степенью точности описываются полученным УР.
F-статистика, называемая также критерием Фишера, используется для оценки значимости линейной зависимости, опровергая или подтверждая гипотезу о ее существовании.
(критерий Стьюдента) помогает оценивать значимость коэффициента при неизвестной либо свободного члена линейной зависимости. Если значение t-критерия > t кр, то гипотеза о незначимости свободного члена линейного уравнения отвергается.
В рассматриваемой задаче для свободного члена посредством инструментов «Эксель» было получено, что t=169,20903, а p=2,89Е-12, т. е. имеем нулевую вероятность того, что будет отвергнута верная гипотеза о незначимости свободного члена. Для коэффициента при неизвестной t=5,79405, а p=0,001158. Иными словами вероятность того, что будет отвергнута верная гипотеза о незначимости коэффициента при неизвестной, равна 0,12%.
Таким образом, можно утверждать, что полученное уравнение линейной регрессии адекватно.
Основные задачи и виды регрессии
Регрессия представляет собой зависимость между заданными переменными, за счет чего можно определить прогноз будущего поведения данных переменных. Переменные — это различные периодические явления, включая и поведение человека. Такой анализ программы Excel применяется для того, чтобы проанализировать воздействие на конкретную зависимую переменную значений одной или некоторым количеством переменных.
К примеру, на продажи в магазине влияет несколько факторов, включая ассортимент, цены и место локализации магазина. Благодаря регрессии в Excel можно определять степень влияния каждого из указанных факторов по результатам имеющихся продаж, а после применить полученные данные для прогнозирования продаж на другой месяц или для другого магазина, расположенного рядом.
Обычно регрессия представлена в виде простого уравнения, раскрывающего зависимости и силу связи между двумя группами переменных, где одна группа является зависимой или эндогенной, а другая — независимой или экзогенной. При наличии группы взаимосвязанных показателей зависимая переменная Y определяется исходя из логики рассуждений, а остальные выступают в роли независимых Х-переменных.
Основные задачи построения регрессионной модели заключаются в следующем:
- Отбор значимых независимых переменных (Х1, Х2, …, Xk).
- Выбор вида функции.
- Построение оценок для коэффициентов.
- Построение доверительных интервалов и функции регрессии.
- Проверка значимости вычисленных оценок и построенного уравнения регрессии.
Регрессионный анализ бывает нескольких видов:
- парный (1 зависимая и 1 независимая переменные);
- множественный (несколько независимых переменных).
Уравнения регрессии бывает двух видов:
- Линейные, иллюстрирующие строгую линейную связь между переменными.
- Нелинейные — уравнения, которые могут включать степени, дроби и тригонометрические функции.
Инструкция построения модели
Чтобы выполнить заданное построение в Excel, необходимо следовать указаниям:
Для дальнейшего вычисления следует использоваться функцию «Линейн ()», указывая Значения Y, Значения Х, Конст и статистику. После этого определите множество точек на линии регрессии с помощью функции «Тенденция» — Значения Y, Значения Х, Новые значения, Конст. При помощи заданных параметров вычислите неизвестное значение коэффициентов, опираясь на заданные условия поставленной задачи.
Пакет MS Excel
позволяет при построении уравнения линейной регрессии большую часть работы сделать очень быстро
Важно понять, как интерпретировать полученные результаты.
Для построения модели регрессии необходимо выбрать пункт Сервис\Анализ данных\Регрессия (в Excel 2007
этот режим находится в блоке Данные/Анализ данных/Регрессия). Затем полученные результаты скопировать в блок для анализа.

Линия регрессии является графическим отражением взаимосвязи между явлениями. Очень наглядно можно построить линию регрессии в программе Excel.
Для этого необходимо:
1.Открыть программу Excel
2.Создать столбцы с данными. В нашем примере мы будем строить линию регрессии, или взаимосвязи, между агрессивностью и неуверенностью в себе у детей-первоклассников. В эксперименте участвовали 30 детей, данные представлены в таблице эксель:
1 столбик — № испытуемого
2 столбик — агрессивность
в баллах
3 столбик — неуверенность в себе
в баллах
3.Затем необходимо выделить оба столбика (без названия столбика), нажать вкладку вставка
,
выбрать точечная
, а из предложенных макетов выбрать самый первый точечная с маркерами
.
4.Итак у нас получилась заготовка для линии регрессии — так называемая — диаграмма рассеяния
. Для перехода к линии регрессии нужно щёлкнуть на получившийся рисунок, нажать вкладку конструктор,
найти на панели макеты диаграмм
и выбрать Ма
кет9
, на нем ещё написано f(x)
5.Итак, у нас получилась линия регрессии. На графике также указано её уравнение и квадрат коэффициента корреляции
6.Осталось добавить название графика, название осей. Также по желанию можно убрать легенду, уменьшить количество горизонтальных линий сетки (вкладка макет
, затем сетка
). Основные изменения и настройки производятся во вкладке Макет
Линия регрессии построена в MS Excel. Теперь её можно добавить в текст работы.
Регрессионный анализ — это статистический метод исследования, позволяющий показать зависимость того или иного параметра от одной либо нескольких независимых переменных. В докомпьютерную эру его применение было достаточно затруднительно, особенно если речь шла о больших объемах данных. Сегодня, узнав как построить регрессию в Excel, можно решать сложные статистические задачи буквально за пару минут. Ниже представлены конкретные примеры из области экономики.
Линейный регрессионный анализ
Выделяют несколько разновидностей регрессий: линейная, гиперболическая, множественная, логарифмически линейная, нелинейная, обратная, парная.
В рамках данной статьи мы рассмотрим линейную регрессию. В общем виде ее функция выглядит так:
В данном уравнении:
- Y – переменная, влияние на которую нужно найти;
- X – факторы, влияющие на переменную;
- A – коэффициенты регрессии, определяющие значимости факторов;
- N – общее количество факторов.
Чтобы было понятнее, давайте разберем конкретный практический пример. Допустим, у нас есть таблица, в которой представлена информация по среднесуточной температуре и количеству осадков с разбивкой по месяцам.

Наша задача – выяснить, как температура влияет на осадки. Приступи к ее выполнению.
- Щелкаем по кнопке “Анализ данных”.
- В открывшемся окошке отмечаем пункт “Регрессия”, после чего щелкаем OK.
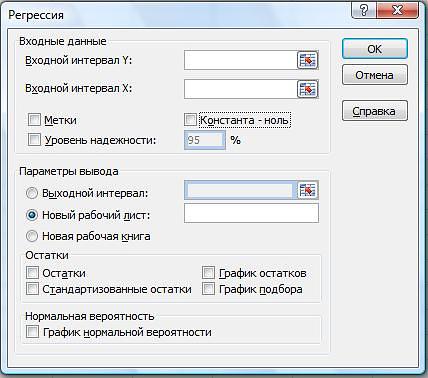
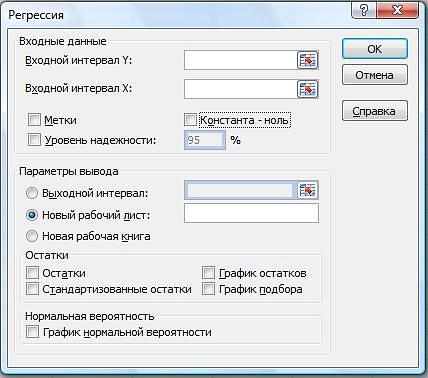
- Перед нами появится окно, в котором нужно настроить параметры регрессии:
- в поле “Входной интервал_Y” пишем координаты диапазона ячеек, в которых находятся переменные, влияние на которые нам нужно выяснить. У нас это столбец “Количество осадков, мм”. Координаты диапазона можно указать как вручную, используя клавиши на клавиатуре, так и выделив его в самой таблице с помощью зажатой левой кнопки мыши.
- в поле “Входной интервал_X” указываем координаты диапазона ячеек с данными, влияние которых нам нужно найти. В нашем случае – это столбец “Среднесуточная температура”.
- Остальные параметры не являются обязательными и, чаще всего, остаются незаполненными. У нас есть возможность установить метки, значения уровня надежности в процентах, константу-ноль, график нормальной вероятности и т.д. Пожалуй, самым важным здесь является способ вывода результатов анализа. Доступны следующие варианты: на новом листе (по умолчанию), в новой книге или в указанном диапазоне на этом же листе. Мы оставим все как есть и жмем кнопку OK.
Нахождение коэффициента корреляции в Excel
Если вы ищете корреляцию Пирсона в Excel 2007 или общий коэффициент корреляции, есть встроенные функции, которые позволяют рассчитать ее. Во-первых, вам нужно два массива данных, которые вы хотите сравнить для корреляций. Предположим, что они находятся в столбцах A и B, и в каждой ячейке от 2 до 21. Используйте функцию Корреля или Пирсона, чтобы найти коэффициент корреляции в Excel. В пустой ячейке введите «= Correl (массив 1, массив 2)» или «= Пирсон (массив 1, массив 2)», чтобы найти коэффициент корреляции с первым столбцом данных. ссылается там, где написано «массив 1», а второй там, где написано «массив 2». В этом примере вы должны ввести «= Pearson (A2: A21, B2: B21)» или «= Correl (A2: A21, B2: B21)», отметив, что вы также можете открыть скобки и затем выделить соответствующие ячейки с помощью свою мышь или клавиатуру, введите запятую, а затем выделите второй набор. Это возвращает коэффициент корреляции со значением между -1 и 1.
Выполнение простой и множественной регрессии с помощью инструментов анализа данных Excel
В Excel очень легко выполнять линейную регрессию с помощью пакета инструментов Data Analytis.
Если вы у вас нет пакета инструментов (его можно увидеть на вкладке «Данные» в разделе «Анализ»), возможно, вам потребуется добавить инструмент.
Перейдите на вкладку» Данные «, щелкните правой кнопкой мыши и выберите» Настроить ленту «.

- Выберите надстройки и перейдите в раздел «Управление надстройками Excel».
- Затем выберите пакет инструментов анализа, и теперь он должен быть виден на вкладке «Данные».
Теперь, когда мы можем выбрать различные встроенные анализы, мы запустим инструмент регрессии.
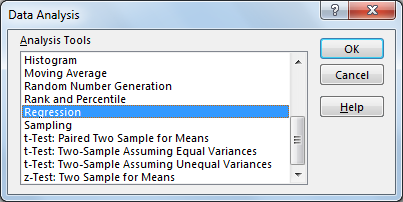
Если вы используете файл CSV или XSLX, вам следует отразить эти параметры.
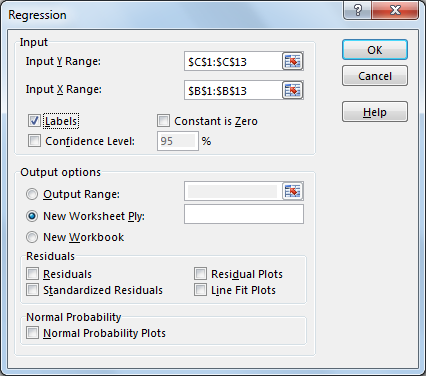
- Входной диапазон Y — это место, где находится переменная ответа (в нашем случае — продажи).
- Входной диапазон X равен диапазон переменных-предикторов (Spend).
- Проверяемые метки означают, что у вас есть заголовок в верхней части диапазона X и Y.
Дополнительные параметры, которые мы не проверили, это …
- Уровень достоверности — добавляет еще один доверительный интервал на выбранном уровне достоверности.
- Константа равно нулю — заставляет коэффициент X улавливать большую часть ошибки.
- Практически нет причин использовать этот параметр, если только ваши данные не имеют теоретической причины проходить через источник.
- Уравнение регрессии также фундаментально изменено (примечания к PDF)
- Остаточные значения — для каждой строки отображается ошибка/разница между прогнозируемыми и фактическими значениями. .
- Стандартизированные остатки нормализованы со средним нулевым значением и стандартным отклонением, равным единице.
- Графики остатков отображают остатки по каждой переменной.
- График подгонки линии отображает прогнозируемые результаты и фактические результаты по каждой переменной.
- Графики нормальной вероятности — Проверяет n ормальность ваших данных. Должно быть видно что-то похожее на прямую.
После запуска инструмента регрессии Excel мы получим…
- Статистика регрессии — Статистика R-квадрат и стандартная ошибка.
- ANOVA — Проверка значимости модели.
- Переменные веса и статистика — дает вам веса коэффициентов, p-значение и доверительные границы для коэффициентов.
Теперь вы знаете, как выполнять линейную регрессию в Excel! Однако Excel — не лучший инструмент для интеллектуального анализа данных. Попробуйте R с открытым исходным кодом и выполните линейную регрессию в R.
Основные задачи и виды регрессии
Регрессия представляет собой зависимость между заданными переменными, за счет чего можно определить прогноз будущего поведения данных переменных. Переменные — это различные периодические явления, включая и поведение человека. Такой анализ программы Excel применяется для того, чтобы проанализировать воздействие на конкретную зависимую переменную значений одной или некоторым количеством переменных.
К примеру, на продажи в магазине влияет несколько факторов, включая ассортимент, цены и место локализации магазина. Благодаря регрессии в Excel можно определять степень влияния каждого из указанных факторов по результатам имеющихся продаж, а после применить полученные данные для прогнозирования продаж на другой месяц или для другого магазина, расположенного рядом.
Обычно регрессия представлена в виде простого уравнения, раскрывающего зависимости и силу связи между двумя группами переменных, где одна группа является зависимой или эндогенной, а другая — независимой или экзогенной. При наличии группы взаимосвязанных показателей зависимая переменная Y определяется исходя из логики рассуждений, а остальные выступают в роли независимых Х-переменных.
Основные задачи построения регрессионной модели заключаются в следующем:
- Отбор значимых независимых переменных (Х1, Х2, …, Xk).
- Выбор вида функции.
- Построение оценок для коэффициентов.
- Построение доверительных интервалов и функции регрессии.
- Проверка значимости вычисленных оценок и построенного уравнения регрессии.
Регрессионный анализ бывает нескольких видов:
- парный (1 зависимая и 1 независимая переменные);
- множественный (несколько независимых переменных).
Уравнения регрессии бывает двух видов:
- Линейные, иллюстрирующие строгую линейную связь между переменными.
- Нелинейные — уравнения, которые могут включать степени, дроби и тригонометрические функции.
Инструкция построения модели
Чтобы выполнить заданное построение в Excel, необходимо следовать указаниям:
Для дальнейшего вычисления следует использоваться функцию «Линейн ()», указывая Значения Y, Значения Х, Конст и статистику. После этого определите множество точек на линии регрессии с помощью функции «Тенденция» — Значения Y, Значения Х, Новые значения, Конст. При помощи заданных параметров вычислите неизвестное значение коэффициентов, опираясь на заданные условия поставленной задачи.
Распространенные заблуждения
Корреляция и причинно-следственная связь
Традиционное изречение, что « корреляция не подразумевает причинно-следственную связь », означает, что корреляция не может использоваться сама по себе для вывода причинной связи между переменными. Это изречение не должно означать, что корреляции не могут указывать на потенциальное существование причинно-следственных связей. Однако причины, лежащие в основе корреляции, если таковые имеются, могут быть косвенными и неизвестными, а высокие корреляции также пересекаются с отношениями идентичности ( тавтологиями ), где не существует причинного процесса. Следовательно, корреляция между двумя переменными не является достаточным условием для установления причинно-следственной связи (в любом направлении).
Корреляция между возрастом и ростом у детей довольно прозрачна с точки зрения причинно-следственной связи, но корреляция между настроением и здоровьем людей менее очевидна. Приводит ли улучшение настроения к улучшению здоровья, или хорошее здоровье приводит к хорошему настроению, или и то, и другое? Или в основе обоих лежит какой-то другой фактор? Другими словами, корреляция может рассматриваться как свидетельство возможной причинной связи, но не может указывать на то, какой может быть причинная связь, если таковая имеется.
Простые линейные корреляции

Четыре набора данных с одинаковой корреляцией 0,816
Коэффициент корреляции Пирсона указывает на силу линейной связи между двумя переменными, но его значение, как правило, не полностью характеризует их взаимосвязь. В частности, если условное среднее из дано , обозначается , не является линейным в , коэффициент корреляции будет не в полной мере определить форму .
Y {\ displaystyle Y} Икс {\ displaystyle X} E ( Y ∣ Икс ) {\ displaystyle \ operatorname {E} (Y \ mid X)} Икс {\ displaystyle X} E ( Y ∣ Икс ) {\ displaystyle \ operatorname {E} (Y \ mid X)}
Прилегающие изображение показывает разброс участков из квартет энскомбы , набор из четырех различных пар переменных , созданный Фрэнсис Анскомбами . Четыре переменные имеют одинаковое среднее значение (7,5), дисперсию (4,12), корреляцию (0,816) и линию регрессии ( y = 3 + 0,5 x ). Однако, как видно на графиках, распределение переменных сильно отличается. Первый (вверху слева), кажется, распределен нормально и соответствует тому, что можно было бы ожидать, рассматривая две коррелированные переменные и следуя предположению о нормальности. Второй (вверху справа) не распространяется нормально; Хотя можно наблюдать очевидную взаимосвязь между двумя переменными, она не является линейной. В этом случае коэффициент корреляции Пирсона не указывает на то, что существует точная функциональная взаимосвязь: только степень, в которой эта взаимосвязь может быть аппроксимирована линейной зависимостью. В третьем случае (внизу слева) линейная зависимость идеальна, за исключением одного выброса, который оказывает достаточное влияние, чтобы снизить коэффициент корреляции с 1 до 0,816. Наконец, четвертый пример (внизу справа) показывает другой пример, когда одного выброса достаточно для получения высокого коэффициента корреляции, даже если связь между двумя переменными не является линейной.
y {\ displaystyle y}
Эти примеры показывают, что коэффициент корреляции как сводная статистика не может заменить визуальный анализ данных. Иногда говорят, что примеры демонстрируют, что корреляция Пирсона предполагает, что данные следуют нормальному распределению , но это неверно.
Что объясняет регрессия?
Прежде, чем мы приступим к рассмотрению функций MS Excel, позволяющих, решать данные задачи, хотелось бы вам на пальцах объяснить, что, в сущности, предполагает регрессионный анализ. Так вам проще будет сдавать экзамен, а самое главное, интересней изучать предмет.
Будем надеяться, вы знакомы с понятием функции из математики. Функция – это взаимосвязь двух переменных. При изменении одной переменной что-то происходит с другой. Изменяем X, меняется и Y, соответственно. Функциями описываются различные законы. Зная функцию, мы можем подставлять произвольные значения X и смотреть на то, как при этом изменится Y.
Это имеет большое значение, поскольку регрессия – это попытка объяснить с помощью определённой функции на первый взгляд бессистемные и хаотичные процессы. Так, например, можно выявить взаимосвязь курса доллара и безработицы в России.
Если данную закономерность обнаружить удастся, то по полученной нами в ходе расчетов функции, мы сможем составить прогноз, какой будет уровень безработицы при N-ом курсе доллара по отношению к рублю.
Данная взаимосвязь будет называться корреляцией. Регрессионный анализ предполагает расчет коэффициента корреляции, который объяснит тесноту связи между рассматриваемыми нами переменными (курсом доллара и числом рабочих мест).
Данный коэффициент может быть положительным и отрицательным. Его значения находятся в пределах от -1 до 1. Соответственно, мы может наблюдать высокую отрицательную или положительную корреляцию. Если она положительная, то за увеличением курса доллара последует и появление новых рабочих мест.
Выбор модели мы делаем в зависимости от того, какая регрессия будет соответствовать конкретно нашему случаю, какая модель будет максимально близка к нашей корреляции. Рассмотрим это на примере задачи и решим её в MS Excel.
Линейная регрессия в MS Excel
Для решения задач линейной регрессии вам понадобится функционал «Анализ данных». Он может быть не включен у вас поэтому его нужно активировать.
- Жмём на кнопку «Файл»;
- Выбираем пункт «Параметры»;
- Жмём по предпоследней вкладке «Надстройки» с левой стороны;
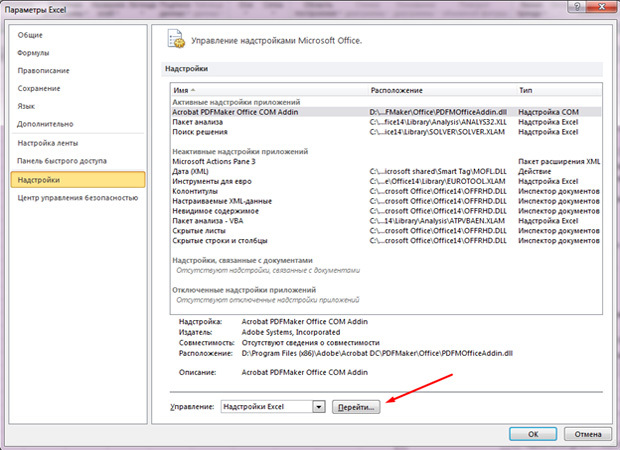
- Снизу увидим Надпись «Управление» и кнопку «Перейти». Жмём по ней;
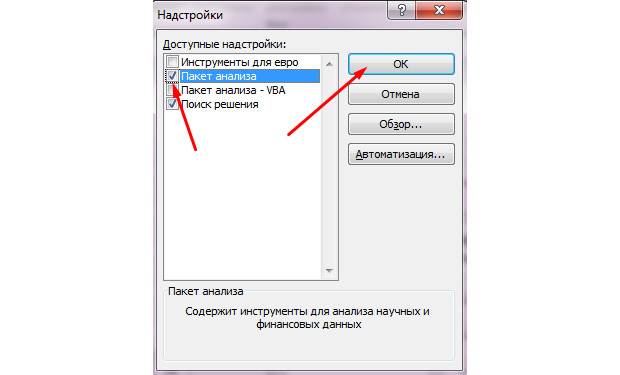
- Ставим галочку на «Пакет анализа»;
- Жмём «ок».
Пример задачи
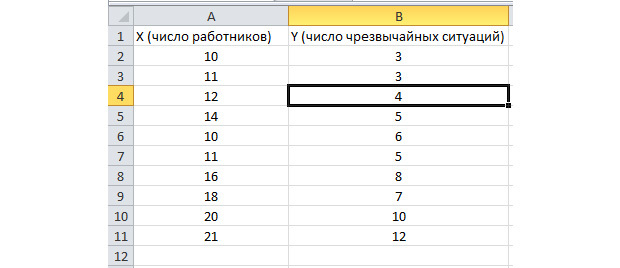
Функция пакетного анализа активирована. Решим следующую задачу. У нас есть выборка данных за несколько лет о числе ЧП на территории предприятия и количестве трудоустроенных работников.
Нам необходимо выявить взаимосвязь между этими двумя переменными. Есть объясняющая переменная X – это число рабочих и объясняемая переменная – Y – это число чрезвычайных происшествий.
Распределим исходные данные в два столбца.
Перейдём во вкладку «данные» и выберем «Анализ данных»

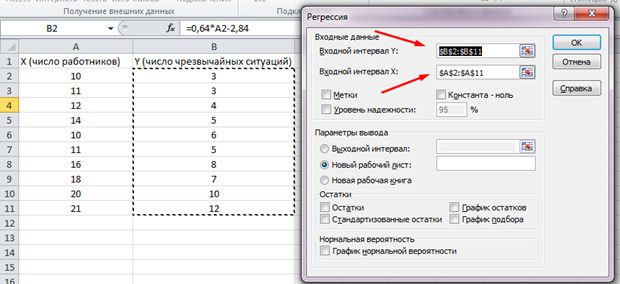
Нажимаем «Ок». Анализ произведён, и в новом листе мы увидим результаты.
Наиболее существенные для нас значения отмечены на рисунке ниже. 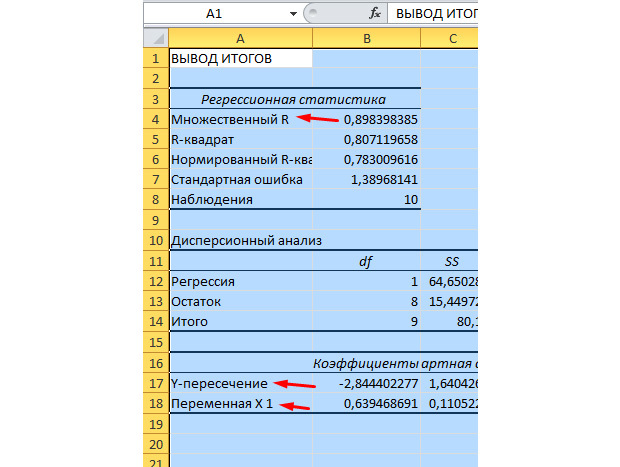
Множественный R – это коэффициент детерминации. Он имеет сложную формулу расчета и показывает, насколько можно доверять нашему коэффициенту корреляции. Соответственно, чем больше это значение, тем больше доверия, тем удачнее наша модель в целом.
Y-пересечение и Пересечение X1 – это коэффициенты нашей регрессии. Как уже было сказано, регрессия – это функция, и у неё есть определённые коэффициенты. Таким образом, наша функция будет иметь вид: Y = 0,64*X-2,84.
Что нам это даёт? Это даёт нам возможность составить прогноз. Допустим, мы хотим нанять на предприятие 25 работников и нам нужно примерно представить, каким при этом будет количество чрезвычайных происшествий. Подставляем в нашу функцию данное значение и получаем результат Y = 0,64 * 25 – 2,84. Примерно 13 ЧП у нас будет происходить.
Посмотрим, как это работает. Взгляните на рисунок ниже. В полученную нами функцию подставлены фактические значения по вовлеченным работникам. Посмотрите, как близки значения к реальным игрекам.
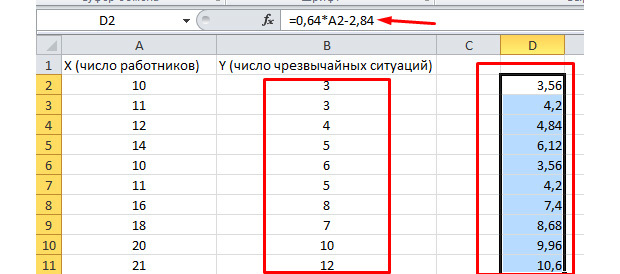
Вы так же можете построить поле корреляции, выделив область игреков и иксов, нажав на вкладку «вставку» и выбрав точечную диаграмму.
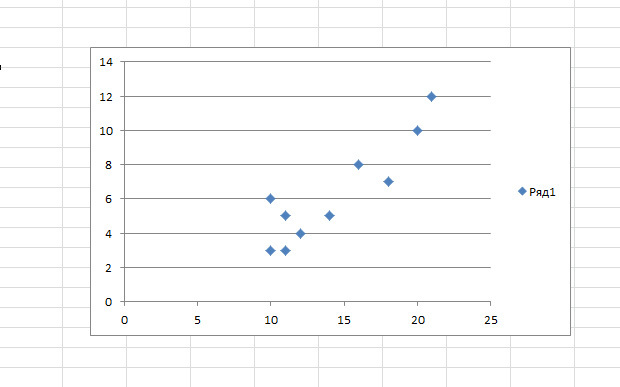
Точки идут вразброс, но в целом двигаются вверх, как будто посередине лежит прямая линия. И эту линию вы так же можете добавить, перейдя во вкладку «Макет» в MS Excel и выбрав пункт «Линия тренда»

Заключение
Будем надеяться, что данная статья дала вам большее понимание о том, что такое регрессионный анализ и для чего он нужен. Всё это имеет большое прикладное значение.