What is meta charset and how do you use it?
Содержание:
История создания
До появления Unicode UTF-8 широко использовались другие кодировки (ASCII, ISO/IEC 646, ISO/IEC 8859, KOI8, Windows-125x).
Впервые кодировка UTF-8 была официально представлена на конференции USENIX в Сан Диего в январе 1993. От других мультибайтных кодировок ее отличала полная совместимость с ASCII: все символы ASCII в UTF-8 кодируются 7 битами. Каждый символ кодировки, отличный от ASCII, состоит из ведущего байта, указывающего длину последовательности, и одного или нескольких продолжающих байт. Такой принцип позволяет определить длину последовательности только по первому байту. Коды символов ASCII, ведущих и продолжающих байт не пересекаются, что позволяет легко найти начало последовательности простым откатом назад максимум на пять байт.
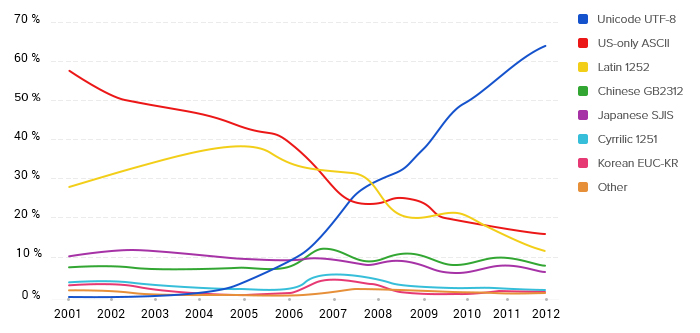 График изменения популярности кодировок в интернете
График изменения популярности кодировок в интернете
В ноябре 2003 года стандартом RFC-3629 максимальная длина последовательности UTF-8 была ограничена четырьмя байтами, однако потенциально UTF-8 позволяет использовать последовательности вплоть до шести байт.
На сегодняшний день самой распространенной кодировкой является UTF-8. Она включает в себя более двух миллионов символов: все возможные современные алфавиты, цифры, знаки препинания, математические и специальные символы, музыкальные знаки и символы вымерших форм письменности. А резерва UTF-8 хватит для размещения более двух миллиардов символов. Так что о смене кодировки в ближайшее время задумываться не придётся.
Однако торжество современных технологий — явление относительно новое. Согласно Google, самой распространенной в интернете кодировкой UTF-8 стала только в 2008 году — тогда ее использовали чуть более чем 25% проиндексированных веб-страниц. А еще в 2006 UTF-8 использовали менее чем 10% веб-страниц.
Стремительный рост популярности кодировки UTF-8 связан с целым рядом ее преимуществ перед предшественницами.
Переход к Unicode
Развитие интернета, увеличение количества компьютеров и удешевление памяти привели к тому, что проблемы, которые доставляла путаница в кодировках, стали перевешивать некоторую экономию памяти. Особенно ярко это проявлялось в интернете, когда текст написанный на одном компьютере должен был корректно отображаться на многих других устройствах. Это доставляло огромные проблемы как программистам, которые должны были решать какую кодировку использовать, так и конечным пользователям, которые не могли получить доступ к интересующим их текстам.
В результате в октябре 1991 года появилась первая версия одной общей таблицы символов, названной Unicode. Она включала в себя на тот момент 7161 различный символ из 24 письменностей мира.
В Unicode постепенно добавлялись новые языки и символы. Например, в версию 1.0.1 в середине 1992 года добавили более 20 000 идеограмм китайского, японского и корейского языков. В актуальной на текущий момент версии содержится уже более 143 000 символов.
Неправильная кодировка HTML страниц
Создадим тестовый файлик:
sudo gedit /var/www/html/encoding.html
Скопируем в него следующий HTML код, в котором отсутствует указание кодировки и посмотрим, какие проблемы могут с ним возникнуть и как их решить:
<html>
<head>
<title>Проверка кодировки</title>
</head>
<body>
<h1>Тестовый файл для проверки кодировки</h1>
</body>
</html>
Откроем этот файл в браузере http://localhost/encoding.html
Как можно видеть, кодировка браузером определена неправильно:
Имеется несколько способов исправить эту ситуацию. Начнём с самого простого – явно указать кодировку для веб-страницы. Это делается метатегом, который должен быть расположен внутри тэга head:
<meta http-equiv="content-type" content="text/html; charset=utf-8" />
Добавим эту строку к нашему тестовому файлику, чтобы получилось так:
<html>
<head>
<title>Проверка кодировки</title>
<meta http-equiv="content-type" content="text/html; charset=utf-8" />
</head>
<body>
<h1>Тестовый файл для проверки кодировки</h1>
</body>
</html>
Как мы можем убедиться на следующем скриншоте, проблема решена:
Если кодировка вашего файла отличается от UTF-8, то вместо неё поставьте windows-1251 или ту, которая соответствует кодировке веб-страницы. Чтобы научиться определять кодировку файлов, посмотрите эту инструкцию.
Это был самый простой способ исправления проблемы с кодировкой – без изменения настроек сервера.
Вернём наш тестовый файл в исходное состояние и продолжим изучение способов указания кодировки.
Если файлы .htaccess включены настройками Apache, то эти файлы можно использовать чтобы указывать кодировку отправляемых веб-сервером страниц. Чтобы включить поддержку файлов .htaccess в конфигурационном файле Apache ( /etc/apache2/apache2.conf ) найдите группу строк
<Directory /var/www/> Options Indexes FollowSymLinks AllowOverride None Require all granted </Directory>
И в ней замените
AllowOverride None
на
AllowOverride All
После этого сервер нужно перезапустить.
sudo systemctl restart apache2.service
Файл .htaccess должен быть размещён в той же директории, что и сайт. Мой сайт размещён в корневой директории веб-сервера. Если у вас также, то теперь в папке /var/www/html/ создайте файл .htaccess и добавьте в него директиву AddDefaultCharset после которой укажите желаемую кодировку. Примеры
AddDefaultCharset UTF-8
ИЛИ
AddDefaultCharset windows-1251
Можно указать кодировку, которая будет применена только к файлам определённого формата:
AddCharset utf-8 .atom .css .js .json .rss .vtt .xml
Набор файлов может быть любым, например:
AddCharset utf-8 .html .css .php .txt .js
Следующий вариант является альтернативным и также позволяет устанавливать кодировку для файлов определённого типа, для него нужно, чтобы был включён mod_headers:
<Files ~ "\.html?$">
Header set Content-Type "text/html; charset=utf-8"
</Files>
Ещё один вариант, который также можно использовать в файле .htaccess для установки кодировки UTF-8:
IndexOptions +Charset=utf-8
Если сайт на PHP, то дополнительно может понадобиться продублировать кодировку с php_value default_charset:
AddDefaultCharset windows-1251 php_value default_charset "cp1251"
Можно вместо создания файла .htaccess установить кодировку в конфигурационном файле веб-сервера. Для Apache CentOS/Fedora это файл httpd.conf, а на Debian/Ubuntu это файл apache2.conf. Добавьте следующую строку для установки кодировки и перезапустите веб-сервер, чтобы изменения вступили в силу:
AddDefaultCharset UTF-8
How does it work?
Meta Charset is what determines how text is transmitted and stored. This text data is usually converted to binary first and then there needs to be a kind of cipher that connects characters with their correct binary equivalents.
When this data is eventually decoded, the character encoding must be known beforehand or there could be complications. An example of these can be seen in browsers when you’re looking at a webpage. Information about the kind of character set used comes from the server or is written directly by the developer. Unfortunately, there is a myriad of character sets and this means diverse ways of matching binary codes to characters and bytes.
For content developers and authors, choosing the UTF-8 character set for your content means that you can use a single character set to multiple characters needs thereby simplifying things greatly without the need to track and convert multiple times. This means it would be easier to surf through your content without getting confusing characters and garbage
UTF-8 против UTF-16
Как я уже упоминал, UTF-8 – не единственный метод кодирования символов Unicode – существует также UTF-16. Эти методы различаются количеством байтов, необходимых для хранения символа. UTF-8 кодирует символ в двоичную строку из одного, двух, трех или четырех байтов. UTF-16 кодирует символ Unicode в строку из двух или четырех байтов.
Это различие видно из их названий. В UTF-8 наименьшее двоичное представление символа составляет один байт или восемь битов. В UTF-16 наименьшее двоичное представление символа составляет два байта или шестнадцать бит.
И UTF-8, и UTF-16 могут переводить символы Unicode в двоичные файлы, удобные для компьютера, и обратно. Однако они несовместимы друг с другом. Эти системы используют разные алгоритмы для сопоставления кодовых точек с двоичными строками, поэтому двоичный вывод для любого заданного символа будет отличаться от обоих методов:
| символ | Двоичная кодировка UTF-8 | Двоичная кодировка UTF-16 |
| А | 01000001 | 01000001 11011000 00001110 11011111 |
| ? | 11110000 10100000 10011100 10001110 | 01000001 11011000 00001110 11011111 |
Кодировка UTF-8 предпочтительнее UTF-16 на большинстве веб-сайтов, потому что она использует меньше памяти. Напомним, что UTF-8 кодирует каждый символ ASCII всего одним байтом. UTF-16 должен кодировать эти же символы в двух или четырех байтах. Это означает, что текстовый файл на английском языке с кодировкой UTF-16 будет как минимум вдвое больше размера того же файла с кодировкой UTF-8.
UTF-16 более эффективен, чем UTF-8, только на некоторых неанглоязычных сайтах. Если веб-сайт использует язык с символами, находящимися дальше в библиотеке Unicode, UTF-8 будет кодировать все символы как четыре байта, тогда как UTF-16 может кодировать многие из тех же символов только как два байта. Тем не менее, если ваши страницы заполнены буквами ABC и 123, придерживайтесь UTF-8.
Кодировки стандарта UNICODE
Юникод (англ. Unicode) — стандарт кодирования символов, позволяющий представить знаки почти всех письменностей мира, и специальных символов. Представляемые в юникоде символы кодируются целыми числами без знака. Юникод имеет несколько форм представления символов в компьютере: UTF-8, UTF-16 (UTF-16BE, UTF-16LE) и UTF-32 (UTF-32BE, UTF-32LE). (Англ. Unicode transformation format — UTF).UTF-8 — это в настоящее время распространённая кодировка, которая нашла широкое применение в операционных системах и веб-пространстве. Текст, состоящий из символов Unicode с номерами меньше 128 (область с кодами от U+0000 до U+007F), содержит символы набора ASCII с соответствующими кодами. Далее расположены области знаков различных письменностей, знаки пунктуации и технические символы. Под символы кириллицы выделены области знаков с кодами от U+0400 до U+052F, от U+2DE0 до U+2DFF, от U+A640 до U+A69F.
Кодировка UTF-8 является универсальной и имеет внушительный резерв на будущее. Это делает ее наиболее удобной кодировкой для использования в интернете.
HTML Символы
Кодирование URL
Кодировки на основе Unicode
Unicode можно себе представить как огромную таблицу символов. В памяти компьютера записываются не сами символы, а номера из таблицы. Записывать их можно разными способами. Именно для этого на основе Unicode разработаны несколько кодировок, которые отличаются способом записи номера символа Unicode в виде набора байт. Они называются UTF — Unicode Transformation Format. Есть кодировки постоянной длины, например, UTF-32, в которой номер любого символа из таблицы Unicode занимает ровно 4 байта. Однако наибольшую популярность получила UTF-8 — кодировка с переменным числом байт. Она позволяет кодировать символы так, что наиболее распространённые символы занимают 1-2 байта, и только редко встречающиеся символы могут использовать по 4 байта. Например, все символы таблицы ASCII занимают ровно по одному байту, поэтому текст, написанный на английском языке с использованием кодировки UTF-8, будет занимать столько же места, как и текст, написанный с использованием таблицы символов ASCII.
На сегодняшний день Unicode является основной кодировкой, которую используют в работе все, кто связан с компьютерами и текстами. Unicode позволяет использовать сотни тысяч различных символов и отображать их одинаково на всех устройствах от мобильных телефонов до компьютеров на космических станциях.
Значение и применение
Тег <meta> обеспечивает метаданные о HTML документе. Метаданные не отображаются на странице, но интерпретируются браузерами и поисковыми системами.
Мета элементы, как правило, используются, чтобы указать описание страницы, ключевые слова, автора документа и другие метаданные. Разрешается и, как правило, необходимо использовать несколько метатегов. Тег <meta> всегда размещается внутри тега <head>.
XHTML требует закрывающего тега <meta/>, в HTML элемент считается одиночным.
Подробную информацию о использовании мета тегов вы можете получить также в статье учебника HTML 5 «Метаданные в HTML».
UTF-8 Basic Latin
| Char | Dec | Hex | Entity | Name |
|---|---|---|---|---|
| 32 | 0020 | SPACE | ||
| ! | 33 | 0021 | EXCLAMATION MARK | |
| « | 34 | 0022 | " | QUOTATION MARK |
| # | 35 | 0023 | NUMBER SIGN | |
| $ | 36 | 0024 | DOLLAR SIGN | |
| % | 37 | 0025 | PERCENT SIGN | |
| & | 38 | 0026 | & | AMPERSAND |
| ‘ | 39 | 0027 | APOSTROPHE | |
| ( | 40 | 0028 | LEFT PARENTHESIS | |
| ) | 41 | 0029 | RIGHT PARENTHESIS | |
| * | 42 | 002A | ASTERISK | |
| + | 43 | 002B | PLUS SIGN | |
| , | 44 | 002C | COMMA | |
| — | 45 | 002D | HYPHEN-MINUS | |
| . | 46 | 002E | FULL STOP | |
| 47 | 002F | SOLIDUS | ||
| 48 | 0030 | DIGIT ZERO | ||
| 1 | 49 | 0031 | DIGIT ONE | |
| 2 | 50 | 0032 | DIGIT TWO | |
| 3 | 51 | 0033 | DIGIT THREE | |
| 4 | 52 | 0034 | DIGIT FOUR | |
| 5 | 53 | 0035 | DIGIT FIVE | |
| 6 | 54 | 0036 | DIGIT SIX | |
| 7 | 55 | 0037 | DIGIT SEVEN | |
| 8 | 56 | 0038 | DIGIT EIGHT | |
| 9 | 57 | 0039 | DIGIT NINE | |
| 58 | 003A | COLON | ||
| ; | 59 | 003B | SEMICOLON | |
| < | 60 | 003C | < | LESS-THAN SIGN |
| = | 61 | 003D | EQUALS SIGN | |
| > | 62 | 003E | > | GREATER-THAN SIGN |
| ? | 63 | 003F | QUESTION MARK | |
| @ | 64 | 0040 | COMMERCIAL AT | |
| A | 65 | 0041 | LATIN CAPITAL LETTER A | |
| B | 66 | 0042 | LATIN CAPITAL LETTER B | |
| C | 67 | 0043 | LATIN CAPITAL LETTER C | |
| D | 68 | 0044 | LATIN CAPITAL LETTER D | |
| E | 69 | 0045 | LATIN CAPITAL LETTER E | |
| F | 70 | 0046 | LATIN CAPITAL LETTER F | |
| G | 71 | 0047 | LATIN CAPITAL LETTER G | |
| H | 72 | 0048 | LATIN CAPITAL LETTER H | |
| I | 73 | 0049 | LATIN CAPITAL LETTER I | |
| J | 74 | 004A | LATIN CAPITAL LETTER J | |
| K | 75 | 004B | LATIN CAPITAL LETTER K | |
| L | 76 | 004C | LATIN CAPITAL LETTER L | |
| M | 77 | 004D | LATIN CAPITAL LETTER M | |
| N | 78 | 004E | LATIN CAPITAL LETTER N | |
| O | 79 | 004F | LATIN CAPITAL LETTER O | |
| P | 80 | 0050 | LATIN CAPITAL LETTER P | |
| Q | 81 | 0051 | LATIN CAPITAL LETTER Q | |
| R | 82 | 0052 | LATIN CAPITAL LETTER R | |
| S | 83 | 0053 | LATIN CAPITAL LETTER S | |
| T | 84 | 0054 | LATIN CAPITAL LETTER T | |
| U | 85 | 0055 | LATIN CAPITAL LETTER U | |
| V | 86 | 0056 | LATIN CAPITAL LETTER V | |
| W | 87 | 0057 | LATIN CAPITAL LETTER W | |
| X | 88 | 0058 | LATIN CAPITAL LETTER X | |
| Y | 89 | 0059 | LATIN CAPITAL LETTER Y | |
| Z | 90 | 005A | LATIN CAPITAL LETTER Z | |
| 91 | 005B | LEFT SQUARE BRACKET | ||
| \ | 92 | 005C | REVERSE SOLIDUS | |
| 93 | 005D | RIGHT SQUARE BRACKET | ||
| ^ | 94 | 005E | CIRCUMFLEX ACCENT | |
| _ | 95 | 005F | LOW LINE | |
| ` | 96 | 0060 | GRAVE ACCENT | |
| a | 97 | 0061 | LATIN SMALL LETTER A | |
| b | 98 | 0062 | LATIN SMALL LETTER B | |
| c | 99 | 0063 | LATIN SMALL LETTER C | |
| d | 100 | 0064 | LATIN SMALL LETTER D | |
| e | 101 | 0065 | LATIN SMALL LETTER E | |
| f | 102 | 0066 | LATIN SMALL LETTER F | |
| g | 103 | 0067 | LATIN SMALL LETTER G | |
| h | 104 | 0068 | LATIN SMALL LETTER H | |
| i | 105 | 0069 | LATIN SMALL LETTER I | |
| j | 106 | 006A | LATIN SMALL LETTER J | |
| k | 107 | 006B | LATIN SMALL LETTER K | |
| l | 108 | 006C | LATIN SMALL LETTER L | |
| m | 109 | 006D | LATIN SMALL LETTER M | |
| n | 110 | 006E | LATIN SMALL LETTER N | |
| o | 111 | 006F | LATIN SMALL LETTER O | |
| p | 112 | 0070 | LATIN SMALL LETTER P | |
| q | 113 | 0071 | LATIN SMALL LETTER Q | |
| r | 114 | 0072 | LATIN SMALL LETTER R | |
| s | 115 | 0073 | LATIN SMALL LETTER S | |
| t | 116 | 0074 | LATIN SMALL LETTER T | |
| u | 117 | 0075 | LATIN SMALL LETTER U | |
| v | 118 | 0076 | LATIN SMALL LETTER V | |
| w | 119 | 0077 | LATIN SMALL LETTER W | |
| x | 120 | 0078 | LATIN SMALL LETTER X | |
| y | 121 | 0079 | LATIN SMALL LETTER Y | |
| z | 122 | 007A | LATIN SMALL LETTER Z | |
| { | 123 | 007B | LEFT CURLY BRACKET | |
| | | 124 | 007C | VERTICAL LINE | |
| } | 125 | 007D | RIGHT CURLY BRACKET | |
| ~ | 126 | 007E | TILDE |
HTTP-Headers, SQL, HTML и Meta-Charset
С некоторых пор браузеры игнорируют meta-объявления «charset», а
руководствуются только служебными заголовками со стороны WEB-сервера – HTTP-Headers, но и стандарты w3 оформления HTML-разметки никто не отменял.
Оформление HTML
Первое, на что требуется обратить внимание, это корректное объявление стандарта HTML.
Самая распространённая ошибка верстальщика – добавить «для красоты» в начале документа пробелы и переводы строк. Второе: объявление контейнера html прописывать строго по стандарту в соответствии с объявленным /blockquote>
Второе: объявление контейнера html прописывать строго по стандарту в соответствии с объявленным <!DOCTYPE.
Третье: объявление языка и кодировки.
Meta charset и Meta language, всё-таки, надо прописывать в соответствии с w3-стандартами.
«DOCTYPE» должен находится в самом начале HTML-документа идаже пробела или перевода строки НЕ должно быть перед «<!doctype»;
HTML-контейнер объявляется с дополнительными параметрами;
Обязательно указывайте кодировку и основной язык документа.
Этот код свёрстан правильно
Отправка HTTP-Headers и .htaccess
Обратите внимание, что HTTP-заголовки можно отправлять только ДО отдачи контента клиенту! Даже пробел не должен вылететь впереди заголовков. Отправить служебные http-заголовки со стороны сервера можно двумя способами:
Отправить служебные http-заголовки со стороны сервера можно двумя способами:
1. В php-скриптах принудительно отправлять с сервера заголовок
2. Если сервер поддерживает .htaccess, то создать или отредактировать файл .htaccess в корне сайта
и добавить строку
или, при физическом доступе к серверу apache можно настроить дефолтную кодировку: раскоментировать/добавить в httpd.conf
И подправить настройки интерпретатора PHP в php.ini
Файлы в UTF-8
- Не забывайте файлы с НЕ латиницей сохранять в UTF-8!
- Если источник данных — файл в UTF-8, имейте ввиду, что файл может (будет) иметь Unicode-BOM (трёх-байтный префикс в начале) EF,BB,BF!Учитывайте это при прямом доступе. В идеале, для HTML-документа надо удалять любые префиксы.
Для редактирования файлов используйте специальные редакторы для WEB-вёрстки - Отсылать правильные заголовки charset перед отдачей клиенту.
Базы данных в UTF-8
По возможности прописать дефлтные настройки кодировки сервера MySQL в my.cnf:
Для SQL-баз сразу объявляйте кодировку в utf-8, при необходимости дополнительно объявляйте кодировку таблиц и полей.
Определяйте внутренюю кодировку SQL-сервера и кодировку соединения: SET NAMES и SET CHARACTER SET.
Например, для драйверов PHP mysql_ надо отправить запросы сразу после коннекта:
Эти два запроса отвечают сразу за 6 установок внутренней кодировки сервера и соединения. Если на странных SQL-серверах не поможет, то читайте документацию по SQL/MySQL раздел «Connection Character Sets and Collations». Возможно вам придётся отправлять все шесть sql-запросов по отдельности:
Указание кодировки символов документа
Есть несколько способов указать, какая кодировка символов используется в документе. Во-первых, веб-сервер может включать кодировку символов или » » в заголовок протокола передачи гипертекста (HTTP) , который обычно выглядит следующим образом:
Content-Type: text/html; charset=utf-8
Этот метод дает HTTP-серверу удобный способ изменить кодировку документа в соответствии с согласованием содержимого ; определенное программное обеспечение HTTP-сервера может это сделать, например Apache с модулем .
Для HTML можно включить эту информацию внутри элемента в верхней части документа:
<meta http-equiv="Content-Type" content="text/html; charset=utf-8">
HTML5 также позволяет следующему синтаксису означать то же самое:
<meta charset="utf-8">
У документов XHTML есть третий вариант: выразить кодировку символов через объявление XML следующим образом:
<?xml version="1.0" encoding="ISO-8859-1"?>
Поскольку кодировка символов не может быть известна до тех пор, пока это объявление не будет проанализировано, может возникнуть проблема, зная, какая кодировка используется для самого объявления. Главный принцип заключается в том, что объявление должно быть закодировано в чистом ASCII, и поэтому (если объявление находится внутри файла) кодировка должна быть расширением ASCII . Для того чтобы кодировки не были обратно совместимы с ASCII, браузеры должны иметь возможность анализировать объявления в таких кодировках. Примеры таких кодировок — UTF-16BE и UTF-16LE .
Начиная с HTML5, рекомендуемая кодировка — UTF-8 . В спецификации определен «алгоритм сниффинга кодирования» для определения кодировки символов документа на основе нескольких источников ввода, включая:
- Явная инструкция пользователя
- Явный метатег в первых 1024 байтах документа.
- Отметка порядка байтов в течение первых трех байтов документа
- HTTP Content-Type или другая информация транспортного уровня
- Анализ байтов документа в поисках определенных последовательностей или диапазонов значений байтов и другие механизмы предварительного обнаружения.
Для ASCII-совместимых кодировок символов следствием неправильного выбора является то, что символы за пределами печатаемого диапазона ASCII (от 32 до 126) обычно отображаются неправильно. Это создает несколько проблем для английских -speaking пользователей, но и другие языки регулярно , в некоторых случаях, всегда требуют-символы за пределами этого диапазона. В средах CJK, где используется несколько различных многобайтовых кодировок, также часто используется автоматическое обнаружение. Наконец, браузеры обычно позволяют пользователю вручную переопределить неправильную метку кодировки.
Для многоязычных веб-сайтов и веб-сайтов на незападных языках все чаще используется UTF-8 , который позволяет использовать одну и ту же кодировку для всех языков. UTF-16 или UTF-32 , которые также могут использоваться для всех языков, менее широко используются, потому что их может быть труднее обрабатывать в языках программирования, которые предполагают байтовую кодировку расширенного набора ASCII, и они менее эффективны для текста с высокая частота символов ASCII, что обычно характерно для документов HTML.
Успешный просмотр страницы не обязательно означает, что ее кодировка указана правильно. Если создатель страницы и читатель оба предполагают некоторую кодировку символов, зависящую от платформы, и сервер не отправляет никакой идентифицирующей информации, то читатель, тем не менее, будет видеть страницу так, как задумал создатель, но другие читатели на разных платформах или с разными родными языками не увидит страницу должным образом.
Теперь рассмотрим коротко POST.
В отличие от GET запросов, в POST передается Content-type, который сообщает серверному скрипту информацию, о том с какими данными он работает и возможность указания кодировки. Например, в Jquery по умолчанию AJAX передает «application/x-www-form-urlencoded; charset=utf-8», но даже если вы укажите “text/html; charset=utf-8”, то данные приходящие будут в utf-8, так как при передачи данных, Jquery формирует escape-последовательность, функцией, о которой писалось выше.
Но это не так страшно, потому что у нас есть всегда возможность перевести кодировку и уже работать с данными. При этом отдавать результаты мы можем в нашей любимой кодировке, главное не забывайте ставить заголовок, с указанием кодировки, если вдруг вы обратно получаете «каказябры».
Например:
header('Content-type: text/html; charset=utf-8');
или:
header('Content-type: text/html; charset=utf-8');
Вывод: для того что бы не было проблем с кодировками, при передачи данных через AJAX, нужно использовать encodeURIComponent(). Если ваш серверный скрипт, который принимает запросы, работает в другой кодировке, отличной от utf-8, то надо пользоваться php функцией iconv и устанавливать заголовок header.
Почему Description не отображается в Яндекс?
Бывает так, что Вы указали дескрипшен, а он не отображается… И скорее всего, так и будет для многих запросов, по которым видите сайт в результатх поиска. Это нормальная ситауция. Давайте вспомним, как всё было…
Ранее, в поисковых системах, этот тег был одним из факторов для успешного развития сайта (скорее даже для правильного отображения на поиске), наряду ещё с одним мета тегом, под названием keywords (тег ключевых слов). Суть этих тегов в том, чтобы помочь поисковому роботу определить правильное содержание страницы (в случае с дескрипшен). Но слово “содержание”, правильней взять в кавычки, и скорее это краткое содержимое страницы. И его заполняли раньше активно, наряду с мета тегом keywords. И в коде страницы, эти теги выглядели так:
<html> <head> ... <meta name="description" content="Краткое содержимое страницы" /> <meta name="keywords" content="ключевые слова" /> ... </head> <body> ... </body> </html>
И выше самый простой пример, как выглядят страницы сайта в интернете на самом деле, и то как видит их поисковый робот, читая информацию внутри содержимого специальных тегов. Так, есть парный тег <head> </head>, который является контейнером для других элементов, среди которых, могут содержаться различные метаданные о странице, а также заголовок title, и ссылки на скрипты и таблицы стилей.
Так вот, про метаданные – это не парные теги, и у каждого из них – есть свои цели. Так, description – содержит в себе краткое описание страницы, чтобы посетитель мог понять, что его ждёт на странице. А keywords – помогал роботу определить, под какие поисковые фразы продвигается страница. Это знаете, когда поисковые алгоритмы были не настолько совершенны, и обращали на этот мета тег больше внимания. И все вебмастера, старались разместить в этот тег, как можно больше ключевых фраз через запятую. Как всё просто… Не так ли? ))
Раньше была такая ситуация, что содержимое из мета тега description, отображалось в сниппетах поисковой системы. И касаемо дескрипшен, конкретно в этом месте…
И это содержимое бралось не из контента страницы, а из тега description. Также титульный заголовок (title) брался исключительно из заголовка, который располагался между тегов titile. И вот пример, как это выглядит в коде страницы, между тегов head:
Раньше большой “упор” делали на титульный заголовок, и другие заголовки по значимости (h1,h2,h3 и др.). И конечно же, много много ключевых слов вствляли в мета тег keywords. Вот только прошло время, и поисковая система уже сама определяет наиболее релевантный сниппет под каждый запрос посетителя. И значимость заголовков, сейчас выше, чем была раньше. В том плане выше, что делать приоритет только на титульный заголовок – не правильно. h1,h2,h3 – также могут подставляться в сниппет поисковой системы, не зависимо от информации в титульном заголовке. Хотя он и является обязательным. На большинстве сайтов, мы его просто дублируем с h1 заголовком.
Тоже самое, и с мета тегом description. Его значимость можно сказать – минимальна, и большого приоритета в нем не наблюдается. Гугл так и вовсе не делает на него акцент, если не врут источники. Хорошо.
Посмотите, пример…
Вбиваем другой запрос, и нам эта же страница, выводится с другим заголовком и другим кратким описанием. То есть, поисковый робот сам посчитал, что правильней отобразить посетителю под запрос. Анализируется страница, и выдергиваются нужные данные для сниппета. И под каждый запрос – данные отличаются (сравните со скрином выше, отображается одна и таже страница, только с разными сниппетами описания и заголовка).
Не сложно догадаться, что мета тег keywords вовсе не актуален сейчас. И смысла его заполнять нет, так как это скорее вызовет обратный эффект в продвижении сайта. Гугл открыто заявлял, что с 2007 года, не учитывает этот тег. Для яндекса, ситуация аналогична с этим мета тегом, хотя где-то есть отголоски того, что возможно есть учет ключевых слов в этом мета теги. В современном мире, значимость мета тега keywords по 10 бальной шкале, была бы скорее всего равна 0. Но это моё мнение.
Возникает вопрос…