Data science для начинающих: обзор сферы и профессий
Содержание:
Быть Джуном Мидловичем, Д. С.
Успешная работа в Data Science требует сплава знаний из программирования, статистики и консалтинга. Вот примеры задач, которые решает дата-сайентист:
- оценка потребностей заказчика;
- отбор данных для анализа;
- загрузка данных в среду разработки;
- удаление выбросов и обогащение данных;
- выбор и настройка модели;
- интерпретация результатов работы модели.
Настоящий специалист решает задачи согласованно и с учётом их взаимного влияния, а не по отдельности — «сферически в вакууме».

Эти сложные взаимосвязи рабочих задач дата-сайентиста порождают цепочки верхнеуровневых вопросов. Например:
- Как заполнить пропущенные значения в данных, исходя из особенностей бизнеса и потребностей заказчика?
- Какие параметры выбрать у моделей, если пропущенные значения заполнены тем или иным способом?
- Почему модель выдаёт странные результаты: я выбрал не те параметры, не разобрался в отрасли или просто не понял заказчика?
Какая нужна математика? Если нет матбазы, я безнадёжен?

Константин башевой
Аналитик-разработчик в Яндексе и преподаватель курса «Python для анализа данных»
Вопрос про математику неоднозначный. Глубокое знание математики не является ни необходимым, ни достаточным условием. Конечно, тому, кто её знает, будет легче. Но все необходимые знания даются либо на занятиях, либо в дополнительных материалах.
Здесь как в спорте. Есть люди, которые могут без подготовки пробежать марафон. Остальным будет тяжелее, но при достаточной подготовке и они пробегут. Математическая база — это круто, но не критически необходимо.

Дарья Мухина
Продуктовый аналитик Skyeng, консультант курсов аналитики Нетологии
Кажется, что сейчас глубокую математическую базу можно заменить умением гуглить. В интернете огромное количество видео и статей, где можно получить доступно изложенную информацию — и не нужно лезть в университетские учебники. Главное знать, что тебе нужно.
Сейчас важнее навык применять знания в реальной задаче, а не просто обладать ими.
Елена Герасимова
Руководитель направления Data Science в Нетологии
Понятие «профильное техническое или математическое образование» уходит в прошлое. Уверенного в своих умениях и доменных знаниях специалиста из «гуманитарного» вуза не будут сравнивать с выпускником МФТИ по знанию математики — сравнивают по полезности бизнесу для решения задач.
Уже известны десятки рабочих алгоритмов и библиотек, которые способны всю математическую часть брать на себя без участия человека.
Ссылки на интересные материалы
Ссылки на интересные материалы, касающиеся профессии дата-сайентиста:
- “Кто такой Data Scientist глазами работодателя” — интервью с Авито и Spice IT;
- Интересная статья “Как стать датасайнтистом, если тебе за 40 и ты не программист”;
- Статья “Дорога в Data Science глазами новичка” на Пикабу;
- Авторская статья “Как стать Data Scientist в 2019 году”;
- Интересный материал “Рутина дата-сайентистов. Про их рабочий день и нужные навыки”;
- Занимательная глава из книги “Наука данных. Базовый курс”, посвященная истории профессии;
- Ретроспектива автора на Хабре о том, каково это было — изучать дата сайнс в 2019 году;
- Статья “Один день из жизни дата-сайентиста”, написанная в 2018 году;
- История дата-сайентиста Саши, написанная простым языком;
- Несколько историй о том, как гуманитарии стали специалистами в работе с данными.
Эта профессия как минимум входит в число самых перспективных, поэтому в последние годы многие с удовольствием изучают data science. Конечно, как и в других отраслях, здесь есть свои недостатки и трудности, которые особенно заметны в начале обучения, но при должном старании любой сможет пополнить ряды ученого по данным. Так что дерзайте!
Самое приятное в работе
Пожалуй, ощущение, когда ты находишь решение сложной или просто утомительной задачи.
Например, мы не могли автоматизировать поиск нужной области с целевыми объектами на фотографиях. С командой бились несколько месяцев над этой проблемой, пытаясь реализовать это с помощью классического компьютерного зрения. Учитывая требование клиента сделать решение, работающее на ЦПУ, мы изначально отказались от создания нейросети. Опасались, что она получится тяжёлой и будет долго исполняться. Но всё равно пришли к выводу многих коллег: «Есть проблема — пиши сетку». За один день собрались, разметили данные, написали рабочий прототип, который показал свою эффективность. Получилось быстрое решение за счёт раздувания объёма памяти, но RAM, в отличие от VRAM, можно легко увеличить. В итоге, вместо месяца мы сделали рабочий прототип за один день (и немного ночи).
Соберем данные
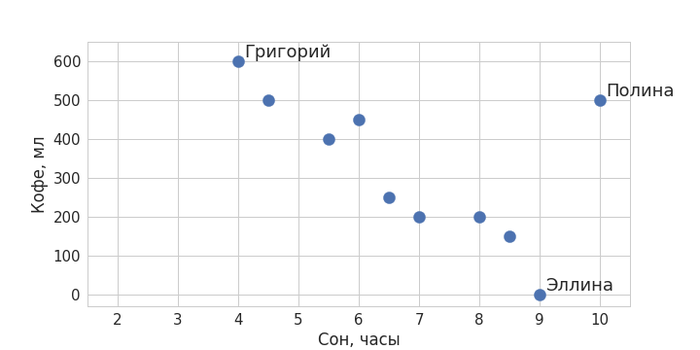
Чтобы не быть голословным, я приведу простой пример. Соберем какие-нибудь данные.
Представьте, что нас интересует, есть ли какая-то взаимосвязь между тем, сколько ваши коллеги по работе выпивают кофе за день, и тем, сколько они спали накануне. Запишем доступную нам информацию: допустим, ваш коллега Григорий сегодня спал 4 часа, так что ему пришлось выпить 3 чашки кофе; Эллина спала 9 часов и не пила кофе вообще; а Полина спала все 10 часов, но выпила 2,5 чашки кофе – и так далее.
Изобразим полученные данные на графике (визуализация – тоже немаловажный элемент любого data science-проекта). Отложим по оси X время в часах, а по оси Y – кофе в миллилитрах. Получим что-то вроде такого:
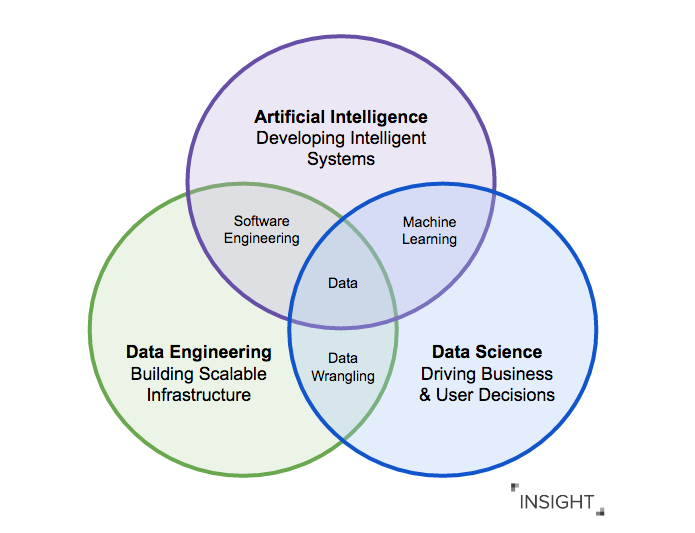
Как различаются роли дата-инженеров и дата-сайентистов
Инженер данных — это специалист, который, с одной стороны, разрабатывает, тестирует и поддерживает инфраструктуру работы с данными: базы данных, хранилища и системы массовой обработки. С другой стороны, дата-инженер очищает и «причёсывает» данные для использования аналитиками и дата-сайентистами, то есть создаёт конвейеры обработки данных.
Дата-сайентист создаёт и обучает предиктивные (и не только) модели с помощью алгоритмов машинного обучения и нейросетей, помогая бизнесу находить скрытые закономерности, прогнозировать развитие событий и оптимизировать ключевые бизнес-процессы.
Главное различие между Data Scientist и Data Engineer состоит в том, что обычно у них разные цели. Оба работают для того, чтобы данные были доступными и качественными. Если дата-сайентист находит ответы на свои вопросы и проверяет гипотезы в экосистеме данных (например, на базе Hadoop), то дата-инженер создаёт пайплайн обслуживания алгоритма машинного обучения, написанного дата-сайентистом, в кластере Spark внутри той же экосистемы.
Инженер данных приносит ценность бизнесу, работая в команде. Он выступает важным звеном между различными участниками: от разработчиков до бизнес-потребителей отчетности. Также помогает повысить продуктивность аналитиков — от маркетинговых и продуктовых до BI.
Дата-сайентист принимает активное участие в стратегии компании и извлечении инсайтов, принятии решений, внедрении алгоритмов автоматизации, моделирования и генерации ценности из данных.
Работа с данными подчиняется принципу GIGO (garbage in — garbage out): если аналитики и дата-сайентисты имеют дело с неподготовленными и потенциально некорректными данными, то результаты даже с помощью самых изощрённых алгоритмов анализа будут неверны.
Инженеры данных решают эту проблему, выстраивая пайплайны по обработке, очистке и трансформации данных и позволяя дата-сайентисту работать уже с качественными данными.
На рынке много инструментов для работы с данными на каждом этапе: от их появления до вывода на дашборд для совета директоров
И важно, чтобы решение об их использовании принималось дата-инженером, — не потому, что это модно, а потому что он действительно поможет в работе остальным участникам процесса
Условно: если компании нужно подружить BI и ETL — загрузку данных и обновления отчётов, вот типичный legacy-фундамент, с которым придётся иметь дело Data Engineer (хорошо, если в команде кроме него будет ещё и архитектор).
Обязанности Data Engineer
- Разработка, построение и обслуживание инфраструктуры работы с данными.
- Обработка ошибок и создание надёжных конвейеров обработки данных.
- Приведение неструктурированных данных из различных динамических источников к виду, необходимому для работы аналитиков.
- Предоставление рекомендаций по повышению консистентности и качества данных.
- Обеспечение и поддержка архитектуры данных, используемой дата- сайентистами и аналитиками данных.
- Обработка и хранение данных последовательно и эффективно в распределённом кластере на десятки или сотни серверов.
- Оценка технических компромиссов инструментов для создания простых, но надёжных архитектур, которые смогут пережить сбои.
- Контроль и поддержка потоков данных и связанных систем (настройка мониторинга и алертов).
Как он это делает?
Задачи аналитику ставит владелец продукта или проектный менеджер. Например, разработать и внедрить какую-то модель на производстве. Владелец продукта оценивает сложность задачи и собирает необходимую для решения команду: дата-сайентист, фронтенд- и бэкенд-разработчики, дизайнер и так далее. Специалистов каждой специальности может быть несколько, а может и ни одного, в зависимости от задачи и предполагаемого решения.
Расскажу, как мы в СИБУРе строим модель. Допустим, мы хотим предсказать факт брака детали по данным с датчиков на производстве.

- Первый этап — сбор данных. Аналитик готовит данные для анализа: выгружает из различных источников, обрабатывает пропуски в данных (значения, которые должны быть, но отсутствуют). На выходе получается таблица.
- Второй этап — предварительный анализ. Бывает полезно нарисовать разные графики и внимательно их изучить. В шутку некоторые аналитики называют это методом «пристального взгляда». Это может дать интересные соображения, помочь выявить странности и много чего еще, что поможет в решении задачи.
- Третий этап — построение признакового описания. Поясню, что это. У нас уже есть таблица с данными от датчиков, но в большинстве случаев этого мало. Необходимо самостоятельно рассчитать некоторые величины, которые могут помочь классифицировать деталь как бракованную.
Например, может быть недостаточно измерить температуру в разных точках детали датчиками. Есть смысл рассчитать среднее арифметическое по всем этим датчикам, а также максимальную, минимальную температуру, разброс температур и много чего еще.
Таким образом, рассчитывая и добавляя новые величины, мы расширяем признаковое описание нашей детали. Именно это описание (набор чисел для каждой детали) мы используем для построения модели. В нашем примере моделью будет являться некоторый алгоритм, который пытается восстановить зависимость между признаковым описанием детали и ответом (есть брак или нет).
В итоге модель обычно представляет из себя код, который может прочитать данные (например, из таблицы Excel или из базы данных), построить предсказания и записать результат (опять-таки в таблицу или базу данных).
Но в таком виде модель еще нельзя считать законченной. Модель должна быть внедрена и работать у заказчика.

Если говорить о конкретных проектах, в которых я принимал участие в СИБУРе, то первой была задача разработки модели для производства изобутилена, которая должна была предсказывать коксование. На решетках реактора образуются углеродные отложения, которые могут решетки повредить.
Помимо самой модели, необходимо было сделать визуализацию предсказаний, которая должна обновляться в реальном времени после каждого пересчета предсказаний, а также реализовать регулярную загрузку актуальных данных в базу для расчета предсказаний. Этой задачей я занимался один, при этом периодически пользовался помощью коллег в некоторых вопросах, связанных с производственной системой хранения данных.
В этом проекте я выступаю уже больше как архитектор и разработчик фреймворка, отвечающего за все вычисления. В то время как мой коллега, тоже аналитик данных, но с профильным химическим образованием, больше решает задачи моделирования, в том числе с использованием химии и физики, хотя это разделение обязанностей весьма условно. Также в этом проекте участвуют фронтенд-разработчики, так как визуальная часть нашего решения достаточно сложна.
Математика для анализа данных от онлайн-университета «Нетология»
Для кого
Курс для специалистов в области Data Science и аналитиков данных. Его цель — создать крепкий теоретический бэкграунд для более точного прогнозирования, интерпретации данных и выбора инструментов для эффективного решения поставленных задач.
Необходимым требованием является базовый уровень владения Python и знание библиотек NumPy, SciPy, Matplotlib.
Чему научат
Курс включает линейную алгебру, математический анализ и теорию вероятностей
Внимание акцентировано на тех знаниях, которые важны для полноценной работы с данными и применяются специалистами Data Science. Теория дается в связке с практикой: после каждой лекции идет практическое задание
Вас научат использовать различные методы оптимизации для поиска локального минимума функции, применять закон больших чисел для оценки математического ожидания и находить оптимальное решение для разных критериев, необходимое для корректной настройки модели алгоритмов. Для закрепления знаний на практике в финале курса вам необходимо будет выполнить итоговую работу: провести визуальный анализ данных и решить практическую задачу с использованием методов оптимизации функций.
Особенности
Курс проходит в форме видеолекций: 2 лекции по 1,5 часа в неделю. Посмотреть видео можно в личном кабинете в любое удобное время. Там же доступны практические задания, выполнение которых проверяет и комментирует преподаватель. В течение всего курса работает обратная связь: преподаватели отвечают на любые вопросы.
По окончанию программы выдается удостоверение о повышении квалификации. Выпускникам обещают поддержку Центра развития карьеры «Нетологии».
Проанализируем данные
Вернемся к нашему примеру. На глаз кажется, что два параметра как-то взаимосвязаны: чем меньше человек спал, тем больше он выпьет кофе на следующий день. При этом у нас есть и выбивающийся из этой тенденции пример – любительница поспать и попить кофе Полина. Тем не менее можно попытаться приблизить полученную закономерность некоторой общей прямой линией так, чтобы она максимально близко подходила ко всем точкам:
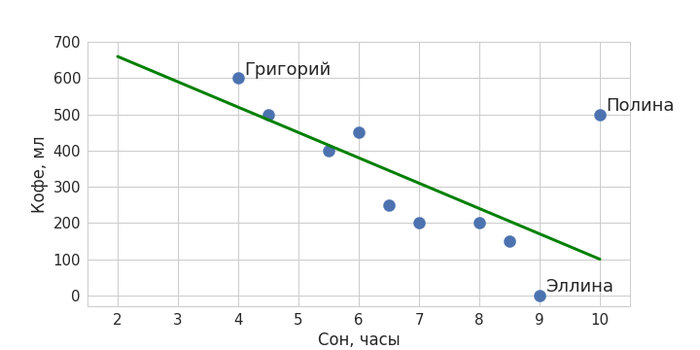
Зеленая линия – и есть наша модель машинного обучения, она обобщает данные и ее можно описать математически. Теперь с помощью нее мы можем определять значения для новых объектов: когда мы захотим предсказать, сколько кофе сегодня выпьет вошедший в кабинет Никита, мы поинтересуемся, сколько он спал. Получив в качестве ответа значение в 7,5 часов, подставим его в модель – ему соответствует количество выпитого кофе в объеме чуть менее 300 мл. Красная точка обозначает наше предсказание.
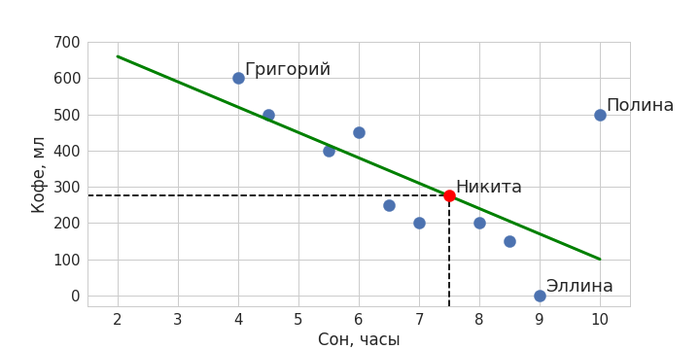
Примерно так и работает машинное обучение, идея которого очень проста: найти закономерность и распространить ее на новые данные. На самом деле, в машинном обучении выделяется еще один класс задач, когда нужно не предсказывать какие-то значения, как в нашем примере, а разбивать данные на некоторые группы. Но об этом мы подробнее поговорим в другой раз.
Машинное обучение
Во-первых, машинное обучение — часть более обширной области искусственного интеллекта. Искусственный интеллект — это термин, придуманный Джоном МакКарти в 1956 году, определяемый как «наука и технология создания интеллектуальных машин». Со временем машинное обучение в этой области становится все более значимым.
Машинное обучение можно разбить на две формы обучения: обучение с учителем (supervised) и без учителя (unsupervised).
Обучение с учителем (supervised). Большая часть прикладного машинного обучения сегодня осуществляется с помощью контролируемого обучения — обучения с учителем. Контролируемое обучение — это обучение алгоритма на данных с получением ожидаемых результатов и их последующей корректировкой пользователем, чтобы алгоритм совершенствовал точность при следующем запуске. Представьте алгоритм компьютера в роли студента, а себя в роли учителя, который корректирует его и направляет, когда это необходимо.
Обучение без учителя (unsupervised). Хотя этот тип машинного обучения имеет сейчас менее практическое применение, эта отрасль, возможно, интереснее. В неконтролируемом обучении алгоритмы оставлены сами себе, они самостоятельно обнаруживают и идентифицируют базовые структуры в данных.
Значимость в Data Science
Машинное обучение, несомненно, имеет большое значение в сегодняшней технологической картине. Тони Тейтер и Джон Хеннесси уже назвали это «следующим интернетом» и «горячей новинкой». Билл Гейтс также упомянул эту тему, заявив, что «прорыв в компьютерном обучении будет стоить десяти Microsoft».
Офлайн-курс: «Data Scientist»
Области применения вроде разработки беспилотных автомобилей, классификации изображений и распознавания речи, легко объясняют шумиху вокруг машинного обучения. Сфера растет, и растет быстро, так что прыгайте на подножку сейчас или останетесь позади.
Что почитать
7 шагов к пониманию машинного обучения — пошаговое объяснение процесса машинного обучения.Что такое машинное обучение? (англ.) — интересное обсуждение на Quora с несколькими немного отличающимися ответами, цель которых — определить машинное обучение. (англ.) — немного о том, как возникло машинное обучение.Контролируемые и неконтролируемые алгоритмы машинного обучения (англ.) — четкие, краткие объяснения типов алгоритмов машинного обучения.Визуализация машинного обучения (англ.) — мой любимый ресурс по этому вопросу. Отличная визуализация, которая позволяет вам точно понять, как используется машинное обучение.
Коммуникация
Специалист по данным проводит много времени на встречах, отвечает на письма как и большинство людей в корпоративном мире, но тут умение общаться может быть ещё более важным навыком. Во время таких встреч и переписок нужно уметь объяснять принципы DS и ML таким образом, чтобы даже дилетант мог понять наши проблемы, а мы могли понять его потребности.
Коммуникация с людьми, не погруженными в ML
Вопреки распространённому мнению, важные инструменты специалиста по данным — Word, Outlook и PowerPoint. Со стороны кажется, что ML-разработка — плавание по волнам кода и данных, но значительную часть твоего дня составляет общение: с коллегами, с заказчиком, с менеджером проекта. В конечном счёте наша работа заключается в решении проблем, а не в построении моделей.
Data Engineer with SQL (remote)
Nitka Technologies, Удалённо, По итогам собеседования
tproger.ru
Вакансии на tproger.ru
Если общение внутри коллектива программистов может идти неформально, то с заказчиком необходимо выстраивать как можно более конструктивный диалог. Самое сложное тут — донести, что некоторые пожелания неосуществимы по объективным причинам, а не потому что ты не умеешь: недостаточно данных, задача неосуществима на данном процессе/железе/фреймворке, её невозможно решить физически (например отследить определённый объект, заваленный кучей других объектов).
Был случай, когда заказчик хотел модель прогнозирования перевозок на несколько лет вперед, хотя больше половины трафика приходилось на редкие перевозки, происходившие раз в год — проще попасть пальцем в небо, чем пытаться построить модель с такими исходными.
Коммуникация с командой
Каждое утро с командой мы собираемся, чтобы распределить задачи на день. У нас горизонтальная иерархия, но так органически вышло, что я — неформальный team-lead, поэтому ко мне часто приходят за советом или просят помочь. Нужно сразу оговориться, что процесс разработки у нас не всегда идёт по Agile-методикам: для DS, особенно на ранних этапах разработки, Agile может оказаться недостаточно гибок, поэтому мы выделяем некие реперные точки, на которых собираемся и сверяем часы, например раз в неделю.
Специалисты по изучению данных (data scientist)
Специалист по Data Science — это эксперт по данным, который часто имеет высшее образование в области математики или статистики и нередко умеет программировать на R или Python. Наиболее востребованные датасайентисты также обладают знаниями в соответствующих областях бизнеса.
Хотя наборы навыков у разных людей разнятся, задача специалиста по данным состоит в том, чтобы помочь их работодателю решить сложные проблемы, часто связанные с поиском инсайтов, оптимизацией бизнес-процессов и построением предиктивных моделей. Эта роль может рассматриваться как часть ИТ, или же она может быть интегрирована в один из департаментов компании. Из всех возможных ролей, связанных с данными, датасайентисты, как правило, являются наиболее опытными экспертами.
Основные задачи Data Scientist:
- умение извлекать необходимую информацию из разнообразных источников
- использовать информационные потоки в режиме реального времени
- устанавливать скрытые закономерности в массивах данных
- статистически анализировать их для принятия грамотных бизнес-решений.
Основное отличие специалистов по изучению данных от, например, аналитиков, — это умение видеть логические связи в системе собранной информации, и на основании этого разрабатывать те или иные бизнес-решения. Специалисты по изучению данных собирают информацию, строят модели на ее основании и активно применяют количественный анализ.
Именно это редкое сочетание компетенций определяет зарплату специалиста по изучению данных: в США она составляет $110 тыс. — $140 тыс. в год. «Эта вакансия становится все более востребованной,- отмечает на страницах IT World Лора Келли (Laura Kelley), вице-президент агентства по ИТ-консалтингу и подбору персонала Modis (США). — Компании уделяют все больше внимания информации и приложениям. Им требуются специалисты, способные управлять большим количеством данных`.
Майкл Раппа (Michael Rappa), директор Института аналитики в Университете Северной Каролины, вместе со своими коллегами уже 6 лет разрабатывает курс, на котором будут готовить специалистов по изучению данных. «Эти специалисты должны уметь извлекать нужную информацию из всевозможных источников, включая информационные потоки в режиме реального времени, и анализировать ее для дальнейшего принятия бизнес-решений, — говорит он. — Дело не только в объеме обрабатываемой информации, но также в ее разнородности и скорости обновления».
Компании, которые пытаются решить эту задачу силами специалистов по статистике, компьютерных или бизнес-аналитиков, не добиваются нужного результата. Необходимо объединить все эти навыки в одном человеке. Например, бизнес-аналитики воспринимают такие показатели, как разработка и менеджмент продукта, но не способны анализировать и адекватно интерпретировать данные. Математикам и специалистам по статистике недостает знаний в области бизнеса. Именно поэтому, по мнению Раппы, специалистам по изучению данных требуется междисциплинарное образование – они должны уметь решать бизнес-проблемы и составлять информационные модели.
100% выпускников разработанного Институтом аналитики курса для специалистов по изучению данных получили предложения о работе еще до того, как завершили обучение. Раппа также отмечает, что сама специальность — специалист по изучению данных — звучит более привлекательно, чем `специалист по статистике` или `компьютерный аналитик`.
Почему Data Scientist сексуальнее, чем BI-аналитик
В связи с ростом популярности data science (DS) возникает два совершенно очевидных вопроса. Первый – в чем состоит качественное отличие этого недавно сформировавшегося научного направления от существующего несколько десятков лет и активно используемого в индустрии направления business intelligence (BI)? Второй — возможно более важный с практической точки зрения — чем различаются функции специалистов двух родственных специальностей data scientist и BI analyst? В материале, подготовленном специально для TAdviser, на эти вопросы отвечает журналист Леонид Черняк.
Кто такой Data Scientist?
Давайте начнем наше знакомство с профессией с области, в которой работают Data Scientists. Data Science – это наука о данных, которая занимается изучением данных, их анализом различными методами и последующим преобразованием данных в полезные знания. Раньше обработать данные человек мог вручную, но сейчас их количество стало настолько огромным, что для обработки часто требуется искусственный интеллект. Поэтому наука активно взаимодействует с машинным обучением, математикой, статистикой и анализом данных.
Нас постоянно окружают результаты работы Data Scientists, например, мы ежедневно смотрим прогноз погоды, реклама предлагает нам определенные товары, авиасервисы прогнозируют стоимость билетов, врачи с помощью программ могут предсказать диагнозы, а голосовые помощники выполняют множество наших просьб. Всем этим и многими другими вещами управляет специалист по данным. Data Scientist – это специалист, который занимается поиском закономерностей в больших массивах данных, анализирует и хранит их. Профессия Data Scientist считается одной из самых высокооплачиваемых и сложных в мире ИТ.
Стоит обратить внимание на то, что Data Science стала неотъемлемой частью будущего. Сейчас ее активно используют в стартапах, IT компаниях, различных бизнесах, чтобы предоставлять наиболее точные данные и прогнозы, быть ближе к пользователю, автоматизировать свои решения и повысить маржинальность бизнеса
Спрос на Data Scientists ежегодно растет. Например, по информации веб-сайта по поиску работы Indeed, за 2019 год вакансий Data Scientists стало на 29% больше.
Data Scientists постоянно ищут паттерны и тренды в огромных наборах данных, используя многообразные тулы, техники и критическое мышление, чтобы найти практическое решение для реальных data-centric проблем. Давайте подробнее поговорим о том, что входит в обязанности специалистов по данным.

Что изучает Data Science
Каждый день человечество генерирует примерно 2,5 квинтиллиона байт различных данных. Они создаются буквально при каждом клике и пролистывании страницы, не говоря уже о просмотре видео и фотографий в онлайн-сервисах и соцсетях.
Наука о данных появилась задолго до того, как их объемы превысили все мыслимые прогнозы. Отсчет принято вести с 1966 года, когда в мире появился Комитет по данным для науки и техники — CODATA. Его создали в рамках Международного совета по науке, который ставил своей целью сбор, оценку, хранение и поиск важнейших данных для решения научных и технических задач. В составе комитета работают ученые, профессора крупных университетов и представители академий наук из нескольких стран, включая Россию.
Сам термин Data Science вошел в обиход в середине 1970-х с подачи датского ученого-информатика Петера Наура. Согласно его определению, эта дисциплина изучает жизненный цикл цифровых данных от появления до использования в других областях знаний. Однако со временем это определение стало более широким и гибким.
Data Science (DS) — междисциплинарная область на стыке статистики, математики, системного анализа и машинного обучения, которая охватывает все этапы работы с данными. Она предполагает исследование и анализ сверхбольших массивов информации и ориентирована в первую очередь на получение практических результатов.
В 2010-х годах объемы данных по экспоненте. Свою роль сыграл целый ряд факторов — от повсеместного распространения мобильного интернета и популярности соцсетей до всеобщей оцифровки сервисов и процессов. В итоге профессия дата-сайентиста быстро превратилась в одну из самых популярных и востребованных. Еще в 2012 году позицию дата-сайентиста журналисты назвали самой привлекательной работой XXI века (The Sexiest Job of the XXI Century).

Объем данных, созданных, собранных и потребленных во всем мире с 2010 по 2024 год (в зеттабайтах)
(Фото: Statista)
Развитие Data Science шло вместе с внедрением технологий Big Data и анализа данных. И хотя эти области часто пересекаются, их не следует путать между собой. Все они предполагают понимание больших массивов информации. Но если аналитика данных отвечает на вопросы о прошлом (например, об изменениях в поведениях клиентов какого-либо интернет-сервиса за последние несколько лет), то Data Science в буквальном смысле смотрит в будущее. Специалисты по DS на основе больших данных могут создавать модели, которые предсказывают, что случится завтра. В том числе и предсказывать спрос на те или иные товары и услуги.