Команда grep в linux (поиск текста в файлах)
Содержание:
EXAMPLE top
The following example outputs the location and contents of any
line containing “f” and ending in “.c”, within all files in the
current directory whose names contain “g” and end in “.h”. The
-n option outputs line numbers, the -- argument treats expansions
of “*g*.h” starting with “-” as file names not options, and the
empty file /dev/null causes file names to be output even if only
one file name happens to be of the form “*g*.h”.
$ grep -n -- 'f.*\.c$' *g*.h /dev/null
argmatch.h:1:/* definitions and prototypes for argmatch.c
The only line that matches is line 1 of argmatch.h. Note that
the regular expression syntax used in the pattern differs from
the globbing syntax that the shell uses to match file names.
Регулярные выражения Linux
В регулярных выражениях могут использоваться два типа символов:
- обычные буквы;
- метасимволы.
Обычные символы — это буквы, цифры и знаки препинания, из которых состоят любые строки. Все тексты состоят из букв и вы можете использовать их в регулярных выражениях для поиска нужной позиции в тексте.
Метасимволы — это кое-что другое, именно они дают силу регулярным выражениям. С помощью метасимволов вы можете сделать намного больше чем поиск одного символа. Вы можете искать комбинации символов, использовать динамическое их количество и выбирать диапазоны. Все спецсимволы можно разделить на два типа, это символы замены, которые заменяют собой обычные символы, или операторы, которые указывают сколько раз может повторяться символ. Синтаксис регулярного выражения будет выглядеть таким образом:
обычный_символ спецсимвол_оператор
спецсимвол_замены спецсимвол_оператор
Если оператор не указать, то будет считаться, что символ обязательно должен встретится в строке один раз. Таких конструкций может быть много. Вот основные метасимволы, которые используют регулярные выражения bash:
- \ — с обратной косой черты начинаются буквенные спецсимволы, а также он используется если нужно использовать спецсимвол в виде какого-либо знака препинания;
- ^ — указывает на начало строки;
- $ — указывает на конец строки;
- * — указывает, что предыдущий символ может повторяться 0 или больше раз;
- + — указывает, что предыдущий символ должен повторится больше один или больше раз;
- ? — предыдущий символ может встречаться ноль или один раз;
- {n} — указывает сколько раз (n) нужно повторить предыдущий символ;
- {N,n} — предыдущий символ может повторяться от N до n раз;
- . — любой символ кроме перевода строки;
- — любой символ, указанный в скобках;
- х|у — символ x или символ y;
- — любой символ, кроме тех, что указаны в скобках;
- — любой символ из указанного диапазона;
- — любой символ, которого нет в диапазоне;
- \b — обозначает границу слова с пробелом;
- \B — обозначает что символ должен быть внутри слова, например, ux совпадет с uxb или tuxedo, но не совпадет с Linux;
- \d — означает, что символ — цифра;
- \D — нецифровой символ;
- \n — символ перевода строки;
- \s — один из символов пробела, пробел, табуляция и так далее;
- \S — любой символ кроме пробела;
- \t — символ табуляции;
- \v — символ вертикальной табуляции;
- \w — любой буквенный символ, включая подчеркивание;
- \W — любой буквенный символ, кроме подчеркивания;
- \uXXX — символ Unicdoe.
Важно отметить, что перед буквенными спецсимволами нужно использовать косую черту, чтобы указать, что дальше идет спецсимвол. Правильно и обратное, если вы хотите использовать спецсимвол, который применяется без косой черты в качестве обычного символа, то вам придется добавить косую черту
Например, вы хотите найти в тексте строку 1+ 2=3. Если вы используете эту строку в качестве регулярного выражения, то ничего не найдете, потому что система интерпретирует плюс как спецсимвол, который сообщает, что предыдущая единица должна повториться один или больше раз. Поэтому его нужно экранировать: 1 \+ 2 = 3. Без экранирования наше регулярное выражение соответствовало бы только строке 11=3 или 111=3 и так далее. Перед равно черту ставить не нужно, потому что это не спецсимвол.
Как используются регулярные выражения
Текстовые данные играют важную роль во всех Unix-подобных системах, таких как Linux. Среди прочего, текстом является и вывод консольных программ, и файлы конфигурации, отчётов и т.д. Регулярные выражения являются (пожалуй) одной из самых сложных концепций по работе с текстом, поскольку предполагают высокий уровень абстракции. Но время, потраченное на их изучение, с лихвой окупится. Умея использовать регулярные выражения, вы сможете делать удивительные вещи, хотя их полная ценность может быть не сразу очевидной.
В этой статье будет рассмотрено использование регулярных выражений вместе с командой grep. Но их применение не ограничивается только этим: регулярные выражения поддерживаются другими командами Linux, многими языками программирования, применяются при конфигурации (например, в настройках правил mod_rewrite в Apache), а также некоторые программы с графическим интерфейсом позволяют устанавливать правила для поиска/копирования/удаления с поддержкой регулярных выражений. Даже в популярной офисной программе Microsoft Word для поиска и замены текста вы можете использовать регулярные выражения и подстановочные символы.
Grep IP addresses
Greping for IP addresses can get a little complex because we can’t just tell grep to look for four numbers separated by dots – well, we could, but that command has the potential to return invalid IP addresses as well.
The following command will find and isolate only valid IPv4 addresses:
$ grep -E -o "(25|2|??)\.(25|2|??)\.(25|2|??)\.(25|2|??)" /var/log/auth.log
We used this on our Ubuntu server just to see where the latest SSH attempts have been made from.
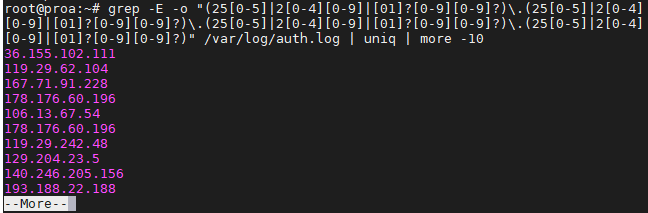
To avoid repeat information and prevent it from flooding your screen, you may want to pipe your grep commands to “uniq” and “more” as we did in the screenshot above.
Команды для управления сетью
В стандартный функционал «Терминала» входит и просмотр данных по параметрам сети, скорости и качестве передачи данных.
- ip – команда для работы с сетью, благодаря наличию множества опций она многофункциональна. К примеру, добавив функцию address show, можно посмотреть информацию о сетевых адресах, а с route управлять маршрутизацией.
- ping – помогает определить качество подключения к сети или наличие его как такового.
- nethogs – выводит данные о количестве израсходованного трафика.
- traceroute – команда, аналогичная ping, но дополнительно дающая информацию о полном маршруте передачи пакетов, скорости доставки на каждом узле и так далее.
- mtr – мощная утилита для диагностики сети, совмещающая функционал команд ping и traceroute.
ОПЦИИ
Начнём с того, что «grep» умеет не только фильтровать стандартный ввод , но и осуществлять поиск по файлам. По умолчанию «grep» будет искать только в файлах, находящихся в текущем каталоге, однако при помощи очень полезной опции можно сказать команде «grep» искать рекурсивно начиная с заданной директории.
GIST | По умолчанию команда «grep» чувствительна к регистру. Следующий пример показывает как можно искать и при этом не учитывать регистр, например «Adams» и «adams» одно и то же:
--ignore-case 'adams'
George Washington, 1789-1797 John Adams, 1797-1801 Thomas Jefferson, 1801-1809
John Adams, 1797-1801
GIST | Поиск наоборот (иногда говорят инвертный поиск), то есть будут выведены все строки, кроме имеющих вхождение указанного шаблона:
--invert-match 'Adams'
George Washington, 1789-1797 John Adams, 1797-1801 Thomas Jefferson, 1801-1809
George Washington, 1789-1797 Thomas Jefferson, 1801-1809
GIST | Опции конечно же можно и нужно комбинировать друг с другом. Например поиск наоборот с выводом порядковых номеров строк с вхождениями:
--line-number --invert-match 'Adams'
George Washington, 1789-1797 John Adams, 1797-1801 Thomas Jefferson, 1801-1809
1:George Washington, 1789-1797 3:Thomas Jefferson, 1801-1809
GIST | Раскраска. Иногда удобно, когда искомое нами слово подсвечивается цветом. Все это уже есть в «grep», остается только включить:
--line-number --color=always 'Adams'
George Washington, 1789-1797 John Adams, 1797-1801 Thomas Jefferson, 1801-1809
2:John Adams, 1797-1801
GIST | Мы хотим выбрать все ошибки из лог файла, но знаем что в следующей сточке после ошибки может содержаться полезная информация, тогда удобно вывести несколько строк из контекста. По умолчанию «grep» выводит лишь строку, в которой было найдено совпадение, но есть несколько опций, позволяющих заставить «grep» выводить больше. Для вывода нескольких строк (в нашем случае двух) после вхождения:
--color=always -A2 'Adams'
George Washington, 1789-1797 John Adams, 1797-1801 Thomas Jefferson, 1801-1809 James Madison, 1809-1817 James Monroe, 1817-1825
John Adams, 1797-1801 Thomas Jefferson, 1801-1809 James Madison, 1809-1817
GIST | Аналогично для дополнительного вывода нескольких строк перед вхождением:
--color=always -B2 'James'
George Washington, 1789-1797 John Adams, 1797-1801 Thomas Jefferson, 1801-1809 James Madison, 1809-1817 James Monroe, 1817-1825
John Adams, 1797-1801 Thomas Jefferson, 1801-1809 James Madison, 1809-1817 James Monroe, 1817-1825
GIST | Однако чаще всего требуется выводить симметричный контекст, для этого есть ещё более сокращённая запись. Выведем по две строки как сверху так и снизу от вхождения:
--color=always -C2 'James'
George Washington, 1789-1797 John Adams, 1797-1801 Thomas Jefferson, 1801-1809 James Madison, 1809-1817 James Monroe, 1817-1825 John Quincy Adams, 1825-1829 Andrew Jackson, 1829-1837 Martin Van Buren, 1837-1841
John Adams, 1797-1801 Thomas Jefferson, 1801-1809 James Madison, 1809-1817 James Monroe, 1817-1825 John Quincy Adams, 1825-1829 Andrew Jackson, 1829-1837
GIST | Когда Вы ищете , то по умолчанию «grep» будет выводить также, , и тому подобные комбинации. Найдём только те строки, которые выключают именно всё слово целиком:
--word-regexp --color=always 'John'
John Fitzgerald Kennedy, 1961-1963 Lyndon Baines Johnson, 1963-1969
John Fitzgerald Kennedy, 1961-1963
GIST | Ну и напоследок если Вы просто хотите знать количество строк с совпадениями одним единственным числом, но при этом не выводить больше ничего:
--count --color=always 'John'
John Fitzgerald Kennedy, 1961-1963 Lyndon Baines Johnson, 1963-1969 Richard Milhous Nixon, 1969-1974
2
Стоит отметить, что у большинства опций есть двойник, например можно привести к более короткому виду и т.д.
Опции
-0- Использует во входном потоке символ-разделитель NULL («\0») вместо «пробела» и «перевода строки», хорошо сочетается с опцией -print0 команды find
-l -Выполнять команду для каждой группы из заданного числа непустых строк аргументов, прочитанных со стандартного ввода. Последний вызов команды может быть с меньшим числом строк аргументов. Считается, что строка заканчивается первым встретившимся символом перевода строки, если только перед ним не стоит пробел или символ табуляции; пробел/табуляция в конце сигнализируют о том, что следующая непустая строка является продолжением данной. Если число опущено, оно считается равным 1. Опция -l включает опцию -x.
-I Режим вставки: команда выполняется для каждой строки стандартного ввода, причём вся строка рассматривается как один аргумент и подставляется в начальные_аргументы вместо каждого вхождения цепочки символов зам_цеп. Допускается не более 5 начальных_аргументов, содержащих одно или несколько вхождений зам_цеп. Пробелы и табуляции в начале вводимых строк отбрасываются. Сформированные аргументы не могут быть длиннее 255 символов. Если цепочка зам_цеп не задана, она полагается равной { }. Опция -I включает опцию -x.
-n Выполнить команду, используя максимально возможное количество аргументов, прочитанных со стандартного ввода, но не более заданного числа. Будет использовано меньше аргументов. Если их общая длина превышает размер (см. ниже опцию -s). Или если для последнего вызова их осталось меньше, чем заданное число. Если указана также опция -x, каждая группа из указанного числа аргументов должны укладываться в ограничение размера, иначе выполнение xargs прекращается.
-t Режим трассировки: команда и каждый построенный список аргументов перед выполнением выводится в стандартный поток ошибок.
-p Режим с приглашением: xargs перед каждым вызовом команды запрашивает подтверждение. Включается режим трассировки (-t), за счет чего печатается вызов команды, который должен быть выполнен, а за ним — приглашение ?…. Ответ y (за которым может идти что угодно) приводит к выполнению команды; при каком-либо другом ответе, включая возврат каретки, данный вызов команды игнорируется.
-x Завершить выполнение, если очередной список аргументов оказался длиннее, чем размер (в символах). Опция -x включается опциями -i и -l. Если ни одна из опций -i, -l или -n не указана, общая длина всех аргументов должна укладываться в ограничение размера.
-s Максимальный общий размер (в символах) каждого списка аргументов установить равным заданному размеру. Размер должен быть положительным числом, не превосходящим 470 (подразумеваемое значение). При выборе размера следует учитывать, что к каждому аргументу добавляется по одному символу; кроме того, запоминается число символов в имени команды.
-e Цепочка символов лконф_цеп считается признаком логического конца файла. Если опция -e не указана, признаком конца считается подчеркивание (_). Опция -e без лконф_цеп аннулирует возможность устанавливать логический конец файла (подчеркивание при этом рассматривается как обычный символ). Команда xargs читает стандартный ввод до тех пор, пока не дойдет до конца файла или не встретит цепочку лконф_цеп.
Grep NOT
7. Grep NOT using grep -v
Using grep -v you can simulate the NOT conditions. -v option is for invert match. i.e It matches all the lines except the given pattern.
grep -v 'pattern1' filename
For example, display all the lines except those that contains the keyword “Sales”.
$ grep -v Sales employee.txt 200 Jason Developer Technology $5,500 300 Raj Sysadmin Technology $7,000 400 Nisha Manager Marketing $9,500
You can also combine NOT with other operator to get some powerful combinations.
For example, the following will display either Manager or Developer (bot ignore Sales).
$ egrep 'Manager|Developer' employee.txt | grep -v Sales 200 Jason Developer Technology $5,500 400 Nisha Manager Marketing $9,500
Как использовать команду Grep?
Принадлежащая к семейству Unix команда grep является одним из самых универсальных и полезных инструментов. Эта утилита выполняет поиск в текстовом файле за заданным нами паттерном. Другими словами, с помощью grep вы можете найти необходимое вам слово или значение. А содержащие ваш запрос строки или строка будут выведены в терминал.
На первый взгляд, может показаться, что эта утилита имеет слишком узкое применение. Однако она способна значительно облегчить жизнь системным администраторам, которым приходится обрабатывать множество служб с различными файлами конфигурации. С помощью команды они могут быстро найти необходимые им строки в этих файлах.
Сначала давайте подключимся к VPS с помощью SSH. Вот статья, в которой показано, как это сделать с помощью PuTTY SSH.
ssh vash-user@vash-server
Если на вашем компьютере вы используете Linux, просто откройте терминал.
Синтаксис команды grep при поиске в одном файле выглядит следующим образом:
grep значение
- grep — команда
- — модификаторы команды
- значение — поисковый запрос
- — файл, в котором вы выполняете поиск
Вы можете просмотреть документацию и пояснения к различным опциям команды, введя в командной строке:
grep –help
Как видите, команда предлагает нам множество опций. Однако наиболее важными и часто используемыми являются параметры:
- -i — поиск не будет чувствителен к регистру. То есть, если вы хотите найти слово «автомобиль», написанные как «АВТОМОБИЛЬ» слова тоже будут найдены.
- -c — покажет только количество строк, содержащих поисковый запрос
- -r — включает рекурсивный поиск в текущем каталоге
- -n — выведет номера строк, содержащих поисковый запрос
- -v — обратный поиск, выводит только строки, в которых нет указанного поискового запроса
Regular expressions
A regular expression is a pattern that describes a set of strings. Regular expressions are constructed analogously to arithmetic expressions, using various operators to combine smaller expressions.
grep understands three different versions of regular expression syntax: «basic» (BRE), «extended» (ERE) and «perl» (PRCE). In GNU grep, there is no difference in available functionality between basic and extended syntaxes. In other implementations, basic regular expressions are less powerful. The following description applies to extended regular expressions; differences for basic regular expressions are summarized afterwards. Perl regular expressions give additional functionality.
The fundamental building blocks are the regular expressions that match a single character. Most characters, including all letters and digits, are regular expressions that match themselves. Any metacharacter with special meaning may be quoted by preceding it with a backslash.
The period (.) matches any single character.
Разница между grep, egrep, fgrep, pgrep, zgrep
Различные переключатели grep исторически были включены в различные двоичные файлы. В современных системах Linux вы найдете эти переключатели доступными в команде base grep, но часто дистрибутивы поддерживают и другие команды.
Со страницы руководства для grep:
egrep является эквивалентом grep -E
Этот переключатель будет интерпретировать шаблон как расширенное регулярное выражение . Есть множество разных вещей, которые вы можете сделать с этим, но вот пример того, как выглядит использование регулярного выражения с grep.
Давайте найдем в текстовом документе строки, которые содержат две последовательные буквы «р»:
$ egrep p\{2} fruits.txt
или
$ grep -E p\{2} fruits.txt
fgrep является эквивалентом grep -F
Этот переключатель будет интерпретировать шаблон как список фиксированных строк и попытаться сопоставить любую из них. Это полезно, когда вам нужно искать символы регулярного выражения. Это означает, что вам не нужно экранировать специальные символы, как если бы вы использовали обычный grep.
$ fgrep $ License.txt There is a $100 free for commercial use.
pgrep — это команда для поиска имени запущенного процесса в вашей системе и возврата соответствующих идентификаторов процесса. Например, вы можете использовать его, чтобы найти идентификатор процесса демона SSH:
$ pgrep sshd
По функциям это похоже на простую передачу вывода команды ‘ps’ в grep.
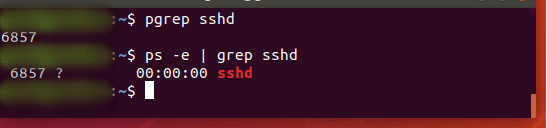
Вы можете использовать эту информацию, чтобы убить работающий процесс или устранить проблемы со службами, работающими в вашей системе.
zgrep используется для поиска сжатых файлов по шаблону. Это позволяет вам искать файлы внутри сжатого архива без необходимости сначала распаковывать этот архив, в основном экономя вам дополнительный шаг или два.
$ zgrep apple fruits.txt.gz
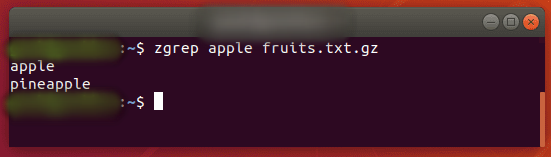
zgrep также работает с tar-файлами, но кажется, что он говорит только о том, удалось ли найти совпадение.
$ zgrep apple fruits.tar.gz
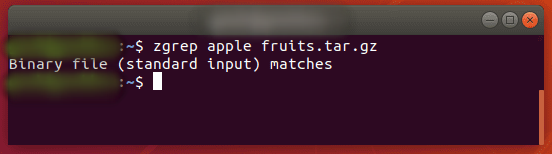
Мы упоминаем об этом, потому что файлы, сжатые с помощью gzip, обычно являются архивами tar.
ПРИМЕРЫ ИСПОЛЬЗОВАНИЯ
С теорией покончено, теперь перейдем к практике. Рассмотрим несколько основных примеров поиска внутри файлов Linux с помощью grep, которые могут вам понадобиться в повседневной жизни.
ПОИСК ТЕКСТА В ФАЙЛАХ
В первом примере мы будем искать пользователя User в файле паролей Linux. Чтобы выполнить поиск текста grep в файле /etc/passwd введите следующую команду:
В результате вы получите что-то вроде этого, если, конечно, существует такой пользователь:
А теперь не будем учитывать регистр во время поиска. Тогда комбинации ABC, abc и Abc с точки зрения программы будут одинаковы:
ВЫВЕСТИ НЕСКОЛЬКО СТРОК
Например, мы хотим выбрать все ошибки из лог файла, но знаем что в следующей сточке после ошибки может содержаться полезная информация, тогда с помощью grep отобразим несколько строк, ошибки будем искать в Xorg.log по шаблону «EE»:
Выведет строку с вхождением и 4 строчки после нее.
Выведет целевую строку и 4 строчки до нее
Выведет по две строки с верху и снизу от вхождения.
РЕГУЛЯРНЫЕ ВЫРАЖЕНИЯ В GREP
Регулярные выражения grep — очень мощный инструмент в разы расширяющий возможности поиска текста в файлах grep. Для активации этого режима используйте опцию -e. Рассмотрим несколько примеров:
Поиск вхождения в начале строки с помощью спецсимвола «^», например, выведем все сообщения за ноябрь:
Поиск в конце строки, спецсимвол «$»:
Найдем все строки которые содержат цифры:
Вообще, регулярные выражения grep это очень обширная тема, в этой статье я лишь показал несколько примеров, чтобы дать вам понять что это. Как вы увидели, таким образом, поиск текста в файлах grep становиться еще гибче. Но на полное объяснение этой темы нужна целая статья, поэтому пока пропустим их и пойдем дальше.
РЕКУРСИВНОЕ ИСПОЛЬЗОВАНИЕ GREP
Если вам нужно провести поиск текста grep в нескольких файлах, размещенных в одном каталоге или подкаталогах, например, в файлах конфигурации Apache — /etc/apache2/ — используйте рекурсивный поиск. Для включения рекурсивного поиска в grep есть опция -r. Следующая команда займется поиском текста в файлах Linux во всех подкаталогах /etc/apache2 на предмет вхождения строки mydomain.com:
В выводе вы получите:
Здесь перед найденной строкой указано имя файла в котором она была найдена. Вывод имени файла легко отключить с помощью опции -h:
ПОИСК СЛОВ В GREP
Когда вы ищете строку abc, grep будет выводить также kbabc, abc123, aafrabc32 и тому подобные комбинации. Вы можете заставить grep искать по содержимому файлов в linux только те строки, которые выключают искомые слова с помощью опции -w:
ПОИСК ДВУХ СЛОВ
Можно искать по содержимому файла не одно слово, а целых несколько. Чтобы искать два разных слова используйте команду egrep:
КОЛИЧЕСТВО ВХОЖДЕНИЙ СТРОКИ
Утилита Grep может сообщить сколько раз определенная строка была найдена в каждом файле. Для этого используется опция -c (счетчик):
C помощью опции -n можно выводить номер строки в которой найдено вхождение, например:
Получим:
ИНВЕРТИРОВАННЫЙ ПОИСК В GREP
Команда grep linux может быть использована для поиска строк в файле Linux которые не содержат указанное слово. Например, вывести только те строки, которые не содержат слово пар:
ВЫВОД ИМЕНИ ФАЙЛА
Вы можете указать grep выводить только имя файла в котом было найдено заданное слово с помощью опции -l. Например, следующая команда выведет все имена файлов, при поиске по содержимому которых было обнаружено вхождение primary:
Пример использования
Допустим, требуется быстро найти фразу «our products» в HTML-файлах на компьютере. Начнем с поиска в одном из них. В данном случае ШАБЛОН – это «our products», а ФАЙЛ – product-listing.html
$ grep "our products" product-listing.html <p>You will find that all of our products are impeccably designed and meet the highest manufacturing standards available <em>anywhere. </em> </p> $
Была найдена одна строка, содержащая указанный шаблон, и grep выводит всю соответствующую строку на терминал. Строка длиннее ширины окна терминала, поэтому текст переносится на следующие строки, но данный вывод соответствует ровно одной строке в файле.
Работа с файлами
Команда grep может обрабатывать любое количество файлов одновременно. Создадим три файла:
123.txt: alice.txt: ast.txt:
1234 Алиса очень Символ астериска
5678 красивая девочка, обозначается (*)
89*0 у нее такая ****** звездочкой.
длинная коса!
И дадим команду:
grep '*' 123.txt ast.txt alice.txt 123.txt:89*0 ast.txt:обозначается (*). alice.txt:у нее такая ******
В выводе перечислены файлы, и указано, в каком из них какая строка содержит символ астериска. ОБРАЗЕЦ (*) пришлось взять в кавычки, чтобы командный интерпретатор понял, что имеется в виду символ, а не условный знак. Попробуйте без кавычек, увидите — ничего не получится.
Команда grep вовсе не ограничена одним выражением в качестве ОБРАЗЦА, можно задавать хоть целые фразы. Только их нужно заключать в кавычки (одинарные или двойные):
grep 'ная ко' 123.txt ast.txt alice.txt alice.txt:длинная коса!
Возможности поиска при помощи команды grep могут быть значительно расширены применением групповых символов. Например, уже упоминавшийся астериск (звездочка) используется для представления любого символа или группы символов, если речь идет о тексте, и любого файла или группы файлов, если речь идет о директории.
Создадим директорию /example, в которую поместим файлы наших примеров: 123.txt, ast.txt, alice.txt и дадим команду:
grep '*' example/* example/123.txt:89*0 example/alice.txt:у нее такая ****** example/ast.txt:обозначается (*)
То есть мы приказали просмотреть все файлы директории /example. Таким способом можно обследовать такие огромные директории как /usr, /dev, и любые другие.
Выражения в квадратных скобках и Классы символов
В дополнение к совпадению любого символа в заданной позиции в нашем регулярном выражении, мы также, используя выражения в квадратных скобках, можем задать совпадение единичного символа из указанного набора символов. С выражениями в квадратных скобках мы можем указать набор символов для соответствия (включая символы, которые в противном случае были бы истолкованы как метасимволы). В этом примере, используя набор из двух символов:
grep -h 'zip' dirlist*.txt bzip2 bzip2recover gzip

мы найдём любые строчки, содержащие строки «bzip» или «gzip».
Набор может содержать любое количество символов, а метасимволы теряют своё специальное значение, когда помещаются внутрь квадратных скобок. Тем не менее, есть два случая в которых метасимволы, используемые внутри квадратных скобок, имеют различные значения. Первый – это каретка (^), которая используется для указания отрицания; второй – это тире (-), которое используется для указания диапазона символов.
Отрицание
Если первым символом выражения в квадратных скобках является каретка (^), то остальные символы принимаются как набор символов, которые не должны присутствовать в заданной позиции символа. Сделаем это изменив наш предыдущий пример:
grep -h 'zip' dirlist*.txt bunzip2 gunzip funzip gpg-zip mzip p7zip preunzip prezip prezip-bin unzip unzipsfx
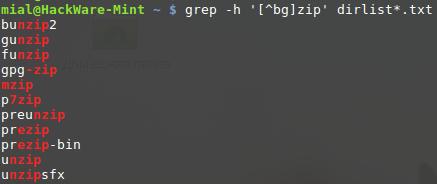
С активированным отрицанием, мы получили список файлов, которые содержат строку «zip», перед которой идёт любой символ, кроме «b» или «g»
Обратите внимание, что zip не был найден. Отрицаемый набор символов всё равно требует символ на заданной позиции, но символ не должен быть членом инвертированного набора.
Символ каретки вызывает отрицание только если он является первым символом внутри выражения в квадратных скобках; в противном случае, он теряет своё специальное назначение и становится обычным символом из набора.
Традиционные диапазоны символов
Если мы хотим сконструировать регулярное выражение, которое должно найти каждый файл из нашего списка, начинающийся на заглавную букву, мы можем сделать следующее:
grep -h '^' dirlist*.txt MAKEDEV GET HEAD POST VBoxClient X X11 Xorg ModemManager NetworkManager VBoxControl VBoxService
Суть в том, что мы разместили все 26 заглавных букв в выражение внутри квадратных скобок. Но мысль печатать их все не вызывает энтузиазма, поэтому есть другой путь:
grep -h '^' dirlist*.txt
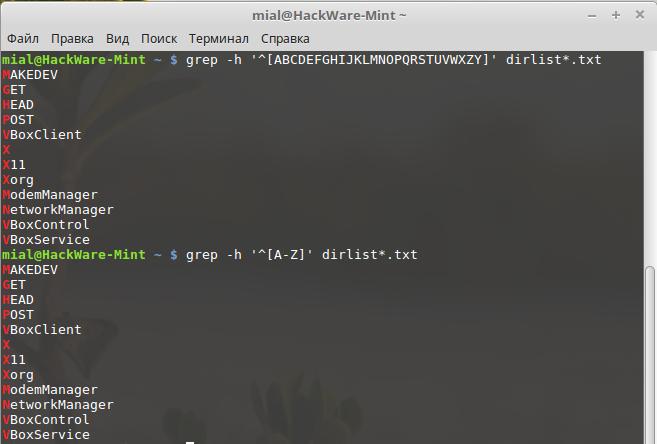
Используя трёхсимвольный диапазон, мы можем сократить запись из 26 букв. Таким способом можно выразить любой диапазон символов, включая сразу несколько диапазонов, такие, как это выражение, которое соответствует всем именам файлов, начинающихся с букв и цифр:
grep -h '^' dirlist*.txt
В диапазонах символов мы видим, что символ чёрточки трактуется особым образом, поэтому как мы можем включить символ тире в выражение внутри квадратных скобок? Сделав его первым символом в выражении. Рассмотрим два примера:
grep -h '' dirlist*.txt
Это будет соответствовать каждому имени файла, содержащему заглавную букву. При этом:
grep -h '' dirlist*.txt
будет соответствовать каждому имени файла, содержащему тире, или заглавную «A», или заглавную «Z».
Классы символов POSIX
Подробнее о POSIX вы можете почитать в Википедии.
В POSIX имеются свои классы символов, которые вы можете использовать в регулярных выражениях:
| Класс символов | Описание |
|---|---|
| Алфавитно-цифровые символы. В ASCII эквивалентно: | |
| То же самое, что и , с дополнительным символом подчёркивания (_). | |
| Алфавитные символы. В ASCII эквивалентно: | |
| Включает символы пробела и табуляции. | |
| Управляющие коды ASCII. Включает ASCII символы с 0 до 31 и 127. | |
| Цифры от нуля до девяти. | |
| Видимые символы. В ASCII сюда включены символы с 33 по 126. | |
| Буквы в нижнем регистре. | |
| Символы пунктуации. В ASCII эквивалентно: [-!»#$%&'()*+,./:;?@_`{|}~] | |
| Печатные символы. Все символы в плюс символ пробела. | |
| Символы белых пробелов, включающих пробел, табуляцию, возврат каретки, новую строку, вертикальную табуляцию и разрыв страницы. В ASCII эквивалентно: | |
| Символы в верхнем регистре. | |
| Символы, используемые для выражения шестнадцатеричных чисел. В ASCII эквивалетно: |
В этих выражениях квадратные скобки и двоеточия являются частью записи класса символов (диапазонов).
Внимание: в зависимости от настроек локали, , , и другие буквенные диапазоны могут включать буквы вашего алфавита, например, русского. Т.е
может соответствовать не , а .
Команды для управления пользователями
Linux — многопользовательская система. Ей одновременно могут управлять несколько людей. Поэтому здесь достаточно сложная система добавления и редактирования учетных записей.
- useradd — создает новую учетную запись. Например, мы хотим добавить пользователя с именем Timeweb. Для этого вводим: useradd Timeweb. Но свежесозданному аккаунту нужен не только логин, но и пароль. С помощью опций можно задать дополнительные характеристики новому пользователю.
- passwd — задает пароль для учетной записи, работает вкупе с предыдущей командой. То есть сразу после создания аккаунта, пишем: passwd Timeweb (в вашем случае может быть любой другой пользователь). После этого система попросит придумать и указать пароль для новой учетной записи. По ходу набора пароля в терминале не будут отображаться даже звездочки, но он все равно учитывает каждую нажатую клавишу. Продолжайте набирать пароль вслепую.
- userdel — удаляет выбранную учетную запись. Синтаксис простейший: