String.prototype.repeat()
Содержание:
Изображения
СлайдшоуГалерея слайдшоуМодальные изображенияЛайтбоксАдаптивная сетка изображенияСетка изображенияГалерея изображений с вкладкамиНаложение при наведении курсора на изображениеСлайд наложенного изображенияZoom наложенного изображенияTitle наложенного изображенияИконка наложенного изображенияЭффекты изображенияЧерное и белое изображениеПозиция текста над изображениемТекстовые блоки над изображениемИзображение с прозрачным текстомФоновое изображение на всю страницуФорма на изображенииИмидж герояРазмытое фоновое изображение на всю страницуИзменение фона при прокруткеИзображения друг за другомОкруглые изображенияИзображения аватарыАдаптивные изображенияЦентрирование изображенийЭскизы изображенийПредставление команды на страницеЛипкое изображениеОтразить изображениеВстряхнуть изображениеГалерея портфолиоПортфолио с фильтрациейZoom изображенияУвеличительное стекло на изображенииСлайдер сравнения изображений
Извлечение части строки
Подстроки
Эти методы принимают индекс первого символа, который вы хотите извлечь из строки.
Они возвращают все от этого символа до конца строки:
"I am Groot!".slice(5) // "Groot!" "I am Groot!".substring(5) // Groot!
Второй (необязательный) аргумент — это символ, на котором вы хотите остановиться.
Этот последний символ не включается в вывод:
// Извлечь новую строку с 5-го символа, // до (но не включая!) 10-го символа "I am Groot!".slice(5, 10) // "Groot" "I am Groot!".substring(5, 10) // "Groot"
Итак, какой из них вы должны использовать?
Они очень похожи, но с небольшими отличиями:
- Если конечное значение выше начального, «исправит» их, заменив их местами, но просто вернет пустую строку.
- обрабатывает отрицательный индекс как 0. Со вы можете использовать отрицательное число для обратного отсчета от конца строки. Например, вернет последние 3 символа строки.
Также существует метод , похожий на и .
Это . Хотя вряд ли он будет использоваться в ближайшее время, для работы со строками в JavaScript вам следует использовать один из двух вышеупомянутых методов, где это возможно.
Одиночные символы
Метод возвращает определенный символ из строки (помните, что индексы начинаются с 0):
"Hello".charAt(1) // "e"
Вы также можете рассматривать строку как массив и обращаться к ней напрямую следующим образом:
"Hello" // e
Доступ к строке как к массиву может привести к путанице, когда строка хранится в переменной.
Использование более явное:
// Что такое 'someVariable'? let result = someVariable // 'someVariable' - точно строка let result = someVariable.charAt(1)
Улучшена поддержка юникода
Внутренняя кодировка строк в JavaScript – это UTF-16, то есть под каждый символ отводится ровно два байта.
Но под всевозможные символы всех языков мира 2 байт не хватает. Поэтому бывает так, что одному символу языка соответствует два юникодных символа (итого 4 байта). Такое сочетание называют «суррогатной парой».
Самый частый пример суррогатной пары, который можно встретить в литературе – это китайские иероглифы.
Заметим, однако, что не всякий китайский иероглиф – суррогатная пара. Существенная часть «основного» юникод-диапазона как раз отдана под китайский язык, поэтому некоторые иероглифы – которые в неё «влезли» – представляются одним юникод-символом, а те, которые не поместились (реже используемые) – двумя.
Например:
В тексте выше для первого иероглифа есть отдельный юникод-символ, и поэтому длина строки , а для второго используется суррогатная пара. Соответственно, длина – .
Китайскими иероглифами суррогатные пары, естественно, не ограничиваются.
Ими представлены редкие математические символы, а также некоторые символы для эмоций, к примеру:
В современный JavaScript добавлены методы String.fromCodePoint и str.codePointAt – аналоги и , корректно работающие с суррогатными парами.
Например, считает суррогатную пару двумя разными символами и возвращает код каждой:
…В то время как возвращает его Unicode-код суррогатной пары правильно:
Метод корректно создаёт строку из «длинного кода», в отличие от старого .
Например:
Более старый метод в последней строке дал неверный результат, так как он берёт только первые два байта от числа и создаёт символ из них, а остальные отбрасывает.
Есть и ещё синтаксическое улучшение для больших Unicode-кодов.
В JavaScript-строках давно можно вставлять символы по Unicode-коду, вот так:
Синтаксис: , где – четырёхзначный шестнадцатиричный код, причём он должен быть ровно четырёхзначным.
«Лишние» цифры уже не войдут в код, например:
Чтобы вводить более длинные коды символов, добавили запись , где – максимально восьмизначный (но можно и меньше цифр) код.
Например:
Во многих языках есть символы, которые получаются как сочетание основного символа и какого-то значка над ним или под ним.
Например, на основе обычного символа существуют символы: . Самые часто встречающиеся подобные сочетания имеют отдельный юникодный код. Но отнюдь не все.
Для генерации произвольных сочетаний используются несколько юникодных символов: основа и один или несколько значков.
Например, если после символа идёт символ «точка сверху» (код ), то показано это будет как «S с точкой сверху» .
Если нужен ещё значок над той же буквой (или под ней) – без проблем. Просто добавляем соответствующий символ.
К примеру, если добавить символ «точка снизу» (код ), то будет «S с двумя точками сверху и снизу» .
Пример этого символа в JavaScript-строке:
Такая возможность добавить произвольной букве нужные значки, с одной стороны, необходима, а с другой стороны – возникает проблемка: можно представить одинаковый с точки зрения визуального отображения и интерпретации символ – разными сочетаниями Unicode-кодов.
Вот пример:
В первой строке после основы идёт сначала значок «верхняя точка», а потом – нижняя, во второй – наоборот. По кодам строки не равны друг другу. Но символ задают один и тот же.
С целью разрешить эту ситуацию, существует юникодная нормализация, при которой строки приводятся к единому, «нормальному», виду.
В современном JavaScript это делает метод str.normalize().
Забавно, что в данной конкретной ситуации приведёт последовательность из трёх символов к одному: \u1e68 (S с двумя точками).
Это, конечно, не всегда так, просто в данном случае оказалось, что именно такой символ в юникоде уже есть. Если добавить значков, то нормализация уже даст несколько символов.
Для большинства практических задач информации, данной выше, должно быть вполне достаточно, но если хочется более подробно ознакомиться с вариантами и правилами нормализации – они описаны в приложении к стандарту юникод Unicode Normalization Forms.
Разбиение строк
JavaScript предоставляет метод для разбиения строк по символу и создания нового массива из полученных частей. Мы используем метод split(), чтобы разбить строку на массив по символу пробела, который представлен строкой » «.
constoriginalString = "How are you?";
// Разбиваемстрокупопробелу
const splitString = originalString.split(" ");
console.log(splitString);
Вывод
Теперь, когда у нас есть новый массив в переменной splitString, можно получить доступ к каждой его части по индексу.
splitString; Вывод are
Если методу split() передана пустая строка, он создаст массив из всех отдельных символов строки. При помощи разбиения строк можно определить количество слов в предложении.
Создание строк
По сути, в JavaScript есть две категории строк: строковые примитивы и объекты String.
Примитивы
Строковые примитивы создаются следующими способами:
let example1 = "BaseClass"
// или
let example2 = String("BaseClass")
Почти во всех случаях вы должны использовать один из этих методов для создания новой строки.
При определении строкового литерала можно использовать одинарные кавычки () или двойные кавычки ().
Объекты
Вы можете создать объект String, используя ключевое слово .
Единственное реальное преимущество объекта перед строковым примитивом состоит в том, что вы можете назначить ему дополнительные свойства:
let website = new String("BaseClass")
website.rating = "great!"
Однако очень мало случаев, когда это полезно. Практически во всех случаях следует создавать строковый примитив.
Все знакомые вам методы строк являются частью объекта String, а не примитива.
Когда вы вызываете метод для строкового примитива, JavaScript оборачивает примитив в String-объект и вызывает метод этого объекта.
Объединение
Рассмотрим основные аспекты, связанные с объединением строк и строковых переменных.
Стандартный способ:
let s1 = ‘Hello’;
let s2 = ‘world’;
let s3 = s1 + s2 + ‘!’;
console.log(s3); // Hello world!
Вместо одинарных кавычек можно использовать двойные. Кроме этого, кавычки внутри строки можно экранировать обратным слешем.
let s1 = «It’s string»;
let s2 = ‘It\’s string’;
Применяется в JavaScript и ещё один тип кавычек — обратные. Их использование позволяет размещать переменные прямо внутри строки.
let s1 = ‘Hello’;
let s2 = ‘world’;
let s3 = `${s1} ${s2}!`;
console.log(s3); // Hello world!
Ещё один способ объединения — использовать функцию «concat».
let s1 = ‘Hello’;
let s2 = ‘world’;
let s3 = s1.concat(‘ ‘, s2, ‘!’);
console.log(s3); // Hello world!
Здесь в переменную «s3», будет присваиваться значение переменной «s1», объедененное с пробелом, «s2» и восклицательным знаком
Важно, значение «s1» не изменится
Меню поиска/фильтра
Как искать ссылки в меню навигации:
Содержимое страницы
Начните вводить для определенной категории/ссылки в строке поиска, чтобы «отфильтровать» параметры поиска.
Какой-то непонятный текст Lorem ipsum dolor sit amet, consectetur adipisicing elit. Debitis, maiores. Voluptas quibusdam eveniet, corrupti numquam, consequatur illum corporis assumenda veniam ad adipisci aliquid rem nostrum repellat, nisi, iste totam nemo!
Some text..
Пример
<input type=»text» id=»mySearch» onkeyup=»myFunction()» placeholder=»Search..»
title=»Type in a category»><ul id=»myMenu»> <li><a href=»#»>HTML</a></li>
<li><a href=»#»>CSS</a></li> <li><a href=»#»>JavaScript</a></li>
<li><a href=»#»>PHP</a></li> <li><a href=»#»>Python</a></li>
<li><a href=»#»>jQuery</a></li> <li><a href=»#»>SQL</a></li>
<li><a href=»#»>Bootstrap</a></li> <li><a href=»#»>Node.js</a></li>
</ul>
Примечание: Мы используем href=»#» в этой демонстрации, поскольку у нас нет страницы для ссылки на неё. В реальной жизни это должен быть реальный URL для конкретной страницы.
Шаг 2) Добавить CSS:
Стиль окна поиска и меню навигации:
Пример
/* Стиль окна поиска */#mySearch { width: 100%;
font-size: 18px; padding: 11px; border: 1px solid #ddd;
}/* Стиль меню навигации */#myMenu { list-style-type: none;
padding: 0; margin: 0;}/* Стиль навигационных ссылок */
#myMenu li a { padding: 12px;
text-decoration: none; color: black;
display: block}#myMenu li a:hover {
background-color: #eee;}
Шаг 3) Добавить JavaScript:
Пример
<script>function myFunction() { // Объявить переменные var input, filter,
ul, li, a, i; input = document.getElementById(«mySearch»);
filter = input.value.toUpperCase(); ul =
document.getElementById(«myMenu»); li =
ul.getElementsByTagName(«li»); // Перебирайте все элементы списка и скрывайте те, которые не соответствуют поисковому запросу for (i = 0; i <
li.length; i++) { a = li.getElementsByTagName(«a»);
if (a.innerHTML.toUpperCase().indexOf(filter) > -1) {
li.style.display = «»; }
else {
li.style.display = «none»;
} }}
</script>
Совет: Удалите toUpperCase() если вы хотите выполнить поиск с учетом регистра.
Совет: Также посетите Как фильтровать таблицы.
Совет: Также посетите Как фильтровать списки.
Методы String
| Метод | Описание |
|---|---|
| charAt() | Возвращает символ строки с указанным индексом (позицией). |
| charCodeAt() | Возвращает числовое значение Unicode символа, индекс которого был передан методу в качестве аргумента. |
| concat() | Возвращает строку, содержащую результат объединения двух и более предоставленных строк. |
| fromCharCode() | Возвращает строку, созданную с помощью указанной последовательности значений символов Unicode. |
| indexOf() | Возвращает позицию первого символа первого вхождения указанной подстроки в строке. |
| lastIndexOf() | Возвращает позицию последнего найденного вхождения подстроки или -1, если подстрока не найдена. |
| localeCompare() | Возвращает значение, указывающее, эквивалентны ли две строки в текущем языковом стандарте. |
| match() | Ищет строку, используя предоставленный шаблон регулярного выражения, и возвращает результат в виде массива. Если совпадений не найдено, метод возвращает значение null. |
| replace() | Ищет строку для указанного значения или регулярного выражения и возвращает новую строку, где указанные значения будут заменены. Метод не изменяет строку, для которой он вызывается. |
| search() | Возвращает позицию первого соответствия указанной подстроки или регулярного выражения в строке. |
| slice() | Позволяет извлечь подстроку из строки. Первый аргумент указывает индекс с которого нужно начать извлечение. Второй необязательный аргумент указывает позицию, на которой должно остановиться извлечение. Если второй аргумент не указан, то извлечено будет все с той позиции, которую указывает первый аргумент, и до конца строки. |
| split() | Разбивает строку на подстроки, возвращая массив подстрок. В качестве аргумента можно передать символ разделитель (например запятую), используемый для разбора строки на подстроки. |
| substr() | Позволяет извлечь подстроку из строки. Первый аргумент указывает индекс с которого нужно начать извлечение. Второй аргумент указывает количество символов, которое нужно извлечь. |
| substring() | Извлекает символы из строки между двух указанных индексов, если указан только один аргумент, то извлекаются символы от первого индекса и до конца строки. |
| toLocaleLowerCase() | Преобразует символы строки в нижний регистр с учетом текущего языкового стандарта. |
| toLocaleUpperCase() | Преобразует символы строки в верхний регистр с учетом текущего языкового стандарта. |
| toLowerCase() | Конвертирует все символы строки в нижний регистр и возвращает измененную строку. |
| toString() | Возвращает строковое представление объекта. |
| toUpperCase() | Конвертирует все символы строки в верхний регистр и возвращает измененную строку. |
| trim() | Удаляет пробелы в начале и конце строки и возвращает измененную строку. |
| valueOf() | Возвращает примитивное значение объекта. |
Виды строк в JavaScript
В JavaScript есть два вида строк: примитивные и объекты String. Давайте инициализируем оба типа строк и выведем их тип с помощью typeof:
//Инициализация примитивной строки const primitiveString = ‘Hello world! Im fine’; //Инициализация string object const objectString = new String(primitiveString); console.log(typeof primitiveString); // выведет 'string' console.log(typeof objectString); // выведет 'object'
Как правило, на практике используется примитивный тип строк, так как JavaScript может использовать свойства и методы объекта String без преобразования примитивной строки в object-строку.
Сравнение строк
Равенство
Как вы знаете, что сравнивая два строковых примитива, вы можете использовать операторы == или ===:
Если вы сравниваете строковый примитив с чем-то, что не является строкой, == и === ведут себя по-разному.
При использовании оператора == не-строка будет преобразована в строку. Это означает, что JavaScript попытается преобразовать его в строку перед сравнением значений.
Для строгого сравнения, когда не-строки не приводятся к строкам, используйте ===:
То же самое верно и для операторов неравенства != и !==:
Если вы не знаете, что использовать, отдавайте предпочтение строгому равенству ===.
Чувствительность к регистру
Когда требуется сравнение без учета регистра, обычно преобразуют обе строки в верхний или нижний регистры и сравнивают результат.
Однако иногда вам нужно больше контроля над сравнением. Об этом в следующем разделе …
Работа с диакритическими знаками в строках JavaScript
Диакритические знаки — это модификации буквы, например é или ž.
Возможно вы захотите указать, как они обрабатываются при сравнении двух строк.
Например, в некоторых языках принято исключать акценты при написании прописных букв.
Если вам нужно сравнение без учета регистра, простое преобразование двух строк в один и тот же регистр с помощью toUpperCase() или toLowerCase() не будет учитывать добавление / удаление акцентов и может не дать ожидаемого результата.
Если вам нужен более точный контроль над сравнением, используйте вместо него localeCompare:
Метод localeCompare позволяет указать «sensitivity» сравнения.
Здесь мы использовали base «sensitivity» для сравнения строк с использованием их «базовых» символов (что означает, что регистр и акценты игнорируются).
Поддержка localeCompare() браузерами:
Chrome: 24+
Edge: 12+
Firefox: 29+
Safari: 10+
Opera: 15+
Больше / меньше
При сравнении строк с использованием операторов < и > JavaScript будет сравнивать каждый символ в «лексикографическом порядке».
Это означает, что они сравниваются по буквам в том порядке, в котором они появляются в словаре:
True или false строки
Пустые строки в JavaScript считаются равными false при сравнении с использованием оператора == (но не при использовании ===)
Строки со значением являются «истинными», поэтому вы можете делать нечто подобное:
replace()
Этот метод находит первое упоминание в заданной строке и заменяет его на .
Отдаёт новую строку, не трогая оригинальную.
Вы можете передать регулярное выражение как первый аргумент:
заменяет только первое упоминание, но а если вы будете использовать regex как поиск строки, то вы можете использовать ():
Второй параметр может быть функцией. Эта функция будет вызвана с заданным количеством аргументов, когда найдётся совпадение (или каждое совпадение в случае с regex ):
- Нужная строка
- Целое число, которое указывает позицию в строке, где произошло совпадение
- Строка
Отдающееся значение функции заменит совпадающую часть строки.
Пример:
Это работает и для обычных строк, а не только для регулярок:
В случае c regex, когда выбираются группы, все эти значения будут переданы как аргументы прямо после параметра совпадения.
Строковые методы, поиск и замена
Следующие методы работают с регулярными выражениями из строк.
Все методы, кроме replace, можно вызывать как с объектами типа regexp в аргументах, так и со строками, которые автоматом преобразуются в объекты RegExp.
Так что вызовы эквивалентны:
var i = str.search(/\s/)
var i = str.search("\\s")
При использовании кавычек нужно дублировать \ и нет возможности указать флаги. Если регулярное выражение уже задано строкой, то бывает удобна и полная форма
var regText = "\\s" var i = str.search(new RegExp(regText, "g"))
Возвращает индекс регулярного выражения в строке, или -1.
Если Вы хотите знать, подходит ли строка под регулярное выражение, используйте метод (аналогично RegExp-методы ). Чтобы получить больше информации, используйте более медленный метод (аналогичный методу ).
Этот пример выводит сообщение, в зависимости от того, подходит ли строка под регулярное выражение.
function testinput(re, str){
if (str.search(re) != -1)
midstring = " contains ";
else
midstring = " does not contain ";
document.write (str + midstring + re.source);
}
Если в regexp нет флага , то возвращает тот же результат, что .
Если в regexp есть флаг , то возвращает массив со всеми совпадениями.
Чтобы просто узнать, подходит ли строка под регулярное выражение , используйте .
Если Вы хотите получить первый результат — попробуйте r.
В следующем примере используется, чтобы найти «Chapter», за которой следует 1 или более цифр, а затем цифры, разделенные точкой. В регулярном выражении есть флаг , так что регистр будет игнорироваться.
str = "For more information, see Chapter 3.4.5.1"; re = /chapter (\d+(\.\d)*)/i; found = str.match(re); alert(found);
Скрипт выдаст массив из совпадений:
- Chapter 3.4.5.1 — полностью совпавшая строка
- 3.4.5.1 — первая скобка
- .1 — внутренняя скобка
Следующий пример демонстрирует использование флагов глобального и регистронезависимого поиска с . Будут найдены все буквы от А до Е и от а до е, каждая — в отдельном элементе массива.
var str = "ABCDEFGHIJKLMNOPQRSTUVWXYZabcdefghijklmnopqrstuvwxyz"; var regexp = //gi; var matches = str.match(regexp); document.write(matches); // matches =
Метод replace может заменять вхождения регулярного выражения не только на строку, но и на результат выполнения функции. Его полный синтаксис — такой:
var newString = str.replace(regexp/substr, newSubStr/function)
- Объект RegExp. Его вхождения будут заменены на значение, которое вернет параметр номер 2
- Строка, которая будет заменена на .
- Строка, которая заменяет подстроку из аргумента номер 1.
- Функция, которая может быть вызвана для генерации новой подстроки (чтобы подставить ее вместо подстроки, полученной из аргумента 1).
Метод не меняет строку, на которой вызван, а просто возвращает новую, измененную строку.
Чтобы осуществить глобальную замену, включите в регулярное выражение флаг .
Если первый аргумент — строка, то она не преобразуется в регулярное выражение, так что, например,
var ab = "a b".replace("\\s","..") // = "a b"
Вызов replace оставил строку без изменения, т.к искал не регулярное выражение , а строку «\s».
В строке замены могут быть такие спецсимволы:
| Pattern | Inserts |
| Вставляет «$». | |
| Вставляет найденную подстроку. | |
| Вставляет часть строки, которая предшествует найденному вхождению. | |
| Вставляет часть строки, которая идет после найденного вхождения. | |
| or | Где или — десятичные цифры, вставляет подстроку вхождения, запомненную -й вложенной скобкой, если первый аргумент — объект RegExp. |
Если Вы указываете вторым параметром функцию, то она выполняется при каждом совпадении.
В функции можно динамически генерировать и возвращать строку подстановки.
Первый параметр функции — найденная подстрока. Если первым аргументом является объект , то следующие параметров содержат совпадения из вложенных скобок. Последние два параметра — позиция в строке, на которой произошло совпадение и сама строка.
Например, следующий вызов возвратит XXzzzz — XX , zzzz.
function replacer(str, p1, p2, offset, s)
{
return str + " - " + p1 + " , " + p2;
}
var newString = "XXzzzz".replace(/(X*)(z*)/, replacer)
Как видите, тут две скобки в регулярном выражении, и потому в функции два параметра , .
Если бы были три скобки, то в функцию пришлось бы добавить параметр .
Следующая функция заменяет слова типа на :
function styleHyphenFormat(propertyName)
{
function upperToHyphenLower(match)
{
return '-' + match.toLowerCase();
}
return propertyName.replace(//, upperToHyphenLower);
}
Свойства строк
| Свойство | Описание | |
|---|---|---|
| constructor | возвращает функцию-конструктор строки | |
|
var str = «Hello world!»;
|
||
| length | возвращает длину (количество символов) строки | |
|
var str = «Hello world!»;
|
||
| prototype | позволяет добавить свойства и методы к объекту (если строка — объект) | |
|
function student(name, surname, faculty) {
|
Добавление/удаление элементов
Мы уже знаем методы, которые добавляют и удаляют элементы из начала или конца:
- – добавляет элементы в конец,
- – извлекает элемент из конца,
- – извлекает элемент из начала,
- – добавляет элементы в начало.
Есть и другие.
Как удалить элемент из массива?
Так как массивы – это объекты, то можно попробовать :
Вроде бы, элемент и был удалён, но при проверке оказывается, что массив всё ещё имеет 3 элемента .
Это нормально, потому что всё, что делает – это удаляет значение с данным ключом . Это нормально для объектов, но для массивов мы обычно хотим, чтобы оставшиеся элементы сдвинулись и заняли освободившееся место. Мы ждём, что массив станет короче.
Поэтому для этого нужно использовать специальные методы.
Метод arr.splice(str) – это универсальный «швейцарский нож» для работы с массивами. Умеет всё: добавлять, удалять и заменять элементы.
Его синтаксис:
Он начинает с позиции , удаляет элементов и вставляет на их место. Возвращает массив из удалённых элементов.
Этот метод проще всего понять, рассмотрев примеры.
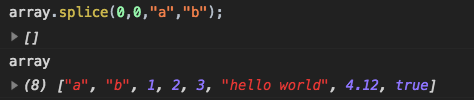
Начнём с удаления:
Легко, правда? Начиная с позиции , он убрал элемент.
В следующем примере мы удалим 3 элемента и заменим их двумя другими.
Здесь видно, что возвращает массив из удалённых элементов:
Метод также может вставлять элементы без удаления, для этого достаточно установить в :
Отрицательные индексы разрешены
В этом и в других методах массива допускается использование отрицательного индекса. Он позволяет начать отсчёт элементов с конца, как тут:
Метод arr.slice намного проще, чем похожий на него .
Его синтаксис:
Он возвращает новый массив, в который копирует элементы, начиная с индекса и до (не включая ). Оба индекса и могут быть отрицательными. В таком случае отсчёт будет осуществляться с конца массива.
Это похоже на строковый метод , но вместо подстрок возвращает подмассивы.
Например:
Можно вызвать и вообще без аргументов: создаёт копию массива . Это часто используют, чтобы создать копию массива для дальнейших преобразований, которые не должны менять исходный массив.
Метод arr.concat создаёт новый массив, в который копирует данные из других массивов и дополнительные значения.
Его синтаксис:
Он принимает любое количество аргументов, которые могут быть как массивами, так и простыми значениями.
В результате мы получаем новый массив, включающий в себя элементы из , а также , и так далее…
Если аргумент – массив, то все его элементы копируются. Иначе скопируется сам аргумент.
Например:
Обычно он просто копирует элементы из массивов. Другие объекты, даже если они выглядят как массивы, добавляются как есть:
…Но если объект имеет специальное свойство , то он обрабатывается как массив: вместо него добавляются его числовые свойства.
Для корректной обработки в объекте должны быть числовые свойства и :