Шпаргалка по регулярным выражениям. в примерах
Содержание:
Практические примеры сложных регулярных выражений
Теперь, когда вы знаете теорию и основной синтаксис регулярных выражений в PHP, пришло время создать и проанализировать некоторые более сложные примеры.
1) Проверка имени пользователя с помощью регулярного выражения
Начнем с проверки имени пользователя. Если у вас есть форма регистрации, вам понадобится проверять на правильность имена пользователей. Предположим, вы не хотите, чтобы в имени были какие-либо специальные символы, кроме «» и, конечно, имя должно содержать буквы и возможно цифры. Кроме того, вам может понадобиться контролировать длину имени пользователя, например от 4 до 20 символов.
Сначала нам нужно определить доступные символы. Это можно реализовать с помощью следующего кода:
После этого нам нужно ограничить количество символов следующим кодом:
{4,20}
Теперь собираем это регулярное выражение вместе:
^{4,20}$
В случае Perl-совместимого регулярного выражения заключите его символами ‘‘. Итоговый PHP-код выглядит так:
<?php
$pattern = '/^{4,20}$/';
$username = "demo_user-123";
if (preg_match($pattern, $username)) {
echo "Проверка пройдена успешно!";
} else {
echo "Проверка не пройдена!";
}
?>
2) Проверка шестнадцатеричного кода цвета регулярным выражением
Шестнадцатеричный код цвета выглядит так: , также допустимо использование краткой формы, например . В обоих случаях код цвета начинается с и затем идут ровно 3 или 6 цифр или букв от a до f.
Итак, проверяем начало кода:
^#
Затем проверяем диапазон допустимых символов:
После этого проверяем допустимую длину кода (она может быть либо 3, либо 6). Полный код регулярного выражения выйдет следующим:
^#(({3}$)|({6}$))
Здесь мы используем логический оператор, чтобы сначала проверить код вида , а затем код вида . Итоговый PHP-код проверки регулярным выражением выглядит так:
<?php
$pattern = '/^#(({3}$)|({6}$))/';
$color = "#1AA";
if (preg_match($pattern, $color)) {
echo "Проверка пройдена успешно!";
} else {
echo "Проверка не пройдена!";
}
?>
3) Проверка электронной почты клиента с использованием регулярного выражения
Теперь давайте посмотрим, как мы можем проверить адрес электронной почты с помощью регулярных выражений. Сначала внимательно рассмотрите следующие примеры адресов почты:
john.doe@test.com john@demo.ua john_123.doe@test.info
Как мы можем видеть, символ является обязательным элементом в адресе электронной почты. Помимо этого должен быть какой-то набор символов до и после этого элемента. Точнее, после него должно идти допустимое доменное имя.
Таким образом, первая часть должна быть строкой с буквами, цифрами или некоторыми специальными символами, такими как . В шаблоне мы можем написать это следующим образом:
^+
Доменное имя всегда имеет, скажем, имя и tld (top-level domain) – т.е, доменную зону. Доменная зона – это , , и тому подобное. Это означает, что шаблон регулярного выражения для домена будет выглядеть так:
+\.{2,5}$
Теперь, если мы соберем все в кучу, то получим полный шаблон регулярного выражения для проверки адреса электронной почты:
^+@+\.{2,5}$
В коде PHP эта проверка будет выглядеть следующим образом:
<?php
$pattern = '/^+@+\.{2,5}$/';
$email = "john_123.doe@test.info";
if (preg_match($pattern, $email)) {
echo "Проверка пройдена успешно!";
} else {
echo "Проверка не пройдена!";
}
?>
Надеемся, что сегодняшняя статья помогла вам при знакомстве с регулярными выражениями в PHP, а практические примеры пригодятся вам при использовании регулярных выражений в собственных PHP скриптах.
-
3204
-
35
-
Опубликовано 16/04/2019
-
PHP, Уроки программирования
WordPress: Using Regexp to Retrieve Images From a Post
As I know many of you are WordPress users, you’ll probably enjoy that code which allows you to retrieve all images from post content and display it.
To use this code on your blog, simply paste the following code on one of your theme files.
<?php if (have_posts()) : ?>
<?php while (have_posts()) : the_post(); ?>
<?php
$szPostContent = $post->post_content;
$szSearchPattern = '~<img * />~';
// Run preg_match_all to grab all the images and save the results in $aPics
preg_match_all( $szSearchPattern, $szPostContent, $aPics );
// Check to see if we have at least 1 image
$iNumberOfPics = count($aPics);
if ( $iNumberOfPics > 0 ) {
// Now here you would do whatever you need to do with the images
// For this example the images are just displayed
for ( $i=0; $i < $iNumberOfPics ; $i++ ) {
echo $aPics;
};
};
endwhile;
endif;
?>
«Петя любит Дашу».replace(/Дашу|Машу|Сашу/, «Катю») ¶
Не трудно догадаться, что результатом работы js-выражения выше будет текст . Даже, если Петя неровно дышит к Маше или Саше, то результат всё равно не изменится.
Рассмотрим базовые спец. символы, которые можно использовать в шаблонах:
| Символ | Описание | Пример использования | Результат |
|---|---|---|---|
| \ | Символ экранирования или начала мета-символа | /путь\/к\/папке/ | Надёт текст |
| ^ | Признак начала строки | /^Дом/ | Найдёт все строки, которые начинаются на |
| $ | Признак конца строки | /родной$/ | Найдёт все строки, которые заканчиваются на |
| . | Точка означает любой символ, кроме перевода строки | /Петя ..бит Машу/ | Найдёт как , так и |
| | | Означает ИЛИ | /Вася|Петя/ | Найдёт как Васю, так и Петю |
| ? | Означает НОЛЬ или ОДИН раз | /Вжу?х/ | Найдёт и |
| * | Означает НОЛЬ или МНОГО раз | /Вжу*х/ | Найдёт , , , и т.д. |
| + | Означает ОДИН или МНОГО раз | /Вжу+х/ | Найдёт , , и т.д. |
Помимо базовых спец. символов есть мета-символы (или мета-последовательности), которые заменяют группы символов:
| Символ | Описание | Пример использования | Результат |
|---|---|---|---|
| \w | Буква, цифра или _ (подчёркивание) | /^\w+$/ | Соответствует целому слову без пробелов, например |
| \W | НЕ буква, цифра или _ (подчёркивание) | /\W\w+\W/ | Найдёт полное слово, которое обрамлено любыми символами, например |
| \d | Любая цифра | /^\d+$/ | Соответствует целому числу без знака, например |
| \D | Любой символ НЕ цифра | /^\D+$/ | Соответствует любому выражению, где нет цифр, например |
| \s | Пробел или табуляция (кроме перевода строки) | /\s+/ | Найдёт последовательность пробелов от одного и до бесконечности |
| \S | Любой символ, кроме пробела или табуляции | /\s+\S/ | Найдёт последовательность пробелов, после которой есть хотя бы один другой символ |
| \b | Граница слова | /\bдом\b/ | Найдёт только отдельные слова , но проигнорирует |
| \B | НЕ граница слова | /\Bдом\b/ | Найдёт только окночние слов, которые заканчиваются на |
| \R | Любой перевод строки (Unix, Mac, Windows) | /.*\R/ | Найдёт строки, которые заканчиваются переводом строки |
Нужно отметить, что спец. символы \w, \W, \b и \B не работают по умолчанию с юникодом (включая кириллицу). Для их правильной работы нужно указывать модификатор . К сожалению, на окончание 2019 года JavaScript не поддерживает регулярные выражения для юникода даже с модификатором, поэтому в js эти мета-символы работают только для латиницы.
Ещё регулярные выражения поддерживают разные виды скобочек:
| Выражение | Описание | Пример использования | Результат |
|---|---|---|---|
| (…) | Круглые скобки означают под-шаблон, который идёт в результат поиска | /(Петя|Вася|Саша) любит Машу/ | Найдёт всю строку и запишет воздыхателя Маши в результат поиска под номером 1 |
| (?:…) | Круглые скобки с вопросом и двоеточием означают под-шаблон, который НЕ идёт в результат поиска | /(?:Петя|Вася|Саша) любит Машу/ | Найдёт только полную строку, воздыхатель останется инкогнито |
| (?P<name>…) | Задаёт имя под-шаблона | /(?P<воздыхатель>Петя|Вася|Саша) любит Машу/ | Найдёт полную строку, а воздыхателя запишет в результат под индексом 1 и ‘воздыхатель’ |
| Квадратные скобки задают ЛЮБОЙ СИМВОЛ из последовательности (включая спец. символы \w, \d, \s и т.д.) | /^+$/ | Соответствует любому выражению , но не | |
| Если внутри квадратных скобок указать минус, то это считается диапазоном | /+/ | Аналог /\w/ui для JavaScript | |
| Если минус является первым или последним символом диапазона, то это просто минус | /+/ | Найдёт любое целое числое с плюсом или минусом (причём не обязательно, чтобы минус или плюс были спереди) | |
| Квадратные скобки с «крышечекой» означают любой символ НЕ входящий в диапазон | //i | Найдёт любой символ, который не является буквой, числом или пробелом | |
| ] | Квадратные скобки в квадратных скобках задают класс символов (alnum, alpha, ascii, digit, print, space, punct и другие) | /]+/ | Найдёт последовательность непечатаемых символов |
| {n} | Фигурные скобки с одним числом задают точное количество символов | /\w+н{2}\w+/u | Найдёт слово, в котором две буквы н |
| {n,k} | Фигурные скобки с двумя числами задают количество символов от n до k | /\w+н{1,2}\w+/u | Найдёт слово, в котором есть одна или две буквы н |
| {n,} | Фигурные скобки с одним числом и запятой задают количество символов от n до бесконечности | /\w+н{3,}\w+/u | Найдёт слово, в котором н встречается от трёх и более раз подряд |
Практика регулярных выражений
Давайте попрактикуемся в некоторых концепциях, которые мы узнали выше.
Составьте выражение, которое соответствует любому 10-значному числу:
ВыполСтрока код »
Скрыть результаты
Давайте разберемся с этим и посмотрим, что там происходит.
- Если мы хотим добиться, чтобы совпадение охватывало всю строку, мы можем добавить квантификаторы и . Каретка соответствует началу входной строки, а знак доллара соответствует ее концу. Таким образом, шаблон не будет соответствовать, если строка содержит более 10 цифр.
- соответствует любому цифровому символу.
- совпадает с предыдущим выражением, в данном случае ровно 10 раз. Таким образом, если тестовая строка содержит менее или более 10 цифр, результат будет ложным.
Сопоставьте дату со следующим форматом DD-MM-YYYY или DD-MM-YY
ВыполСтрока код »
Скрыть результаты
Давайте разберемся с этим и посмотрим, что там происходит.
- Опять же, мы обернули все регулярное выражение внутрь и , так что совпадение охватывает всю строку.
- начало первого подвыражения.
- соответствует минимум 1 цифре и максимум 2 цифрам.
- соответствует буквальному дефису.
- конец первого подвыражения.
- соответствовать первому подвыражению ровно два раза.
- соответствует ровно двум цифрам.
- соответствует ровно двум цифрам. Но это необязательно (знак ?), поэтому год состоит из 2 или 4 цифр.
Выражение, которое соответствует чему угодно, кроме новой строки
Выражение должно соответствовать любой строке с форматом, например , где каждая переменная может быть любым символом, кроме новой строки.
ВыполСтрока код »
Скрыть результаты
Давайте разберемся с этим и посмотрим, что там происходит.
- Мы обернули все регулярное выражение внутрь и , так что совпадение охватывает всю строку.
- начало первого подвыражения
- соответствует любому символу, кроме новой строки, ровно 3 раза.
- соответствует буквальной точке
- конец первого подвыражения
- соответствует первому подвыражению ровно 3 раза.
- соответствует любому символу, кроме новой строки, ровно 3 раза.
← предыдущая
следующая →
Getting Started With Regular Expressions
For many beginners, regular expressions seem to be hard to learn and use. In fact, they’re far less hard than you may think. Before we dive deep inside regexp with useful and reusable codes, let’s quickly see the basics of PCRE regex patterns:
Regular Expressions Syntax
A regular expression (regex or regexp for short) is a special text string for describing a search pattern. A regex pattern matches a target string. The following table describes most common regex:
| Regular Expression | Will match… |
|---|---|
| foo | The string “foo” |
| ^foo | “foo” at the start of a string |
| foo$ | “foo” at the end of a string |
| ^foo$ | “foo” when it is alone on a string |
| a, b, or c | |
| Any lowercase letter | |
| Any character that is not a uppercase letter | |
| (gif|jpg) | Matches either “gif” or “jpg” |
| + | One or more lowercase letters |
| Any number, dot, or minus sign | |
| ^{1,}$ | Any word of at least one letter, number or _ |
| ()() | wy, wz, xy, or xz |
| Any symbol (not a number or a letter) | |
| ({3}|{4}) | Matches three letters or four numbers |
PHP Regular Expression Functions
PHP has many useful functions to work with regular expressions. Here is a quick cheat sheet of the main PHP regex functions. Remember that all of them are case sensitive.
For more information about the native functions for PHP regular expressions, have a look at the manual.
| Function | Description |
|---|---|
| preg_match() | The function searches string for pattern, returning true if pattern exists, and false otherwise. |
| preg_match_all() | The function matches all occurrences of pattern in string. Useful for search and replace. |
| preg_replace() | The function operates just like , except that regular expressions can be used in the pattern and replacement input parameters. |
| preg_split() | Preg Split () operates exactly like the function, except that regular expressions are accepted as input parameters. |
| preg_grep() | The function searches all elements of , returning all elements matching the regex pattern within a string. |
| preg_ quote() | Quote regular expression characters |
Группы регулярных выражений
Группы регулярных выражений — функция, позволяющая извлекать нужные объекты соответствия как отдельные элементы.
Предположим, что я хочу извлечь номер курса, код и имя как отдельные элементы. Не имея групп мне придется написать что-то вроде этого.
Давайте посмотрим, что получилось.
Я скомпилировал 3 отдельных регулярных выражения по одному для соответствия номерам курса, коду и названию.
Для номера курса, шаблон указывает на соответствие всем числам от 0 до 9. Добавление символа в конце заставляет найти по крайней мере 1 соответствие цифрам 0-9. Если вы уверены, что номер курса, будет иметь ровно 3 цифры, шаблон мог бы быть .
Для кода курса, как вы могли догадаться, будет совпадать с 3 большими буквами алфавита А-Я подряд (буква “ё” не включена в общий диапазон букв).
Для названий курса, будем искать а-я верхнего и нижнего регистра, предполагая, что имена всех курсов будут иметь как минимум 4 символа.
Можете ли вы догадаться, каков будет шаблон, если максимальный предел символов в названии курса, скажем, 20?
Теперь мне нужно написать 3 отдельные строки, чтобы разделить предметы. Но есть лучший способ. Группы регулярных выражений.
Поскольку все записи имеют один и тот же шаблон, вы можете создать единый шаблон для всех записей курса и внести данные, которые хотите извлечь из пары скобок ().
Обратите внимание на шаблон номера курса: , код: и название: они все помещены в круглую скобку (), для формирования группы
Что такое “жадное” соответствие в регулярных выражениях?
По умолчанию, регулярные выражения должны быть жадными. Это означает, что они пытаются извлечь как можно больше, пока соответствуют шаблону, даже если требуется меньше.
Давайте рассмотрим пример фрагмента HTML, где нам необходимо получить тэг HTML.
Вместо совпадения до первого появления ‘>’, которое, должно было произойти в конце первого тэга тела, он извлек всю строку. Это по умолчанию “жадное” соответствие, присущее регулярным выражениям.
С другой стороны, ленивое соответствие “берет как можно меньше”. Это можно задать добавлением в конец шаблона.
Если вы хотите получить только первое совпадение, используйте вместо этого метод поиска .
Регулярные выражения PHP
PHP содержит встроенные функции, которые позволяют работать с регулярными выражениями. Теперь рассмотрим часто используемые функции регулярных выражений PHP.
- preg_match — используется для выполнения сопоставления с шаблоном строки. Она возвращает true, если совпадение найдено, и false, если совпадение не найдено;
- preg_split — используется для разбивки строки по шаблону, результат возвращается в виде числового массива;
- preg_replace – используется для поиска по шаблону и замены на указанную строку.
Ниже приведен синтаксис функций регулярных выражений, таких как preg_match, preg_split или PHP regexp replace:
<?php
имя_функции('/шаблон/',объект);
?>
, где
«имя_функции» — это либо preg_match, либо preg_split, либо preg_replace.«/…/» — косые черты обозначают начало и конец регулярного выражения.«‘/шаблон/’» — шаблон, который нам нужно сопоставить.«объект» — строка, с которой нужно сопоставлять шаблон.
Теперь рассмотрим практические примеры использования упомянутых выше функций.
Preg match PHP
В первом примере функция preg_match используется для выполнения простого сопоставления шаблоном для слова guru в заданном URL-адресе.
В приведенном ниже коде показан вариант реализации данного примера:
<?php
$my_url = "www.guru99.com";
if (preg_match("/guru/", $my_url))
{
echo "the url $my_url contains guru";
}
else
{
echo "the url $my_url does not contain guru";
}
?>
«preg_match (‘/ guru /’, $ my_url)»
Здесь:
«preg_match(…)» — функция PHP match regexp.«‘/Guru/’» — шаблон регулярного выражения.«$My_url» — переменная, содержащая текст, с которым нужно сопоставить шаблон.
Preg split PHP
Рассмотрим другой пример, в котором используется функция preg_split.
Мы возьмем фразу и разобьем ее на массив; шаблон предназначен для поиска единичного пробела:
<?php
$my_text="I Love Regular Expressions";
$my_array = preg_split("/ /", $my_text);
print_r($my_array );
?>
Preg replace PHP
Рассмотрим функцию preg_replace, которая выполняет сопоставление с шаблоном и заменяет найденный результат другой строкой.
Приведенный ниже код ищет в строке слово guru. Он заменяет его кодом css, который задает цвет фона:
<?php
$text = "We at Guru99 strive to make quality education affordable to the masses. Guru99.com";
$text = preg_replace("/Guru/", '<span style="background:yellow">Guru</span>', $text);
echo $text;
?>
Границы
Java Regex API также может соответствовать границам в строке, а именно началом или концом строки, началом слова и т. д. API Java Regex поддерживает следующие границы:
| Символ | Описание |
|---|---|
| ^ | Начало строки |
| $ | Конец строки |
| \b | Граница слова (где слово начинается или заканчивается, например, пробел, табуляция и т. д.). |
| \B | Несловесная граница |
| \A | Начало ввода. |
| \G | Конец предыдущего совпадения |
| \Z | Конец ввода, кроме конечного объекта (если есть) |
| \z |
Начало строки
Соответствие границ ^ соответствует началу строки в соответствии со спецификацией API Java. Например, следующий пример получает только одно совпадение с индексом 0:
String text = "Line 1\nLine2\nLine3";
Pattern pattern = Pattern.compile("^");
Matcher matcher = pattern.matcher(text);
while(matcher.find()){
System.out.println("Found match at: " + matcher.start() + " to " + matcher.end());
}
Даже если входная строка содержит несколько разрывов строк, символ ^ соответствует только началу входной строки, а не началу каждой строки (после каждого переноса строки).
Начало соответствия строки / строки часто используется в сочетании с другими символами, чтобы проверить, начинается ли строка с определенной подстроки. Например, этот пример проверяет, начинается ли строка ввода с подстроки http: //:
String text = "http://jenkov.com";
Pattern pattern = Pattern.compile("^http://");
Matcher matcher = pattern.matcher(text);
while(matcher.find()){
System.out.println("Found match at: " + matcher.start() + " to " + matcher.end());
}
В этом примере найдено одно совпадение подстроки http: // из индекса 0 в индекс 7 во входном потоке. Даже если бы входная строка содержала больше экземпляров подстроки http: //, они не соответствовали бы этому регулярному выражению, так как оно начиналось с символа ^.
Конец строки
Соответствие $ соответствует концу строки в соответствии со спецификацией Java. На практике, однако, похоже, что он соответствует только концу входной строки.
Соответствие начала строки часто используется в сочетании с другими символами, чаще всего для проверки, заканчивается ли строка определенной подстрокой:
String text = "http://jenkov.com";
Pattern pattern = Pattern.compile(".com$");
Matcher matcher = pattern.matcher(text);
while(matcher.find()){
System.out.println("Found match at: " + matcher.start() + " to " + matcher.end());
}
В этом примере будет найдено одно совпадение в конце входной строки.
Строковые методы, поиск и замена
Следующие методы работают с регулярными выражениями из строк.
Все методы, кроме replace, можно вызывать как с объектами типа regexp в аргументах, так и со строками, которые автоматом преобразуются в объекты RegExp.
Так что вызовы эквивалентны:
var i = str.search(/\s/)
var i = str.search("\\s")
При использовании кавычек нужно дублировать \ и нет возможности указать флаги. Если регулярное выражение уже задано строкой, то бывает удобна и полная форма
var regText = "\\s" var i = str.search(new RegExp(regText, "g"))
Возвращает индекс регулярного выражения в строке, или -1.
Если Вы хотите знать, подходит ли строка под регулярное выражение, используйте метод (аналогично RegExp-методы ). Чтобы получить больше информации, используйте более медленный метод (аналогичный методу ).
Этот пример выводит сообщение, в зависимости от того, подходит ли строка под регулярное выражение.
function testinput(re, str){
if (str.search(re) != -1)
midstring = " contains ";
else
midstring = " does not contain ";
document.write (str + midstring + re.source);
}
Если в regexp нет флага , то возвращает тот же результат, что .
Если в regexp есть флаг , то возвращает массив со всеми совпадениями.
Чтобы просто узнать, подходит ли строка под регулярное выражение , используйте .
Если Вы хотите получить первый результат — попробуйте r.
В следующем примере используется, чтобы найти «Chapter», за которой следует 1 или более цифр, а затем цифры, разделенные точкой. В регулярном выражении есть флаг , так что регистр будет игнорироваться.
str = "For more information, see Chapter 3.4.5.1"; re = /chapter (\d+(\.\d)*)/i; found = str.match(re); alert(found);
Скрипт выдаст массив из совпадений:
- Chapter 3.4.5.1 — полностью совпавшая строка
- 3.4.5.1 — первая скобка
- .1 — внутренняя скобка
Следующий пример демонстрирует использование флагов глобального и регистронезависимого поиска с . Будут найдены все буквы от А до Е и от а до е, каждая — в отдельном элементе массива.
var str = "ABCDEFGHIJKLMNOPQRSTUVWXYZabcdefghijklmnopqrstuvwxyz"; var regexp = //gi; var matches = str.match(regexp); document.write(matches); // matches =
Метод replace может заменять вхождения регулярного выражения не только на строку, но и на результат выполнения функции. Его полный синтаксис — такой:
var newString = str.replace(regexp/substr, newSubStr/function)
- Объект RegExp. Его вхождения будут заменены на значение, которое вернет параметр номер 2
- Строка, которая будет заменена на .
- Строка, которая заменяет подстроку из аргумента номер 1.
- Функция, которая может быть вызвана для генерации новой подстроки (чтобы подставить ее вместо подстроки, полученной из аргумента 1).
Метод не меняет строку, на которой вызван, а просто возвращает новую, измененную строку.
Чтобы осуществить глобальную замену, включите в регулярное выражение флаг .
Если первый аргумент — строка, то она не преобразуется в регулярное выражение, так что, например,
var ab = "a b".replace("\\s","..") // = "a b"
Вызов replace оставил строку без изменения, т.к искал не регулярное выражение , а строку «\s».
В строке замены могут быть такие спецсимволы:
| Pattern | Inserts |
| Вставляет «$». | |
| Вставляет найденную подстроку. | |
| Вставляет часть строки, которая предшествует найденному вхождению. | |
| Вставляет часть строки, которая идет после найденного вхождения. | |
| or | Где или — десятичные цифры, вставляет подстроку вхождения, запомненную -й вложенной скобкой, если первый аргумент — объект RegExp. |
Если Вы указываете вторым параметром функцию, то она выполняется при каждом совпадении.
В функции можно динамически генерировать и возвращать строку подстановки.
Первый параметр функции — найденная подстрока. Если первым аргументом является объект , то следующие параметров содержат совпадения из вложенных скобок. Последние два параметра — позиция в строке, на которой произошло совпадение и сама строка.
Например, следующий вызов возвратит XXzzzz — XX , zzzz.
function replacer(str, p1, p2, offset, s)
{
return str + " - " + p1 + " , " + p2;
}
var newString = "XXzzzz".replace(/(X*)(z*)/, replacer)
Как видите, тут две скобки в регулярном выражении, и потому в функции два параметра , .
Если бы были три скобки, то в функцию пришлось бы добавить параметр .
Следующая функция заменяет слова типа на :
function styleHyphenFormat(propertyName)
{
function upperToHyphenLower(match)
{
return '-' + match.toLowerCase();
}
return propertyName.replace(//, upperToHyphenLower);
}
Parse Apache Logs
Most websites are running on the Apache webserver. If your website does, you can easily use PHP and regular expressions to parse Apache logs.
//Logs: Apache web server //Successful hits to HTML files only. Useful for counting the number of page views. '^((?#client IP or domain name)S+)s+((?#basic authentication)S+s+S+)s+]+)]s+"(?:GET|POST|HEAD) ((?#file)/+?.html?)??((?#parameters)+)? HTTP/+"s+(?#status code)200s+((?#bytes transferred)+)s+"((?#referrer)*)"s+"((?#user agent)*)"$' //Logs: Apache web server //404 errors only '^((?#client IP or domain name)S+)s+((?#basic authentication)S+s+S+)s+]+)]s+"(?:GET|POST|HEAD) ((?#file)+)??((?#parameters)+)? HTTP/+"s+(?#status code)404s+((?#bytes transferred)+)s+"((?#referrer)*)"s+"((?#user agent)*)"$'
» Source
Скобки
Скобки ([]) имеют особое значение при использовании в контексте регулярных выражений. Они используются для поиска диапазона символов.
| # | Значение | Описание |
|---|---|---|
| Он соответствует любой десятичной цифре от 0 до 9. | ||
| Он соответствует любому символу от нижнего регистра a до нижнего регистра z. | ||
| Он соответствует любому символу в верхнем регистре A в верхнем регистре Z. | ||
| Он соответствует любому символу от нижнего регистра a до верхнего регистра Z. |
Диапазоны, показанные выше, являются общими; вы также можете использовать диапазон для соответствия любой десятичной цифре в диапазоне от 0 до 3 или диапазону , чтобы соответствовать любому строчному символу в диапазоне от b до v.
Как заменить один текст на другой, используя регулярные выражения?
Для изменения текста, используйте .
Рассмотрим следующую измененную версию текста курсов. Здесь добавлена табуляция после каждого кода курса.
Из вышеприведенного текста я хочу удалить все лишние пробелы и записать все слова в одну строку.
Для этого нужно просто использовать для замены шаблона на один пробел .
или
Предположим, вы хотите избавиться от лишних пробелов и выводить записи курса с новой строки. Чтобы это сделать, используйте регулярное выражение, которое пропускает символ новой строки, но учитывает все другие пробелы.
Это можно сделать, используя отрицательное соответствие . Шаблон проверяет наличие символа новой строки, в python это , и пропускает его.
Наиболее распространенный синтаксис и шаблоны регулярных выражений
Теперь, когда вы знаете как пользоваться модулем re, давайте рассмотрим некоторые обычно используемые шаблоны подстановок.
Основной синтаксис
| . | Один символ кроме новой строки |
| \. | Просто точка , обратный слеш убирает магию всех специальных символов. |
| \d | Одна цифра |
| \D | Один символ кроме цифры |
| \w | Один буквенный символ, включая цифры |
| \W | Один символ кроме буквы и цифры |
| \s | Один пробельный (включая таб и перенос строки) |
| \S | Один не пробельный символ |
| \b | Границы слова |
| \n | Новая строка |
| \t | Табуляция |
Модификаторы
| $ | Конец строки |
| ^ | Начало строки |
| ab|cd | Соответствует ab или de. |
| Один символ: a, b, c, d | |
| Любой символ, кроме: a, b, c, d | |
| () | Извлечение элементов в скобках |
| (a(bc)) | Извлечение элементов в скобках второго уровня |
Повторы
| {2} | 2 непрерывных появления a или b |
| {2,5} | от 2 до 5 непрерывных появления a или b |
| {2,} | 2 и больше непрерывных появления a или b |
| + | одно или больше |
| * | 0 или больше |
| ? | 0 или 1 |
Модификаторы
Доступны несколько модификаторов, которые могут облегчить вашу работу с регулярными выражениями , например, чувствительность к регистру, поиск по нескольким линиям и т.д.
| Модификатор | Описание |
|---|---|
| i | Делает регистр без учета регистра |
| m | Указывает, что если строка имеет новую строку или каретку возвращаемые символы, теперь будут выполняться операторы ^ и $ сопоставление с границей новой строки, а не граница строки |
| o | оценивает выражение только один раз |
| s | Позволяет использовать. для соответствия символу новой строки |
| x | Позволяет использовать пробел в выражении для ясности |
| g | Глобально находит все совпадения |
| cg | Позволяет продолжить поиск даже после сбоя глобального соответствия |
2 Практический раздел. Ссылки
Перед тем, как использовать регулярные выражения, стоит посмотреть в документацию по вашему языку программирования и используемой библиотеке, так как диалекты обладают особенностями. Например в Perl и некоторых версиях php можно описывать рекурсивные регулярные выражения, которые не поддерживаются большинством других реализаций; механизмом флагов отличается JavaScript и так далее. Незначительными отличиями могут обладать даже различные версии одной и той же библиотеки.
Отличаются регулярные выражения не только синтаксисом, но и реализацией. Регулярные выражения — это «не просто так». Строка, задающее выражение, преобразуется в автомат, от реализации которого зависит эффективность. Масштаб проблемы хорошо иллюстрирует график зависимости времени выполнения поиска от длины строки и реализации:

Картинка взята из статьи «Поиск с помощью регулярных выражений может быть простым и быстрым«. В ней можно прочитать про различные реализации выражений, а также о том, как написать выражение так, чтобы оно работало быстрее. Кстати, так как выражение преобразуется в автомат, то зачастую его удобно визуализировать — для этого есть специальные сервисы, например. Для последнего выражения статьи будет построен такой автомат:
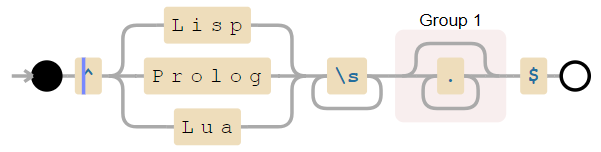
Примеры использования регулярных выражений:
- для валидации вводимых в поля данных: QValidator примеры использования. Ряд библиотек построения графического пользовательского интерфейса позволяют закреплять к полям ввода валидаторы, которые не позволяет ввести в формы некорректные данные. По приведенной выше ссылке можно найти валидацию номера банковской карты и номера телефона с помощью регулярных выражений библиотеки Qt. Аналогичные механизмы есть в других языках, например в Java для этого используется пакет ;
- для парсинга сайтов: Парсер сайта на Qt, использование QRegExp. В примере с сайта-галереи выбираются и скачиваются картинки заданных категорий;
- для валидации данных, передаваемых в формате JSON ряд библиотек позволяет задавать схему. При этом для строковых полей могут быть заданы регулярные выражения. В качестве упражнения можно попробовать составить выражение для пароля — проверить что строка содержит символы в разном регистре и цифры.
В сообществе Программирование и алгоритмы можно посмотреть дополнительную литературу по теме. Книгу Гойвертса и Левитана рекомендую посмотреть особенно, так как в ней по-полочкам разобраны десятки примеров, причем с учетом специфики реализации регулярных выражений в конкретных языках программирования.