Как скачать весь сайт при помощи wget на windows
Содержание:
Специальные программы для скачивания сайтов
Разработчики приложений создают специальные программы, которые позволяют быстро скачать необходимый сайт в интернете. Для этого нужно знать, какие утилиты лучше применять, принципы их работы и прочие нюансы.
HTTrack WebSite Copier
Это приложение является лучшим среди бесплатных программ для сохранения интернет-страничек в оффлайн режиме. Скачать его можно с официального сайта разработчика или на других порталах.
Как пользоваться утилитой:
- для начала нужно скачать приложение на компьютер, установить и запустить;
- появится окно с настройками, где нужно будет выбрать язык, среди перечисленных вариантов выделяем русский;
- после этого откроется окно, где нужно подписать проект, указать категорию и место для загрузки сайта;
- далее, в специальной графе вводим адрес самого сайта для скачивания.
Через несколько минут программа автоматически загрузит все данные из веб-страницы в указанную папку на компьютере. Информация будет доступна в off-line режиме в файле index.htm.
Сама по себе утилита проста в использовании, интерфейс несложный, сможет разобраться любой пользователь. Есть возможность настроить программу под себя, например, запретить скачивать картинки с сайта или отметить только желаемые страницы. Среди плюсов можно выделить: бесплатную версию, простой интерфейс, быстрое сохранение сайта. Минусов не обнаружено, так как утилита имеет большое количество положительных отзывов со всего мира.
Teleport Pro
Продолжает список лучших программ Teleport Pro. Это одно из самых старых приложений, которое позволяет скачать сайт на компьютер. По сравнению с прошлой утилитой, эта программа платная, ее стоимость на официальном портале составляет $50. Для тех, кто не хочет платить, есть тестовая версия, которая даст возможность пользоваться приложением определенный период времени.
После скачивания и установки откроется главное окно утилиты, там нужно указать параметры для сохранения сайта. Предлагается выбрать такие варианты: сохранить загружаемую копию, дублировать портал, включая структуру, сохранить определенный тип файлов, сохранить все интернет-ресурсы, связанные с источником, загрузить файлы по указанным адресам, скачать страницы по ключевым словам.
Далее создается новый проект, где указывается адрес самого сайта, а также папка для сохранения данных. Чтобы запустить программу, нужно нажать на кнопку «Start». Оффлайн доступ к файлам сайта будет открыт уже через несколько минут.
https://youtube.com/watch?v=Q3n9vsrE9P4
Положительные стороны приложения – простота в использовании, удобное и быстрое скачивание. Среди минусов стоит выделить платную версию, которую смогут купить далеко не все пользователи.
Offline Explorer Pro
На этом список программ для скачивания сайтов не заканчиваются. Есть еще одна платная утилита, которая имеет большое количество функций и возможностей. На официальном сайте можно скачать бесплатную версию, но она будет иметь ряд ограничений на сохранение файлов. Полная версия приложения делиться на три пакета: Standard, Pro и Enterprise. Стоимость стандартной утилиты обойдется в $60, а с расширением Pro – $600.
Как и в большинстве программ, процесс скачивания начинается с создания нового проекта. Там вводится название, веб-адрес, необходимая папка на компьютере. Также сеть большое количество настроек, которые позволяют скачать только самую нужную информацию. Предлагается сохранить только текст или с картинками. Программисты и разработчики сайтов точно ее оценят.
После регулировки параметров нужно нажать на кнопку «Загрузка», и утилита начнет сохранять файлы на ПК. Скачивание длится недолго, уже через несколько минут данные сайта будут в папке. Преимущества – многофункциональность, доступна русская версия, быстрая загрузка. Недостатки – только платная версия, которая стоит недешево.
Webcopier
Еще одно платное приложение, которое имеет бесплатную версию, действующую 15 дней. Процесс работы похож на предыдущие программы. Необходимо создать новый проект, заполнить информацию о сайте, ввести адрес и указать папку для загрузки. Нажатие кнопки «Start download» позволит запустить работу утилиты. Скорость скачивания среднее, ниже, чем у других программ. Приобрести полную версию можно за $40.
Плюсы – приятный интерфейс, удобные настройки, простое управление.
Минусы – платная версия.
Руководство по быстрому выбору (ссылки на бесплатные программы для скачивания веб-сайтов)
HTTrack
| Поддерживает несколько операционных систем. Огромный список настроек. | ||
| Не так проста в освоении, как другие продукты | ||
| ———— | ||
| 2-5 MB 3.48-21 Unrestricted freeware Windows, Linux, Mac OSX | ||
| Поддержка 64-разрядной ОС |
PageNest
| Простая и удобная в использовании. | ||
| ————— | ||
| 1,8 MB V3.30 Бесплатно для личного использования Windows XP — 7 | ||
| Поддержка 64-разрядной ОС |
Local Website Archive
| Простая и удобная в использовании. Интеграция с Opera, Firefox и IE. Поисковый механизм с подсветкой | ||
| ———— | ||
| 4,8 MB 14.0 Бесплатно для личного использования Windows XP — 8 | ||
| Поддержка 64-разрядной ОС |
GetLeft
| Простая в использовании. Поддерживает скачивание с внешних ссылок с сайта. Имеет ряд полезных настроек | ||
| 2,5 MB 1.0.1963.0 Unrestricted freeware Windows (c Tcl/Tk), Linux, Mac OSX | ||
| Поддержка 64-разрядной ОС |
Рубрики:
- браузер
- интернет
- менеджер
- сеть
- Лучшие бесплатные программы для скачивания файлов и фильмов (менеджеры загрузок)
- Лучшие бесплатные программы для проверки ссылок на веб-сайте
Обзор методов копирования
Мы рассмотрим методы, и постараемся описать преимущества и недостатки. На сегодняшний день существует два основных метода копирования сайтов:ручной
автоматизированный.
Ручной метод
С ручным все понятно. Это когда через браузер в один клик сохраняете страницу, либо в ручную создаете все файлы страницы: html файл с исходным кодом верстки, js, css, картинки и т.д. Так себя мучать мы Вам не рекомендуем.
Загружаем html код страницы
Далее всё очень просто: находим интересующий нас проект, открываем главную страницу и нажимаем на клавиши ctrl + U. Браузер сразу же показывает нам её код.
Копируем его, создаём новый файл в редакторе кода, вставляем код главной страницы, в новый файл, сохраняя его под названием index, с расширением html (index.html). Всё, главная страница сайта готова. Размещаем её в корне документа, то есть кладём файл индекс.html рядом с папками images, css и js
Далее чтобы скачать сайт целиком на компьютер проделываем тоже со всеми страницами сайта. (Данный метод подходит, только если ресурс имеет не слишком много страниц). Таким же образом, копируем все html-страницы понравившегося нам сайта в корневую папку, сохраняем их с расширением html и называем каждую из них соответствующим образом (не русскими буквами – contact.html, about.html).
Создаём css и js файлы
После того как мы сделали все страницы сайта, находим и копируем все его css стили и java скрипты. Для этого кликаем по ссылкам, ведущим на css и js файлы в коде.
Таким же образом как мы копировали файлы html, копируем все стили и скрипты создавая в редакторе Notepad++ соответствующие файлы. Делать их можно с такими же названиями, сохраняя их в папках сss и js. Файлы стилей кладём в папку css, а код java script в папку js.
Копируем картинки сайта
Чтобы скачать сайт целиком на компьютер также нам нужны все его картинки. Их можно загрузить, находя в коде сайта и открывая по порядку одну за другой. Ещё можно увидеть все картинки сайта, открыв инструменты разработчика в браузере с помощью клавиши F12. Находим там директорию Sources и ищем в ней папку img или images В них мы увидим все картинки и фотографии сайта. Скачиваем их все, ложа в папку images.
Убираем всё лишнее в html коде
После того как мы скачали все файлы сайта нужно почистить его код от всего лишнего. Например, можно удалить:
- код google analytics и yandex метрики;
- код верификации сайта в панелях для веб мастеров яндекса и гугла:
- можно удалить любой код, который нам не нужен и оставить тот, что нужен.
Автоматизированный
Рассмотрим наименее затратный способ — автоматизированный. К нему относятся онлайн сервисы (грабберы) для парсинга, и специальные десктопные программы. Чтобы Вам легче было выбрать, ниж рассмотрим более детально.
Преимущество онлайн сервисов заключается в том, что Вы получаете готовый результат, и не о чем не беспокоитесь. Ко всему прочему, Вы всегда можете спросить за результат. В редких случаях имеется возможность внесения правок в исходный код и дизайн силами исполнителя. К сожалению, данное удовольствие стоит денег, а потому для многих данный способ не приемлим.
Для тех, кто хочет сэкономить, на помощь приходят специальные программы для парсинга. Метод довольно затратный, если Вам нужно получить два-три сайта, т.к. каждая отдельная программа обладает своими особенностями, и для изучения Вам понадобится не мало времени.
А учитывая, что результат работы трудно редактируемый, то возникает вопрос: стоит ли тратить время на изучение, чтобы получить результат на который надо потратить еще кучу времени. Выбор за Вами.
Offline Explorer
Платная программа-комбайн, есть демо. Из явных отличий от WinHTTrack:
- встроенный Web-browser и Web сервер для локального предпросмотра;
- распознаёт и загружает ссылки из HTML файлов, Java- и VB- скриптов, классов Java, Macromedia Flash (SFW), CSS, XML/XSL/DTD, TOC, PDF, M3U, AAM, RealMedia (SMIL, RAM, RPM) и MS NetShow Channel (.NSC) файлов;
- поиск по загруженным сайтам;
- экспорт в различные форматы (в т.ч. для записи сайтов на CD);
- удаление скриптов со страниц web.archive.org.
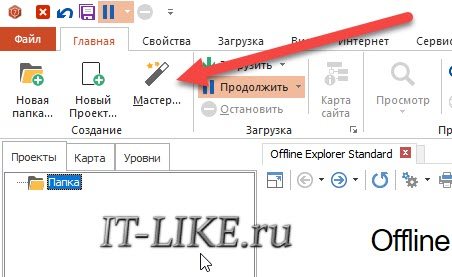
Интерфейс покажется более замороченным, но ничего сложного в нём нет. Запускаем мастер:
Выбираем один из 12 шаблонов:
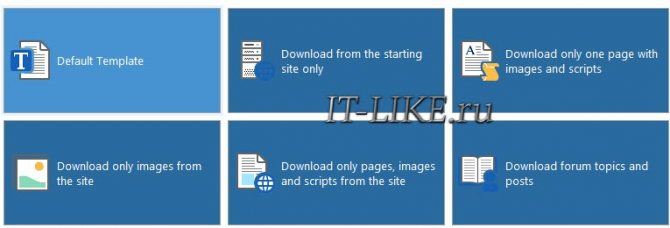
Например, шаблон «Download only one page with images and scripts» заточен для загрузки только одной страницы. Если не знаете какой выбрать, то пусть будет «Default Template». Далее вводим нужный сайт, любое название проекта и путь к папке на диске:
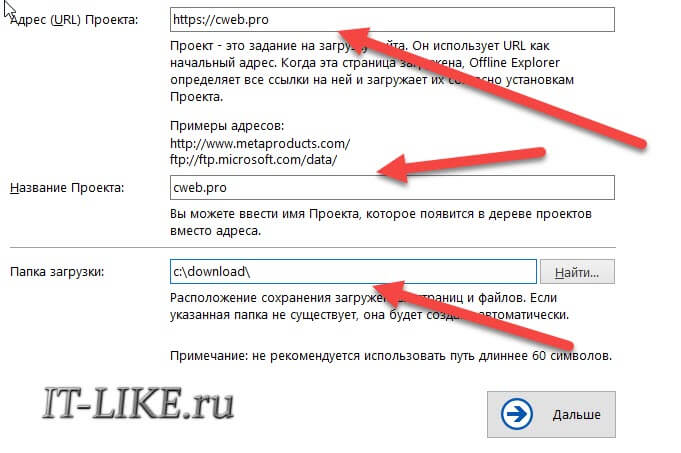
Нажимаем «Дальше» и выходим из мастера. Должен начаться процесс скачивания, но если ничего не происходит, тогда ткните кнопку «Продолжить»
По окончанию загрузки придёт уведомление на рабочий стол.
Из платных, ещё можете попробовать некогда легендарную программу Teleport Pro (на английском), но по-моему за неё просят намного больше, чем она стоит, да и устарела уже.
Используем стандартные функции браузера
Такую возможность предоставляет пользователю практически любой веб-браузер. Пользователи сохраняют страницы для того, чтобы затем в автономном оффлайн режиме (когда отсутствует интернет-соединение) её можно было просматривать. При этом сохранение можно произвести полностью либо в формате html, то есть с разметкой и структурой. Затем скинуть на носитель информации, перенести на другой компьютер и просмотреть в любом другом браузере.
Рассмотрим эту процедуру на примере 4 популярных браузеров.
Обозреватель Google Chrome
Сохранить страницу можно несколькими способами.
Первый – в правом верхнем углу веб-обозревателя есть кнопка с тремя точками. Жмём по ней левой клавишей.
Дальше Дополнительные инструменты – Сохранить страницу как. То же самое можно сделать комбинацией Ctrl+S или правым кликом в свободной от картинок и видео области сайта – Сохранить как.
Далее на компьютере выбираем место, куда следует произвести сохранение.
Здесь в области Тип файла есть 2 варианта – сохранить страницу полностью (текст, разметка + картинки) или только HTML (только текст и разметка).
После нажатия кнопки подтверждения в указанное место загрузится документ в виде файла html и папки с таким же названием, содержащей картинки и другую информацию о документе.
Кликнув по нему двойным щелчком откроется точно такая же страница, но локально с адресом, по которому Вы её сохранили.
Если решите куда-нибудь скопировать полученный файл, то копируйте и html документ и одноименную папку.
Использование Mozilla Firefox
В этом браузере кнопка с аналогичным функционалом, что и в Хроме располагается на том же месте. Жмём её и выбираем «Сохранить страницу». Сработает также сочетание клавиш Ctrl+S.
При сохранении будет 4 варианта.
Добавляется вариант только текст (без стилей и картинок) в формате txt. Этот вариант будет полезным, если страницу защищена от копирования, а Вам необходимо каким-то образом получить из неё текстовую информацию.
Сохранение в Яндекс.Браузере
В самом верху справа есть кнопка с шестеренкой, жмем по ней – Сохранить страницу как или же Ctrl+S.
Как и в хроме будет предложена сохраниться полностью или только html.
Обозреватель Opera
Этот браузер наиболее корректно сохраняет информацию с веб-ресурсов.
Слева вверху есть главная кнопка с лого Opera. Жмем по ней, выбираем Страница – Сохранить как.
Как и в других обозревателях сработает также Ctrl+S.
Откроется 5 вариантов.
Здесь пункт HTML-файл с изображениями будет соответствовать варианту полностью в других обозревателях.
Если Вам удобно, чтобы сохранение происходило в одном файле, то для этих целей здесь есть вариант Веб-архив. Архив при этом будет создан с расширением mht. Открыть его можно только через Opera.
Обзор методов копирования
Мы рассмотрим методы, и постараемся описать преимущества и недостатки. На сегодняшний день существует два основных метода копирования сайтов: ручной и автоматизированный.
Ручной метод
С ручным все понятно. Это когда через браузер в один клик сохраняете страницу, либо в ручную создаете все файлы страницы: html файл с исходным кодом верстки, js, css, картинки и т.д. Так себя мучать мы Вам не рекомендуем.
Автоматизированный
Рассмотрим наименее затратный способ – автоматизированный. К нему относятся онлайн сервисы (грабберы) для парсинга, и специальные десктопные программы. Чтобы Вам легче было выбрать, ниж рассмотрим более детально.
Преимущество онлайн сервисов заключается в том, что Вы получаете готовый результат, и не о чем не беспокоитесь. Ко всему прочему, Вы всегда можете спросить за результат. В редких случаях имеется возможность внесения правок в исходный код и дизайн силами исполнителя. К сожалению, данное удовольствие стоит денег, а потому для многих данный способ не приемлим.
Для тех, кто хочет сэкономить, на помощь приходят специальные программы для парсинга. Метод довольно затратный, если Вам нужно получить два-три сайта, т.к. каждая отдельная программа обладает своими особенностями, и для изучения Вам понадобится не мало времени.
А учитывая, что результат работы трудно редактируемый, то возникает вопрос: стоит ли тратить время на изучение, чтобы получить результат на который надо потратить еще кучу времени. Выбор за Вами.
Архивы веб-страниц, постоянные
Если вы хотите сохранять текстовый контент, то для этих целей рекомендуются Pocket и Instapaper. Вы можете сохранять страницы через электронную почту, расширения для браузеров или через приложения. Эти сервисы извлекают текстовый контент из веб-страниц и делают его доступным на всех ваших устройствах. Но вы не можете загрузить сохраненные статьи, а только прочитать их на сайте Pocket или через мобильное приложение сервиса. Дальше мы расскажем, как полностью скопировать страницу сайта.
Evernote и OneNote — это инструменты для архивирования контента в подборки. Они предоставляют в распоряжение пользователей веб-клипперы (или расширения), которые позволяют легко сохранять полные веб-страницы в один клик.
Захваченные веб-страницы могут быть доступны с любого устройства, сохраняется оригинальный дизайн и возможность поиска по странице. Эти сервисы могут даже выполнять оптическое распознавание, чтобы найти текст на фотографиях. Evernote также позволяет экспортировать сохраненные страницы как HTML-файлы, которые можно загрузить в другом месте.
Если нужен быстрый и простой доступ к веб-страницам, то сохраняйте их в виде PDF-файлов. Перед тем, как скопировать страницу сайта в виде картинки, выберите правильный инструмент.
Google Chrome имеет встроенный PDF-конвертер. Также можно использовать Google Cloud Print. На сервис добавлен новый виртуальный принтер «Сохранить в Google Drive». В следующий раз, когда вы будете печатать страницу на компьютере или мобильном устройстве через Cloud Print, вы сможете сохранить ее PDF-копию в Google Drive. Но это не лучший вариант сохранения страниц со сложным форматированием.
Когда важно сохранить дизайн, то лучше всего использовать скриншотер. Выбор подобных программ довольно велик, но я бы рекомендовал официальное дополнение Chrome от Google
Оно не только захватывает полные скриншоты веб-страниц, но также загружает полученное изображение на Google Drive. Дополнение может сохранять веб-страницы в формате веб-архива (MHT), который поддерживается в IE и Firefox.
Wayback Machine на Internet Archive — это идеальное место для поиска предыдущих версий веб-страницы. Но этот же инструмент можно использовать, чтобы скопировать страницу сайта и сохранить ее. Перейдите на archive.org/web и введите URL-адрес любой веб-страницы. Архиватор скачает на сервер ее полную копию, включая все изображения. Сервис создаст постоянный архив страницы, который выглядит так же, как оригинал. Он останется на сервере, даже если исходная страница была переведена в автономный режим.
Internet Archive не предоставляет возможности загрузки сохраненных страниц, но для этого можно использовать Archive.Is. Этот сервис очень похож на archive.org в том, что вы вводите URL-адрес страницы, и он создает на своем сервере точный ее снимок. Страница будет сохранена навсегда, но здесь есть возможность загрузить сохраненную страницу в виде ZIP-архива. Сервис также позволяет создавать архивы по дате. Благодаря чему вы можете получить несколько снимков одной и той же страницы для разных дат.
Все популярные браузеры предоставляют возможность загрузить полную версию веб-страницы на компьютер. Они загружают на ПК HTML страницы, а также связанные с ней изображения, CSS и JavaScript. Поэтому вы сможете прочитать ее позже в автономном режиме.
Теперь разберемся, как полностью скопировать страницу сайта на электронную читалку. Владельцы eReader могут использовать dotEPUB, чтобы загрузить любую веб-страницу в формате EPUB или MOBI. Данные форматы совместимы с большинством моделей электронных книг. Amazon также предлагает дополнение, с помощью которого можно сохранить любую веб-страницу на своем Kindle-устройстве, но этот инструмент в основном предназначен для архивирования текстового контента.
Большинство перечисленных инструментов позволяют загружать одну страницу, но если вы хотите сохранить набор URL-адресов, решением может стать Wget. Также существует Google Script для автоматической загрузки веб-страниц в Google Drive, но таким образом можно сохранить только HTML-контент.
Данная публикация представляет собой перевод статьи «The Best Tools for Saving Web Pages, Forever» , подготовленной дружной командой проекта Интернет-технологии.ру
Еще не голосовали рейтинг из ХорошоПлохо Ваш голос принят
SiteSucker
Если вы твердо придерживаетесь экосистемы Apple и имеете доступ только к Mac, вам нужно попробовать SiteSucker. Программа, получившая такое название, копирует все файлы веб-сайта на жесткий диск. Пользователи могут начать этот процесс всего за несколько кликов, что делает его одним из самых простых в использовании инструментов. Кроме того, SiteSucker довольно быстро копирует и сохраняет содержимое сайта. Однако помните, что фактическая скорость загрузки будет зависеть от пользователя.
К сожалению, SiteSucker не лишен недостатков. Во-первых, SiteSucker — платное приложение. На момент написания этой статьи SiteSucker стоит $4.99 в App Store. Кроме того, SiteSucker загружает каждый файл на сайте, который может быть найден. Это означает большую загрузку с большим количеством потенциально бесполезных файлов.
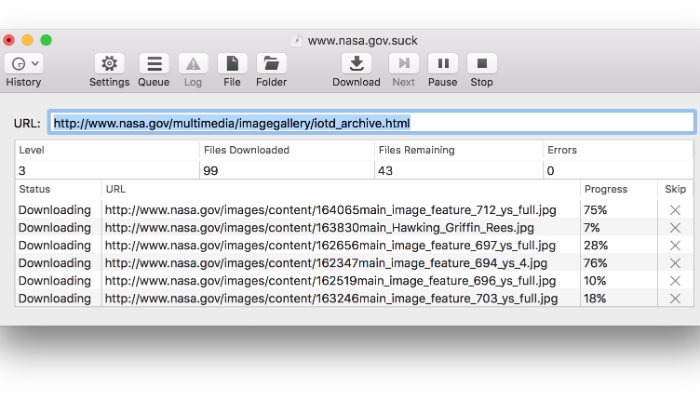
Настройка wget в Windows
В то время как субкультура, использующая wget ежедневно, сильно ориентирована на Unix, использование wget в Windows немного более необычно. Если вы попытаетесь найти его и вслепую загрузить с официального сайта, вы получите кучу исходных файлов, а не файл .exe. Средний пользователь Windows хочет двоичные файлы , поэтому:
Получите последнюю версию wget для Windows, выберите zip-версию последней версии и распакуйте ее куда-нибудь. Я использую папку для переносимого программного обеспечения, так как это не требует установки.
Если вы попытаетесь открыть файл .exe, скорее всего, ничего не произойдет, просто вспышка командной строки. Я хочу получить доступ к этому wget.exe, имея открытую командную строку в папке, в которую я буду загружать весь архив веб-сайта. Нецелесообразно перемещать .exe туда и копировать его в любую другую папку архива в будущем, поэтому я хочу, чтобы он был доступен для всей системы . Поэтому я «регистрирую» его, добавляя в переменные среды Windows.
- Нажмите Windows + R, вставьте указанную выше строку и нажмите Enter
- Под Пользовательскими переменными найдите Путь и нажмите Редактировать…
- Нажмите New и добавьте полный путь к тому месту, куда вы извлекли wget.exe
- Нажмите ОК, ОК, чтобы закрыть все
Чтобы убедиться, что он работает, снова нажмите Windows+ Rи вставьте – он не должен сказать, что «wget» не распознан
Постобработка архива
К сожалению, ни одна автоматизированная система не является идеальной, особенно если ваша цель – загрузить весь сайт. Вы можете столкнуться с некоторыми небольшими проблемами. Откройте заархивированную версию страницы и сравните ее рядом с живой. Там не должно быть существенных различий. Я удовлетворен, если весь текстовый контент там с изображениями. Гораздо меньше волнует, работают ли динамические части или нет. Здесь я рассматриваю наихудший сценарий, когда изображения отсутствуют.
Современные сайты используют атрибут и тег для загрузки адаптивных изображений. Хотя wget постоянно совершенствуется, его возможности отстают от передовых технологий современного Интернета. Хотя в wget версии 1.18 добавлена поддержка, ей не нравится более экзотическая комбинация тегов. Это приводит к тому, что wget только находит запасное изображение в теге img, а не в любом из исходных тегов. Он не загружает их и не затрагивает их URL. Обходной путь для этого состоит в массовом поиске и замене (удалении) этих тегов, поэтому резервное изображение все еще может появиться.
- Получить последнюю версию grepWin – я рекомендую портативную версию.
- Добавить папку архива в Поиск в
- Выберите Regex search и Search для:
- Добавить в имена файлов совпадают:
- Нажмите « Заменить» (вы можете проверить, что он что-то находит с помощью функции « Поиск» )
Вы можете использовать grepWin как, чтобы исправить другие повторяющиеся проблемы . Одна статья не может подготовить вас ко всему и не научит вас регулярным выражениям (подсказка: в них нет ничего регулярного ). Таким образом, этот раздел просто дает вам представление о корректировке результатов. Подход Windows не подходит для расширенной пост-обработки. В Unix-подобных системах есть более удобные инструменты для массовой обработки текста, такие как sed и оригинальный grep .
Как сохранить страницу с интернета на компьютер
Каждый интернет-браузер имеет функцию сохранения веб-страниц на ноутбук или компьютер. Рассмотрим пример сохранения страницы сайта в популярном браузере Opera.
Для этого перейдём в браузер Opera на нужную для нас веб-страницу, чтобы скопировать её. Переходим на кнопку, которая находится в левом верхнем углу браузера и открываем меню. После нажимаем на вкладку «Страница», чтобы увидеть пункт «Сохранить как…» Тот же самый результат будет, если нажмёте комбинацию Ctrl+S.
Далее, нужно нажать на «Сохранить как…» и выбрать место на диске, куда вы желаете сохранить файл. Выберете тип файла и сохраняйте. Выбранная страница сайта сохранится в нужном формате и расширением html. Это очень удобный формат. В нём текст и все элементы сайта вместе с картинками сохранятся полностью и в одном файле. Браузер Internet Explorer тоже может сохранять в таком формате.
Если при сохранении выбрать тип файла «HTML с изображениями», то создаётся не только файл с таким расширением. Вместе с этим будет создан отдельный каталог, где будут храниться картинки и прочие элементы. Хотя страница и полностью сохранится, такой вариант архивации не очень удобен.
Иногда, копируя нужную информацию на флеш-карту, каталог с картинками может не поместиться по каким-либо причинам. Например, загруженность флеш-карты или большая величина самого каталога с картинками. В этом случае возникнет неудобство при открытии сохранённого сайта. Он будет открываться в виде текста без картинок. Поэтому такой вариант устроит далеко не всех.
Если картинки вас не очень интересуют, то всю страницу можно скопировать в текстовом формате. Файл будет храниться на компьютере или флеш-карте с расширением txt. Или выделить фрагмент нужного текста и скопировать в Word. После чего документ будет сохранён с соответствующим расширением этой программы.
Аналогично сохранить веб-страницу можно и в других браузерах. Хотя существуют некоторые нюансы.
- В Google Chrome команда «Сохранить страницу как…» выполняется из пункта настроек и управления. Меню расположено в правом верхнем углу. При этом следует заметить, что сохранение в текстовый и архивный файл Chrome не поддерживает.
- В Mozilla Firefox пункт «Сохранить как…» появится, если нажать на кнопку «Файл» в появившемся меню.
- Internet Explorer страница сохраняется аналогично вышеуказанным браузерам.
Мы уверены, что Вам будет полезна статья о том, как пользоваться торрентом.
Сохранение веб-страницы в PDF формате
Скачать страницу через веб-браузер на ноутбук или компьютер не каждому покажется удобным. Поскольку, кроме неё, создаётся каталог с изображениями, а также масса других отдельных элементов. Для наиболее компактного сохранения страницы можно преобразовать её в PDF файл. Эта возможность есть в браузере Google Chrome, который сохранит её в этом формате полностью.
Для этого нужно зайти в «управление и настройки» из меню и нажать на команду «Печать». В появившемся окне печати документа и подпункте «Принтер» кликнуть на кнопку «Изменить». Появятся все доступные принтеры и строчка «Сохранить как PDF». Нужно нажать на «Сохранить» и указать место на диске, куда будет сохранена интернет-страница. После чего её можно будет преобразовать практически в любой формат с помощью специальных конверторов.
Сохранение через скриншот
Ещё один вариант сохранения веб-страницы в виде картинки при помощи скриншота. Для этого нажмите комбинацию Shift+Print Screen. При этом сохранится область страницы, которая находится в рамках экрана. Если текст входит не весь можно уменьшить захват экрана путём изменения масштаба. После сохранения можно использовать любой графический редактор для различных корректировок.
А также можно использовать специальные программы для создания скриншотов. Одной из таких программ является Clip2net. Она довольна популярна из-за своей многофункциональности и простоты в использовании. Скачать её можно бесплатно с официального сайта. После создания скриншотов она сохранит их в любую указанную вами папку. А также ими можно будет обмениваться через интернет даже с помощью созданных ею ссылок.
Как сохранить страницу сайта в Браузере
Все современные Андроид браузеры умеют сохранять страницы для просмотра без интернета (кстати, там не будет рекламы). Некоторые умеют сохранять страницы в .html формат, другие же только в PDF, предлагаем вашему вниманию четыре самых популярных браузера и инструкции как сохранить веб-страницы в них.
Google Chrome
Google Chrome для Андроид
Разработчик: Google LLC
4.3
Универсальный браузер, позволяет сохранять страницы целиком в PDF и .html форматах, сохраненные файлы будут располагаться в памяти устройства, в папке загрузок.Инструкция
- Зайдите в настройки браузера, нажав «три точки» в верхнем правом углу
- В Хроме страницу можно сохранить двумя способами (а также отправить в стороннее приложение, например в Pocket)
- В открывшемся меню найдите значок «стрелки вниз» — таким образом
сохранится .html копия страницы
- Если найти внизу меню пункт и в появившемся меню выбрать , то страница сохранится в PDF формате
Yandex Браузер
Яндекс.Браузер — с Алисой
Разработчик: Яндекс
4.52
- Зайдите в настройки браузера, «три точки» в нижнем правом углу браузера
- Пролистайте меню в самый низ, пока не найдете пункт
- Появится меню с выбором «принтера» и выбором нужных страниц. Нажимаем на и тут же появятся две кнопки , нажимаем любую
- Сохраненный PDF файл можно найти через файловый менеджер: он будет в загрузках или в документах
Opera
Браузер Opera: новости и поиск
Разработчик: Opera
4.37
Этот браузер позволяет сохранять страницы сайтов только в «собственном формате», то есть в итоге у вас не будет ни .html, ни .pdf файла. Но ваши сохраненные страницы будут доступны после синхронизации на всех браузерах Opera где вы зайдете в свой аккаунт.Инструкция
- Заходим в настройки браузера, нажав «три точки» в верхнем правом углу
- Находим кнопку и нажимаем ее
- Если появилось сообщение , все прошло успешно
- Для доступа к сохраненной странице нажмите на логотип браузера в правом нижнем углу и выберите
Firefox
Быстрый браузер Firefox
Разработчик: Mozilla
4.37
Firefox позволяет сохранять страницы в PDF формате на память устройства, файл можно найти через файловый менеджер. Есть, конечно, возможность сохранения страницы и в .html формате, но он муторный: вам придется найти пункт , скопировать весь код и создать вручную .html файл с скопированным содержимым.Инструкция
- Зайдите в настройки браузера и найдите там пункт
- Теперь нажмите , если вдруг вам захочется сохранить .html копию страницы — нажмите , скопированный текст сохраните как .html документ.
Если вы сохраните HTML код страницы — она может значительно исказиться при попытке ее открыть в оффлайн режиме, ибо сторонние .css и .js файлы не сохранятся.
Установка и использование HTTrack
Что касается портабельных версий — тут всё просто. Заходим в папку, находим такой ярлык и кликаем на него…
А вот, как установить обычную версию…
Установили. Теперь сам процесс скачивания сайта.
Выбираем русский язык. Это делается один раз. Программа попросит перезапуск — делаем.
…
…
Получили великий и могучий.
Создаём проект…
В качестве каталога лучше создать заранее отдельную папку.
Задаём параметры — очень важный момент. Помните — «Как мы лодку назовём…» — так и скачаем сайт.
Тут есть подводный камень. Максимальную скорость закачки можно и нужно выставить вручную, что и делаем…
Можно задать отключение сети или выключение компа по завершении закачки. Этот процесс не всегда быстрый. Зависит от скорости соединения и размера сайта.
Я прошляпил завершение закачки, но примерно могу сказать, что этот сайт скачался примерно за 15-20 минут и размер составил более 100 МБ.
Теперь можно просмотреть, что мы с Вами скачали…
Что тут смотреть — сайт, как сайт — более 160 статей. Отлично всё листается без подключения интернета. Что и требовалось доказать. Великолепно!
Если закачка прервалась — её всегда можно обновить или продолжить…
На флешку нужно переносить всю папку или только…
Тоже будет работать.
А для запуска на другом компьютере заходим в эту папку и кликаем…
Инструкция по использованию HTTrack: создание зеркал сайтов, клонирование страницы входа
С программой HTTrack вы можете создать копию сайта у себя на диске. Программа доступна для всех популярных платформ, посмотреть подробности об установке на разные системы, о графическом интерфейсе и ознакомиться со всеми опциями вы можете на странице https://kali.tools/?p=1198.
Далее я рассмотрю несколько примеров использования HTTrack с уклоном на пентестинг.
В плане пентестинга HTTrack может быть полезна для:
- исследования структуры сайта (подкаталоги, страницы сайта)
- поиск файлов на сайте (документы, изображения)
- поиск по документам и метаданным файлов с сайта
- клонирование страниц входа с целью последующего использования для фишинга
Создадим директорию, где мы будем сохранять скаченные зеркала сайтов:
mkdir websitesmirrors
Посмотрим абсолютный путь до только что созданной директории:
readlink -f websitesmirrors
В моём случае это /home/mial/websitesmirrors, у вас будет какой-то другой адрес – учитывайте это и заменяйте пути в приведённых мною командах на свои.
Простейщий запуск HTTrack выглядит так:
httrack адрес_сайта -O «путь/до/папки/зеркала»
Здесь:
- адрес_сайта – сайт, зеркало которого нужно сохранить на диск
- путь/до/папки/зеркала – папка, куда будет сохранён скаченный сайт
Я бы рекомендовал с каждым запуском программы использовать опцию -F, после которой указывать пользовательский агент:
httrack адрес_сайта -F «User Agent» -O «путь/до/папки/зеркала»
Списки строк User Agent я смотрю .
Пример запуска:
httrack https://z-oleg.com/ -F «Mozilla/5.0 (Windows NT 6.1) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/41.0.2228.0 Safari/537.36» -O «/home/mial/websitesmirrors/z-oleg.com»
Этой командой будет сделано локальное зеркало сайта с сохранением его оригинальной структуры папок и файлов.
Если вы хотите сосредоточится на файлах (документы, изображения), а не на структуре сайта, то обратите внимание на опцию -N4: все HTML страницы будут помещены в web/, изображения/другое в web/xxx, где xxx это расширения файлов (все gif будут помещены в web/gif, а .doc в web/doc)
Пример запуска с опцией -N4:
httrack https://thailandcer.ru/ -N4 -F «Mozilla/5.0 (Windows NT 6.1) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/41.0.2228.0 Safari/537.36» -O «/home/mial/websitesmirrors/thailandcer.ru/»
По умолчанию HTTrack учитывает содержимое файла robots.txt, т.е. если он запрещает доступ к папкам, документам и файлам, то HTTrack не пытается туда зайти. Для игнорирования содержимого robots.txt используется опция -s0
Пример запуска с опцией -s0:
httrack https://spryt.ru/ -s0 -N4 -F «Mozilla/5.0 (Windows NT 6.1) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/41.0.2228.0 Safari/537.36» -O «/home/mial/websitesmirrors/spryt.ru/»
Для обновления уже созданного зеркала можно использовать сокращённую опцию —update, которая означает обновить зеркало, без подтверждения и которая равнозначна двум опциям -iC2.
Для продолжения создания зеркала, если процесс был прерван, можно использовать сокращённую опцию —continue (означает продолжить зеркало, без подтверждения), либо эквивалентные опции -iC1.