Что такое кодировка windows 1251
Содержание:
Введение
Консольные приложения до сих пор остаются наиболее востребованным видом приложений, большинство разработчиков оттачивают архитектуру и бизнес-логику именно в консоли. При этом они нередко сталкиваются с проблемой локализации — русский текст, который вполне адекватно отражается в исходном файле, при выводе на консоль приобретает вид т.н. «кракозябр».
В целом, локализация консоли Windows при наличии соответствующего языкового пакета не представляется сложной. Тем не менее, полное и однозначное решение этой проблемы, в сущности, до сих пор не найдено. Причина этого, главным образом, кроется в самой природе консоли, которая, являясь компонентом системы, реализованным статическим классом System.Console, предоставляет свои методы приложению через системные программы-оболочки, такие как командная строка или командный процессор (cmd.exe), PowerShell, Terminal и другие. По сути, консоль находится под двойным управлением — приложения и оболочки, что является потенциально конфликтной ситуацией, в первую очередь в части использования кодировок.
Данный материал не предлагает строгий алгоритм действий, а направлен на описание узловых проблем, с которыми неизбежно сталкивается разработчик локализованного консольного приложения, а также некоторые возможные пути их разрешения. Предполагается, что это позволит разработчику сформировать стратегию работы с локализованной консолью и эффективно реализовать существующие технические возможности, большая часть которых хорошо описана и здесь опущена.
Распространенные причины проблемы с кодировкойCommon causes of encoding issues
Проблемы с кодировкой возникают, если кодировка VS Code в целом или вашего файла скрипта не совпадает с кодировкой, ожидаемой в PowerShell.Encoding problems occur when the encoding of VS Code or your script file does not match the expected encoding of PowerShell. В PowerShell нет способа автоматически определить кодировку файла.There is no way for PowerShell to automatically determine the file encoding.
Проблемы с кодировкой более вероятны при использовании символов не из 7-разрядной кодировки ASCII.You’re more likely to have encoding problems when you’re using characters not in the 7-bit ASCII character set. Пример:For example:
- Расширенные небуквенные символы, такие как длинное тире (), неразрывный пробел () или левая двойная кавычка ().Extended non-letter characters like em-dash (), non-breaking space () or left double quotation mark ()
- Латинские символы с диакритикой (, )Accented latin characters (, )
- Нелатинские символы, такие как кириллица (, )Non-latin characters like Cyrillic (, )
- Символы иероглифического письма (, , ).CJK characters (, , )
Распространенные причины проблем с кодировкой:Common reasons for encoding issues are:
- Параметры кодировок по умолчанию VS Code и PowerShell не были изменены.The encodings of VS Code and PowerShell have not been changed from their defaults. В версиях до PowerShell 5.1 (включительно) кодировка по умолчанию отличается от используемой в VS Code.For PowerShell 5.1 and below, the default encoding is different from VS Code’s.
- Открыт другой редактор, и файл перезаписан в новой кодировке.Another editor has opened and overwritten the file in a new encoding. Это часто происходит с интегрированной средой сценариев.This often happens with the ISE.
- Файл возвращается в систему управления версиями в кодировке, отличающейся от той, которая ожидается в VS Code или PowerShell.The file is checked into source control in an encoding that is different from what VS Code or PowerShell expects. Это может произойти, когда участники совместной работы используют редакторы с различными конфигурациями кодировок.This can happen when collaborators use editors with different encoding configurations.
Как определить наличие проблемы с кодировкойHow to tell when you have encoding issues
Часто ошибки кодирования в скриптах представляются как ошибки синтаксического анализа.Often encoding errors present themselves as parse errors in scripts. Если вы видите странные последовательности символов в скрипте, это может быть проблемой.If you find strange character sequences in your script, this can be the problem. В примере ниже тире () отображается в виде символов :In the example below, an en-dash () appears as the characters :
Эта проблема возникает, так как VS Code кодирует символ в UTF-8 как байты .This problem occurs because VS Code encodes the character in UTF-8 as the bytes . Если эти байты декодируются в кодировке Windows-1252, они интерпретируются как символы .When these bytes are decoded as Windows-1252, they are interpreted as the characters .
Некоторые странные последовательности символов, которые можно видеть:Some strange character sequences that you might see include:
- вместо . instead of
- вместо . instead of
- вместо . instead of
- вместо (неразрывный пробел); instead of (a non-breaking space)
- вместо . instead of
Этот удобный справочник перечисляет распространенные шаблоны, которые указывают на проблему между кодировками UTF-8 и Windows-1252.This handy reference lists the common patterns that indicate a UTF-8/Windows-1252 encoding problem.
Немного теории
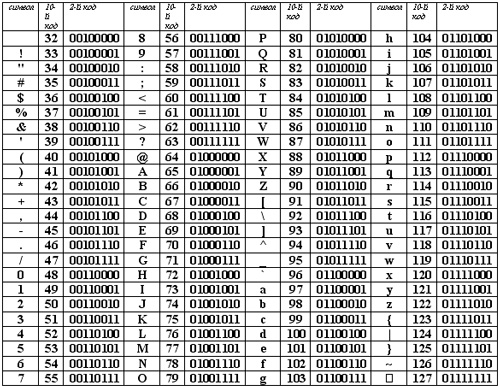
Любой документ на компьютере или в интернете, как я уже сказал, хранится в виде двоичного кода. К примеру, если вы используете кодировку ASCII, то буква «К» будет записана как 10001010, а windows 1251 под этим числом скрывается символ – Љ. В итоге, если браузер или программа обратится к другой таблице и считает вместо ASCII коды windows 1251, то читатель увидит совершенно непонятные ему символ.
Логичен вопрос, нафига было придумывать множество таблиц с кодами? Дело в том, что помимо русского алфавита существует еще и английский, немецкий, китайский. По некоторым подсчетам, существует около 200 000 символов. Хотя, я не очень доверяю этой статистике, вспоминая про японский.
Не забывайте, что для заглавной и строчной буквы нужно придумать свой код, есть запятые, тире и так далее.
Чем больше в таблице символов, тем длиннее код каждого из них, а значит и вес документа становится больше.
Представьте, если бы одна книга весила 4 Гб! Она бы очень долго загружалась, занимала все свободное место на компьютере. Решение о скачивании представлялось бы делом нелегким.
Если вспомнить о сайтах, то вообще страшно подумать, что бы произошло. Каждая страничка открывалась даже на скоростном оптоволокне по часу с лишним! Думаю, мобильные телефоны можно было бы смело выкидывать. Пользоваться ими на улице даже с 4G? Сомневаюсь.
По этим причинам каждый программист в свое время старался придумать свою таблицу символов. Чтобы было удобно для использования и вес сохранялся оптимальным.
Microsoft, к примеру, для русскоязычного сегмента создали windows-1251. В ней, конечно же, есть свои достоинства и недостатки. Как и у любого другого продукта.
Сейчас уже, лишь 2% всех страниц в интернете написано на 1251. Большинство веб-мастеров используют UTF-8. Почему так?
Проблемы консолей Visual Studio
В Visual Studio имеется возможность подключения консолей, по умолчанию подключены командная строка для разработчика и Windows PowerShell для разработчика. К достоинствам можно отнести возможности определения собственных параметров консоли, отдельных от общесистемных, а также запуск консоли непосредственно в директории разработки. В остальном — это обычные стандартные консоли Windows, включая, как показано ранее, установленную кодовую страницу по умолчанию.
Отдельной опцией Visual Studio является встроенная односеансная консоль отладки, которая перехватывает команду Visual Studio на запуск приложения, запускается сама, ожидает компиляцию приложения, запускает его и отдает ему управление. Таким образом, отладочная консоль в течение всего рабочего сеанса находится под управлением приложения и возможность использования команд Windows или самой консоли, включая команду CHCP, не предусмотрена. Более того, отладочная консоль не воспринимает кодовую страницу по умолчанию, определенную в реестре, и всегда запускается в кодировке 437 или 866.
Анализ проблем консолей был бы не полон без ответа на вопрос — можно ли запустить консольное приложение без консоли? Можно — любой файл «.exe» запустится двойным кликом, и даже откроется окно приложения. Однако консольное приложение, по крайней мере однопоточное, по двойному клику запустится, но консольный режим не поддержит — все консольные вводы-выводы будут проигнорированы, и приложение завершится
Недостатки и достоинства
UTF-8, в отличие от windows-1251 универсальная кодировка, в ней содержатся буквы различных алфавитов. Существует даже UTF-128, где есть вообще все языки – теулу, суахили, лаосский, мальтийский и так далее.

UTF-8 победнее, буквы занимают в разы меньше места и занимают всего один байт памяти, как и в 1251. В УТФ есть редкие символы из других языков или специальные символы. Они-то и весят по 5-6 байтов, но в документе используются крайне редко.
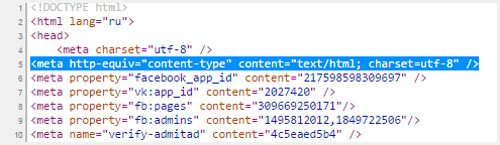
Когда вы создаете html документ для сайта, то указываете браузерам на какую таблицу им обращать внимание при расшифровке записей. Для этого необходимо вставить в тег head следующие данные
После символов «charset=» идет либо утф, либо виндовс, как в примере ниже
Для этого необходимо вставить в тег head следующие данные. После символов «charset=» идет либо утф, либо виндовс, как в примере ниже.
Если в дальнейшем вы захотите что-то поменять и вставить фразу на албанском, используя эту таблицу расшифровок, то ничего не получится, ведь этого языка кодировка не поддерживает. UTF‑8 без проблем позволит вам это сделать.
Если вас заинтересовало правильное создание сайта, то я могу порекомендовать вам курс Михаила Русакова « Создание и Раскрутка сайта от А до Я ».

Он содержит в себе очень много – 256 уроков, затрагивающих HTML, CSS, JavaScript, PHP, MySQL и XML. Помимо языков программирования вы сможете понять как монетизировать сайт, то есть скорее и больше получать прибыль. Один из немногих курсов, в котором было бы так подробно разъяснено все, что нужно.
Сам я вот уже год обучаюсь в школе блоггеров Александра Борисова . Это занимает в разы больше времени, конца и края пока не видно, но зато не менее исчерпывающе и дисциплинирует. Мотивирует продолжать разработку.
Ну а если возникают вопросы, не нужно искать по интернету. Всегда есть грамотный наставник.

Что-то я отошел от темы. Давайте вернемся к кодировкам.
Решения проблемы с кодировкой в cmd. 2 способ.
Теперь рассмотрим ещё одну ситуацию, когда могут возникнуть проблемы с кодировкой в CMD.
Допустим, ситуация требует сохранить результат выполнения той или иной команды в обычный «TXT» файл. В приделах этого поста возьмём для примера команду «HELP».
Задача : Сохранить справку CMD в файл «HelpCMD.txt. Для этого создайте Bat файл и запишите в него следующие строки.
После выполнения Bat файла в корне диска «C:» появится файл «HelpCMD.txt» и вместо справки получится вот что:
Естественно, такой вариант не кому не понравится и что бы сохранить справку в понятном для человека виде, допишите в Bat файл строку.
Теперь содержимое кода будет такое.
После выполнения «Батника» результат будет такой:
Вот так на много лучше, правда?
Пожалуй, на этом я закончу пост. Добавить больше нечего. Если у Вас имеются какие-то соображения по данной теме, буду рад Вашему комментарию к посту.
Дополнительно из комментариев то Garric
Автор очень хорошо описал принцип. ! Но это неудобно. Нужно бы добавить. Если автор добавит это в статью то это будет Good. Создаём файл .reg следующего содержания: —— Windows Registry Editor Version 5.00
«FileName»=»BATНастроенная кодировка.bat»
Выполняем.
Топаем в %SystemRoot%SHELLNEW
Создаём там файл «BATНастроенная кодировка.bat»
Открываем в Notepad
Вводим любой текст. (нужно!) Сохраняемся.
Удаляем текст. Меняем кодировку как сказано в статье. Сохраняемся.
———-
Щёлкаем правой кнопкой мыши по Рабочему столу. Нажимаем «Создать» — «Пакетный файл Windows».
Переименовываем. Открываем в Notepad . Пишем батник.
В дальнейшем при работе с файлом не нажимаем ничего кроме как просто «Сохранить». Никаких «Сохранить как».
Источник
Базы банных
Когда речь идет о php, все вообще страшно. Я уже рассказывал про базы данных, они используются для ускорения работы сайта. Обычно, вы к ним не обращаетесь, но когда появляется необходимость в переносе сайта становится не по себе.
Сложности случаются у всех, не важно какой у вас опыт работы, стаж и выслуга лет. Некоторые странички в базе могут содержать в себе все доступные символы для виндовс-1251, другие, к примеру, в шаблонах страниц, в другой кодировке
Пока не нужен перенос все работает и функционирует, хоть и не совсем правильно. Но после переезда начинаются неприятности. В идеале вы должны использовать либо только УТФ, либо виндовс-1251, но по факту всегда и у всех случаются вот такие недочеты.
Чтобы расшифровка согласовалась необходимо вписать код mysql_query(«SET NAMES cp1251»). В этом случае преобразование будет осуществлять по другому протоколу – cp1251.
Казахский вариант
Измененная версия Windows-1251 была стандартизирована в Казахстане как казахстанский стандарт STRK1048 и известна под этикеткой . Он отличается в строках, показанных ниже:
| _0 | _1 | _2 | _3 | _4 | _5 | _6 | _7 | _8 | _9 | _A | _B | _C | _D | _E | _F | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 8_ 128 | Ђ 0402 | Ѓ 0403 | ‚ 201A | ѓ 0453 | „ 201E | … 2026 г. | † 2020 г. | ‡ 2021 г. | € 20AC | ‰ 2030 г. | Љ 0409 | ‹ 2039 | Њ 040A | Қ 049A | Һ 04BA | Џ 040F |
| 9_ 144 | ђ 0452 | ‘ 2018 | ‘ 2019 | 201C | ” 201D | • 2022 г. | — 2013 г. | — 2014 г. | 2122 | љ 0459 | › 203A | њ 045A | қ 049B | һ 04BB | џ 045F | |
| A_ 160 | NBSP 00A0 | Ұ 04B0 | ұ 04B1 | Ә 04D8 | ¤ 00A4 | Ө 04E8 | ¦ 00A6 | § 00A7 | Ё 0401 | 00A9 | 0492 Ғ | 00AB | ¬ 00AC | SHY 00AD | 00AE | Ү 04AE |
| B_ 176 | ° 00B0 | ± 00B1 | І 0406 | і 0456 | ө 04E9 | µ 00B5 | ¶ 00B6 | · 00B7 | ё 0451 | № 2116 | 0493 ғ | 00BB | ә 04D9 | Ң 04A2 | ң 04A3 | ү 04AF |
Работа с кодировкой текста
Кодировка текста – эта набор электронных цифровых выражений, которые преобразуются в понятные для пользователя символы. Существует много видов кодировки, у каждого из которых имеются свои правила и язык. Умение программы распознавать конкретный язык и переводить его на понятные для обычного человека знаки (буквы, цифры, другие символы) определяет, сможет ли приложение работать с конкретным текстом или нет. Среди популярных текстовых кодировок следует выделить такие:
Последнее наименование является самым распространенным среди кодировок в мире, так как считается своего рода универсальным стандартом.
Чаще всего, программа сама распознаёт кодировку и автоматически переключается на неё, но в отдельных случаях пользователю нужно указать приложению её вид. Только тогда оно сможет корректно работать с кодированными символами.
Наибольшее количество проблем с расшифровкой кодировки у программы Excel встречается при попытке открытия файлов CSV или экспорте файлов txt. Часто, вместо обычных букв при открытии этих файлов через Эксель, мы можем наблюдать непонятные символы, так называемые «кракозябры». В этих случаях пользователю нужно совершить определенные манипуляции для того, чтобы программа начала корректно отображать данные. Существует несколько способов решения данной проблемы.
Способ 1: изменение кодировки с помощью Notepad++
К сожалению, полноценного инструмента, который позволял бы быстро изменять кодировку в любом типе текстов у Эксель нет. Поэтому приходится в этих целях использовать многошаговые решения или прибегать к помощи сторонних приложений. Одним из самых надежных способов является использование текстового редактора Notepad++.
Несмотря на то, что данный способ основан на использовании стороннего программного обеспечения, он является одним из самых простых вариантов для перекодировки содержимого файлов под Эксель.
Способ 2: применение Мастера текстов
Кроме того, совершить преобразование можно и с помощью встроенных инструментов программы, а именно Мастера текстов. Как ни странно, использование данного инструмента несколько сложнее, чем применение сторонней программы, описанной в предыдущем методе.
Переходим в директорию размещения импортируемого файла, выделяем его и кликаем по кнопке «Импорт».
Если данные отображаются все равно некорректно, то пытаемся экспериментировать с применением других кодировок, пока текст в поле для предпросмотра не станет читаемым. После того, как результат удовлетворит вас, жмите на кнопку «Далее».
Тут настройки следует выставить, учитывая характер обрабатываемого контента. После этого жмем на кнопку «Готово».
Способ 3: сохранение файла в определенной кодировке
Бывает и обратная ситуация, когда файл нужно не открыть с корректным отображением данных, а сохранить в установленной кодировке. В Экселе можно выполнить и эту задачу.
Документ сохранится на жестком диске или съемном носителе в той кодировке, которую вы определили сами. Но нужно учесть, что теперь всегда документы, сохраненные в Excel, будут сохраняться в данной кодировке. Для того, чтобы изменить это, придется опять заходить в окно «Параметры веб-документа» и менять настройки.
Существует и другой путь к изменению настроек кодировки сохраненного текста.
Теперь любой документ, сохраненный в Excel, будет иметь именно ту кодировку, которая была вами установлена.
Как видим, у Эксель нет инструмента, который позволил бы быстро и удобно конвертировать текст из одной кодировки в другую. Мастер текста имеет слишком громоздкий функционал и обладает множеством не нужных для подобной процедуры возможностей. Используя его, вам придется проходить несколько шагов, которые непосредственно на данный процесс не влияют, а служат для других целей. Даже конвертация через сторонний текстовый редактор Notepad++ в этом случае выглядит несколько проще. Сохранение файлов в заданной кодировке в приложении Excel тоже усложнено тем фактом, что каждый раз при желании сменить данный параметр, вам придется изменять глобальные настройки программы.
Источник
О программе
Здравствуйте! Эта страница может пригодиться, если вам прислали текст (предположительно на кириллице), который отображается в виде странной комбинации загадочных символов. Программа попытается угадать кодировку, а если не получится, покажет примеры всех комбинаций кодировок, чтобы вы могли выбрать подходящую.
Использование
- Скопируйте текст в большое текстовое поле дешифратора. Несколько первых слов будут проанализированы, поэтому желательно, чтобы в них содержалась (закодированная) кириллица.
- Программа попытается декодировать текст и выведет результат в нижнее поле.
- В случае удачной перекодировки вы увидите текст в кириллице, который можно при необходимости скопировать и сохранить.
- В случае неудачной перекодировки (текст не в кириллице, состоящий из тех же или других нечитаемых символов) можно выбрать из нового выпадающего списка вариант в кириллице (если их несколько, выбирайте самый длинный). Нажав OK вы получите корректный перекодированный текст.
- Если текст перекодирован лишь частично, попробуйте выбрать другие варианты кириллицы из выпадающего списка.
Ограничения
- Если текст состоит из вопросительных знаков («???? ?? ??????»), то проблема скорее всего на стороне отправителя и восстановить текст не получится. Попросите отправителя послать текст заново, желательно в формате простого текстового файла или в документе LibreOffice/OpenOffice/MSOffice.
-
Не любой текст может быть гарантированно декодирован, даже если есть вы уверены на 100%, что он написан в кириллице.
- Анализируемый и декодированный тексты ограничены размером в 100 Кб.
- Программа не всегда дает стопроцентную точность: при перекодировке из одной кодовой страницы в другую могут пропасть некоторые символы, такие как болгарские кавычки, реже отдельные буквы и т.п.
- Программа проверяет максимум 7245 вариантов из двух и трех перекодировок: если имело место многократное перекодирование вроде koi8(utf(cp1251(utf))), оно не будет распознано или проверено. Обычно возможные и отображаемые верные варианты находятся между 32 и 255.
- Если части текста закодированы в разных кодировках, программа сможет распознать только одну часть за раз.
Условия использования
Пожалуйста, обратите внимание на то, что данная бесплатная программа создана с надеждой, что она будет полезна, но без каких-либо явных или косвенных гарантий пригодности для любого практического использования. Вы можете пользоваться ей на свой страх и риск.. Если вы используете для перекодировки очень длинный текст, убедитесь, что имеется его резервная копия.
Если вы используете для перекодировки очень длинный текст, убедитесь, что имеется его резервная копия.
Переводчики
Русский (Russian) : chAlx ; Пётр Васильев (http://yonyonson.livejournal.com/)
Страница подготовки переводов на другие языки находится тут.
Что нового
October 2013 : I am trying different optimizations for the system which should make the decoder run faster and handle more text. If you notice any problem, please notify me ASAP.
На английской версии страницы доступен changelog программы.
Вернуться к кириллической виртуальной клавиатуре.
Неправильная кодировка результатов из базы данных MySQL
Если ваш сайт состоит из статической части (шаблон) и динамической, которая формируется из данных, получаемых из базы данных, то может возникнуть ситуация, когда часть сайта имеет правильную кодировку, а другая часть сайта имеет неправильную. В этом случае бесполезно менять настройки веб-сервера – поскольку всё равно часть страницы будет иметь неправильную кодировку.
Нужно начать с определения кодировки ваших таблиц. Можно посмотреть в phpMyAdmin:
Обратите внимание на столбец «Сравнение», запись «utf8_unicode_ci» означает, что используется кодировка UTF-8.
Можно подключиться к СУБД MySQL и проверить кодировку таблиц без phpMyAdmin. Для этого:
mysql -u root -p
Если вы забыли имя базы данных, то выполните команду:
SHOW DATABASES;
Предположим, я хочу посмотреть кодировку для таблиц в базе данных information_schema
USE information_schema;
Если вы забыли имя таблиц, выполните:
SHOW TABLES;
Далее выполните команду, в которой имя_таблицы замените на настоящее имя таблицы:
SHOW FULL COLUMNS FROM имя_таблицы;
Например:
SHOW FULL COLUMNS FROM GLOBAL_STATUS;
Вы увидите примерно следующее:
Смотрите столбец Collation. В моём случае там utf8_general_ci, это, как и utf8_unicode_ci, кодировка UTF-8. Кстати, если вы не знаете в чём разница между кодировками utf8_general_ci, utf8_unicode_ci, utf8mb4_general_ci, utf8mb4_unicode_ci, а также какую кодировку выбрать для базы данных MySQL, то посмотрите эту статью.
Теперь, когда мы узнали кодировку (в моём случае это UTF-8), то при каждом подключении к СУБД MySQL нужно выполнять последовательно запросы:
SET NAMES UTF8 SET CHARACTER SET UTF8 SET character_set_client = UTF8 SET character_set_connection = UTF8 SET character_set_results = UTF8
В PHP это можно сделать примерно так:
$this->mysqli = new mysqli($server, $username, $password, $basename);
if ($this->mysqli->connect_error) {
$this->errorHandler_c->logError(1, 'Connect Error (' . $this->mysqli->connect_errno . ') ' . $this->mysqli->connect_error, $_SERVER );
}
$this->mysqli->query("SET NAMES UTF8");
$this->mysqli->query("SET CHARACTER SET UTF8");
$this->mysqli->query("SET character_set_client = UTF8");
$this->mysqli->query("SET character_set_connection = UTF8");
$this->mysqli->query("SET character_set_results = UTF8");
Обратите внимание, что UTF8 вам нужно заменить на ту кодировку, которая используется для ваших таблиц.
Кодировки стандарта ASCII[править]
| Определение: |
| ASCII — таблицы кодировок, в которых содержатся основные символы (английский алфавит, цифры, знаки препинания, символы национальных алфавитов(свои для каждого региона), служебные символы) и длина кода каждого символа бит. |
бит:
ASCII7 — первая кодировка, пригодная для работы с текстом. Помимо маленьких букв английского алфавита и служебных символов, содержит большие буквы английского языка, цифры, знаки препинания и другие символы.
Кодировки стандарта ASCII ( бит):
- ASCII — первая кодировка, в которой стало возможно использовать символы национальных алфавитов.
- КОИ8-R — первая русская кодировка. Символы кириллицы расположены не в алфавитном порядке. Их разместили в верхнюю половину таблицы так, чтобы позиции кириллических символов соответствовали их фонетическим аналогам в английском алфавите. Это значит, что даже при потере старшего бита каждого символа, например, при проходе через устаревший семибитный модем, текст остается «читаемым».
- CP866 — русская кодировка, использовавшаяся на компьютерах IBM в системе DOS.
- Windows-1251 — русская кодировка, использовавшаяся в русскоязычных версиях операционной системы Windows в начале 90-х годов. Кириллические символы идут в алфавитном порядке. Содержит все символы, встречающиеся в типографике обычного текста (кроме знака ударения).
Структурные свойства таблицыправить
- Цифры 0-9 представляются своими двоичными значениями (например, ), перед которыми стоит . Таким образом, двоично-десятичные числа (BCD) превращаются в ASCII-строку с помощью простого добавления слева к каждому двоично-десятичному полубайту.
- Буквы A-Z верхнего и нижнего регистров различаются в своём представлении только одним битом, что упрощает преобразование регистра и проверку на диапазон. Буквы представляются своими порядковыми номерами в алфавите, записанными в двоичной системе счисления, перед которыми стоит (для букв верхнего регистра) или (для букв нижнего регистра).
| 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | A | B | C | D | E | F | ||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| NUL | SOH | STX | ETX | EOT | ENQ | ACK | BEL | BS | TAB | LF | VT | FF | CR | SO | SI | |
| 1 | DLE | DC1 | DC2 | DC3 | DC4 | NAK | SYN | ETB | CAN | EM | SUB | ESC | FS | GS | RS | US |
| 2 | ! | # | $ | % | & | ‘ | ( | ) | * | + | , | — | . | |||
| 3 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | ; | < | = | > | ? | ||
| 4 | @ | A | B | C | D | E | F | G | H | I | J | K | L | M | N | O |
| 5 | P | Q | R | S | T | U | V | W | X | Y | Z | \ | ^ | _ | ||
| 6 | ` | a | b | c | d | e | f | g | h | i | j | k | l | m | n | o |
| 7 | p | q | r | s | t | u | v | w | x | y | z | { | | | } | ~ | DEL |
Вариант Amiga
| MIME / IANA | Амига-1251 |
|---|---|
| Псевдоним (а) | Ami1251 |
| Язык (и) | Английский , русский |
| Классификация | расширенный ASCII |
| На основе | Окна-1251, ISO-8859-1 , ISO-8859-15 |
В российских системах Amiga OS использовалась версия кодовой страницы 1251, которая соответствует Windows-1251 для русского подмножества кириллических букв, но в остальном в основном соответствует ISO-8859-1 . Эта версия известна как Amiga-1251 , под этим именем она зарегистрирована в IANA .
| _0 | _1 | _2 | _3 | _4 | _5 | _6 | _7 | _8 | _9 | _A | _B | _C | _D | _E | _F | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0_ 0 | NUL 0000 | 0001 | 0002 | ETX 0003 | EOT 0004 | ENQ 0005 | ACK 0006 | BEL 0007 | 0008 | HT 0009 | LF 000A | ВТ 000Б | FF 000C | CR 000D | SO 000E | SI 000F |
| 1_ 16 | 0010 | 0011 | 0012 | 0013 | 0014 | NAK 0015 | SYN 0016 | ETB 0017 | CAN 0018 | 0019 | SUB 001A | 001B | FS 001C | GS 001D | RS 001E | США 001F |
| 2_ 32 | SP 0020 | ! 0021 | 0022 | # 0023 | 0024 долл. США | % 0025 | & 0026 | ‘ 0027 | ( 0028 | ) 0029 | * 002A | + 002B | , 002C | — 002D | . 002E | 002F |
| 3_ 48 | 0030 | 1 0031 | 2 0032 | 3 0033 | 4 0034 | 5 0035 | 6 0036 | 7 0037 | 8 0038 | 9 0039 | 003A | ; 003B | < 003C | = 003D | > 003E | ? 003F |
| 4_ 64 | @ 0040 | A 0041 | B 0042 | C 0043 | D 0044 | E 0045 | F 0046 | G 0047 | H 0048 | I 0049 | J 004A | K 004B | L 004C | M 004D | № 004E | O 004F |
| 5_ 80 | P 0050 | Q 0051 | R 0052 | S 0053 | Т 0054 | U 0055 | V 0056 | W 0057 | X 0058 | Y 0059 | Z 005A | 005B | \ 005C | 005D | ^ 005E | _ 005F |
| 6_ 96 | ` 0060 | а 0061 | b 0062 | c 0063 | d 0064 | e 0065 | f 0066 | г 0067 | h 0068 | я 0069 | j 006A | k 006B | l 006C | м 006D | № 006E | o 006F |
| 7_ 112 | p 0070 | q 0071 | r 0072 | с 0073 | t 0074 | u 0075 | v 0076 | w 0077 | х 0078 | y 0079 | z 007A | { 007B | | 007C | } 007D | ~ 007E | DEL 007F |
| 8_ 128 | 0080 | 0081 | 0082 | 0083 | 0084 | 0085 | 0086 | 0087 | 0088 | 0089 | 008A | 008B | 008C | 008D | 008E | 008F |
| 9_ 144 | 0090 | 0091 | 0092 | 0093 | CCH 0094 | 0095 | 0096 | 0097 | 0098 | 0099 | 009A | 009B | 009C | 009D | 009E | 009F |
| A_ 160 | NBSP 00A0 | ¡ 00A1 | ¢ 00A2 | £ 00A3 | € 20AC | ¥ 00A5 | ¦ 00A6 | § 00A7 | Ё 0401 | 00A9 | № 2116 | 00AB | ¬ 00AC | SHY 00AD | 00AE | ¯ 00AF |
| B_ 176 | ° 00B0 | ± 00B1 | ² 00B2 | ³ 00B3 | ´ 00B4 | µ 00B5 | ¶ 00B6 | · 00B7 | ё 0451 | ¹ 00B9 | º 00BA | 00BB | ¼ 00BC | ½ 00BD | ¾ 00BE | ¿ 00BF |
| C_ 192 | А 0410 | Б 0411 | В 0412 | Г 0413 | Д 0414 | Е 0415 | Ж 0416 | З 0417 | И 0418 | № 0419 | К 041A | Л 041B | М 041C | Н 041D | О 041E | П 041F |
| D_ 208 | Р 0420 | С 0421 | Т 0422 | У 0423 | Ф 0424 | Х 0425 | Ц 0426 | Ч 0427 | Ш 0428 | Щ 0429 | Ъ 042A | Ы 042B | Ь 042C | Э 042D | Ю 042E | Я 042F |
| E_ 224 | а 0430 | б 0431 | в 0432 | г 0433 | д 0434 | е 0435 | ж 0436 | з 0437 | и 0438 | 0439 | к 043A | л 043B | м 043C | н 043D | о 043E | п 043F |
| F_ 240 | р 0440 | с 0441 | т 0442 | у 0443 | ф 0444 | х 0445 | ц 0446 | ч 0447 | ш 0448 | щ 0449 | ъ 044A | ы 044B | ь 044C | э 044D | ю 044E | я 044F |
Отличается от Windows-1251 для соответствия ISO-8859-1
Отличается как от Windows-1251, так и от ISO-8859-1