Se
Содержание:
Как пользоваться парсером Wordstat от Click.ru
В числе инструментов Click.ru как раз есть функциональный и недорогой парсер Wordstat. Он быстро выдает частотность даже по большому списку запросов. При этом учитывает типы соответствия и региональность. Еще не требует капчу и прокси-серверы, а отчеты позволяет выгружать в Excel и хранить в «облаке».
Для начала работы зарегистрируйтесь в системе Click.ru. После входа в свой аккаунт на главной странице выберите раздел «Парсер частоты Wordstat» и приступайте к работе.
Для начала парсинга перейдите в соответствующий раздел
Как работать с парсером Wordstat после регистрации в Click.ru:
Загрузите список запросов.
Есть два способа: скопировать и вставить ключи в специальное поле или же загрузить XLSX-файл с ними.
При копировании списка учитывайте, что каждый ключ должен идти с новой строки. А в эксель-файле смотрите, чтобы не было вспомогательной информации (названий столбцов, лишних цифр и т. д.). Система берет запросы из первого листа .XLSX по принципу «одна ячейка – один ключ».
Этап загрузки запросов
Выберите регионы.
В системе доступны все регионы Яндекса. Можно посчитать общую частотность по нескольким регионам или получить статистику отдельно по каждому.
Разделять регионы в отчете нужно, если вы планируете продвигать бизнес отдельными региональными поддоменами и посадочными страницами, привязанными к географии. В остальных случаях галочка не ставится.
Выбираем регионы
Укажите тип соответствия.
Широкое соответствие – когда фразы пробиваются как есть – часто показывает обманчивую частотность. Все из-за того, что учитываются все вложенные ключи, в том числе нерелевантные (как в примере с игрушками). То есть всегда лучше перепроверять частоту запроса с помощью специальных операторов.
Кавычки позволяют уточнять статистику по конкретной фразе, без учета вложенных ключей.
Пример
| скачать видео бесплатно – 1 111 285 показов | “скачать видео бесплатно” – 8 493 показа |
Кавычки с восклицательными знаками показывают частотность по заданным словоформам.
Пример
| “!купить !телефон” – 37 909 показов | “!купить !телефоны” – 2 798 показов |
Квадратные скобки – фиксируют порядок слов, что особенно важно в туристическом бизнесе
Пример
| – 4 213 показов | – 1 814 показов |
Все варианты типов соответствия
Запустите проверку.
Время сбора частотностей зависит от количества запросов, регионов и типов соответствия. Если запросов меньше 1 000, процесс займет 1–2 минуты.
Результат будет доступен в списке задач. Можно открыть отчет в браузере или скачать его в формате XLSX.
Здесь будут появляться отчеты со статистикой
Yandex Wordstat Assistant
Yandex Wordstat Assistant – это расширение для браузера, которое при установке будет появляться только если вы будете находится на по адресу Вордстат Яндекса (wordstat.yandex.ru). Данный плагин дает нам возможность ускорить парсинг ключевых слов к себе в таблицу или текстовый файл.
Напротив каждого ключевого слова появится плюсик, и вы можете нажимая на «плюс» добавлять все интересующие ключевые слова в данное расширение, которое появится слева после установки его из магазина расширений.
Далее вы просто нажимаете на кнопку копировать все запросы, они копируются в буфер обмена вашей операционной системы, и далее вы их можете вставить в текстовый документ.
Таким образом, вам не нужно будет каждое ключевое слова выделять вручную и копировать в текстовый документ. Вы просто выделяете все необходимые ключевые слова, одним нажатием нажимаете «копировать» и вставляете в текстовый документ.
Очень удобно и экономит время на данный рутинный, но крайне необходимый и важны процесс.
Далее вбиваете название расширения — Yandex Wordstat Assistant и устанавливаете его.
После установки и активации расширения, оно сразу появится на страницу https://wordstat.yandex.ru слева, и вы сможете им начать пользоваться.
В плагине вы сможете интуитивно довольно быстро разобраться, поскольку он простой в использовании.
В плагине имеется всего 5 кнопок, и давайте каждую из них более подробно разберём:
- Добавить фразы – дает возможность добавить ключевые слова вручную в плагин. Данной опцией я сам не пользуюсь, поскольку не вижу в ней практического применения.
- Копировать список в буфер обмена – все фразы что были добавлены в плагин, за счет данной кнопки можно скопировать в буфер обмена операционной системы, и вставить в текстовый документ. Копирование происходит только ключевых фраз, без частотностей.
- Копировать список с частотностью в буфер обмена – тоже самое что и предыдущая кнопка, только с копированием частотности к каждой ключевой фразе, которые вы добавили в плагин.
- Сортировка – позволяет отсортировать фразы по частотности, алфавиту, порядку добавления и т. д.
- Очистить список – очищает поле плагина от всех добавленных запросов.
Как я писал выше, у списка ключевых фраз при установленном плагине, появляется плюсик слева от каждого запроса, а также появляется ссылка над всеми запросами «Добавить всё».
Если вам необходимо добавить все слова в плагин, то нажимайте данную ссылку, и все ключевые фразы добавятся в плагин. Оттуда вы их может одним нажатием кнопки скопировать в буфер обмена, и вставить в свой текстовый документ или exel.
Yandex Wordstat Assistant
Расширение устанавливается в 3 простых шага:
1) Скачайте актуальную версию расширения для браузера, в котором работаете с Яндекс Wordstat: Google Chrome, Mozilla Firefox, Opera или Яндекс Браузер.
Для всех браузеров алгоритм одинаковый. Мы покажем, как устанавливать и пользоваться возможностями Wordstat Assistant, на примере Google Chrome.
2) Нажмите кнопку для установки:
3) Подтвердите, что собираетесь установить расширение:
На этом всё готово, остается проверить, установилось ли расширение.
Если всё корректно, вы увидите:
Значок с таким уведомлением – теперь он всегда будет отображаться в вашем браузере.
Если такого значка нет, попробуйте перезапустить браузер.
Панель управления Wordstat Assistant в левой области страницы Яндекс Wordstat – в неё будут попадать все ключевые фразы, которые вы добавите.
На случай, если панель не появится, обновите страницу или также перезапустите браузер.
Знак «+» напротив каждого результата и в левой, и в правой колонке – нужен, чтобы добавлять фразы в список.
Чтобы его увидеть, введите нужную фразу, как обычно в Вордстате, например:
Рассмотрим все функции по порядку.
1) Добавление и удаление фраз из списка
Можно добавить в список отдельную ключевую фразу, нажав на плюс, или все фразы из таблицы (именно с той страницы, на которой вы находитесь, а не из всей выдачи), нажав ссылку «Добавить все»:
Например, мы хотим добавить все похожие фразы из левой колонки с первой страницы. Жмем «Добавить все», в окне подтверждения – «Добавить»:
Выглядит это так, в скобках указана частотность для каждого запроса:
Над списком отображается общее количество фраз, которые вы добавили, и суммарная частотность по ним:
В результатах поиска Yandex Wordstat фразы, которые вы выбрали, становятся серого цвета, со знаком минус вместо плюса.
Эти опции при необходимости можно отключить здесь:
По знаку «–» фразу можно в любой момент удалить из результатов поиска Яндекс Wordstat (1). Либо можно удалить прямо её из панели управления: для этого наведите на фразу курсор и кликните по минусу рядом с ней (2). Чтобы очистить весь список, нажмите крестик вверху панели управления (3).
При попытке добавить такой же ключ, какой уже есть в списке, Wordstat Assistant выдает сообщение:
2) Добавление собственных ключей
Для этого нажмите плюс на панели управления, введите запрос или список запросов, как на скриншоте:
Для добавленных вручную фраз вместо частотности показывается знак вопроса:
Если ваша фраза совпадает с фразой из результатов поиска Wordstat, последняя выделяется серым цветом. Но частотность при этом остается неизвестной (?), а не перетягивается из данных Wordstat.
3) Сортировка списка ключевых фраз
Её можно выполнять с помощью этой кнопки:
Она меняет свой вид в зависимости от того, по какому признаку вы сортируете фразы:
По возрастанию и убыванию частотности:
По алфавиту:
По порядку добавления (вновь добавленные в конец / в начало списка):
4) Копирование данных из Вордстата
Можно скопировать просто список фраз (1), либо список фраз вместе с фразами значения частотности (2), чтобы работать с ними дальше в любом формате – например, txt или Excel:
Чтобы автоматически удалить знак «+» из всех фраз, задайте эту настройку:
Если вы закроете вкладку с Wordstat или браузер, ничего не потеряется. Список сохранится под тем аккаунтом, в котором вы его сформировали.
Сбор частот
Сбор частот позволяет оценить популярность запросов.
Сервис выдает кол-во показов запроса за последние 30 дней.
Статистика обновляется не ежедневно, поэтому не воспринимайте этот период буквально.
Сервис поддерживает различные операторы поиска, поэтому программа способна получать несколько видов частот.
Программа автоматически добавляет нужные операторы при сборе того или иного вида частот (добавлять операторы вручную к текст запросов не требуется).
Базовая частота
Базовая частота соответствует широкому типу вхождения слов. Для выполнения запроса достаточно отправить сам запрос в исходном виде:
- свежий хлеб
- условная вероятность
- теорема Байеса
В результатах могут быть учтены и другие фразы, косвенно относящиеся к запросу «свежий хлеб» в широком соответствии: купить свежий хлеб, свежий ржаной хлеб, рецепт хлеба, свежая выпечка и др.
Фразовая частота
Фразовая частота фиксирует состав слов в искомом запросе, и показы считаются для словосочетания целиком. Для выполнения запроса необходимо добавить двойные кавычки:
- «свежий хлеб»
- «теорема Байеса»
- «плотность распределения»
В результатах к запросу «свежий хлеб» будут учтены только фразы с тем же набором слов:: свежий хлеб, хлеба свежего и др.
Точная фразовая частота
Точная фразовая частота фиксирует не только состав, но и словоформы слов в искомом запросе. Для выполнения запроса необходимо добавить оператор ! перед каждым словом в запросе и взять его в двойные кавычки:
- «!свежий !хлеб»
- «!теорема !Байеса»
- «!плотность !распределения»
В результатах к запросу «!свежий хлеб!» будут учтены только фразы с тем же набором слов в той же словоформе: свежий хлеб, хлеб свежий (порядок не фиксируется).
Точная фразовая частота с порядком
Точная фразовая с порядком частота фиксирует состав, словоформы и порядок следования слов в искомом запросе. Для выполнения запроса необходимо добавить оператор ! перед каждым словом в запросе, взять его в и двойные кавычки:
- «!свежий !хлеб»
- «!теорема !Байеса»
- «!плотность !распределения»
В результатах к запросу «!свежий хлеб!» будут учтены только фразы с тем же набором слов в той же словоформе и том же порядке следования: свежий хлеб.
Частота по маске
Вы можете самостоятельно определить маску запроса, используя поддерживаемые сервисом операторы.
Маска запроса должна содержать фрагмент QUERY, который при сборе частот будет заменяться на текст исследуемого запроса.
Анализ ключевых слов конкурентов
1. Serpstat
Serpstat — cервис позволяет получить информацию о ключевых словах конкурентов в SEO и контекстной рекламе. Умеет работать с разными регионами мира и поисковыми системами.
Тарифы стартуют от 69$ до 499$.
Есть trial.
2. SpyWords
SpyWords — полезный сервис позволяющий узнать ключевые слова конкурентов, осуществить подбор ключевых слов для сайта, сравнить видимость и другие параметры на уровне доменов.
Возможности сервиса:
- Анализ конкурентов
- Сравнение доменов
- Продвинутое сравнение
- Рейтинг доменов
- Умный подбор запросов
- Сравнение позиций
Тарифы от 1 978 руб. до 4 950 руб.
3. Keys.so
Keys.so — дает возможность анализа сайта по видимости в поисковых системах, в сетях контекстной рекламы. Оценивает стоимость трафика и ключевых слов.
Стоимость от 1 500 руб./мес. до 14 500 руб./мес. в зависимости от выбранного тарифа (есть скидки при оплате сразу за год).
При подписке на “Базовый” или “Корпоративный тариф” открывается возможность использовать функционал “СемЯдро”.
“СемЯдро” — модуль, позволяющий быстро и удобно создать семантическое ядро для сайта или рекламной кампании с помощью древовидных структур и автоматической кластеризации.
4. SimilarWeb
SimilarWeb — всемирный сервис для анализа сайтов, в платной версии позволяет узнать ключевые фразы, источники трафика и так далее.
Есть свободный тариф и тариф для компаний — от 199$.
5. Ahrefs
Ahrefs — глобальный сервис для анализа сайтов, не так давно начал работать с ключевыми фразами. Позволяет оценить ключевые фразы конкурентов, наиболее популярный контент и много других параметров.
Недавно появилась обновленная версия Ahrefs Site Explorer с усовершенствованным функционалом для работы с ключевыми словами.
Стоимость тарифных планов: от 82$ до 832$ в месяц (+возможность получить скидку при оплате за год).
6. Semrush
Semrush — сервис отлично работает с западным сегментом, позволяет проанализировать ключевые слова, оценить конкурентов, увидеть распределение трафика по страницам и т.д. С русскоязычным сегментом работает хуже.
Стоимость подписки стартует от 119$ и до 449$ в месяц.
7. SpyFu
SpyFu — анализ конкурентов в разрезе платного и бесплатного трафика. Отличный удобный интерфейс. Один из лидеров западного рынка по работе с ключевыми словами.
Подписка стоит от 33$ до 299$ в месяц.
|
Название |
Описание |
Тарифы |
Trial |
|
Serpstat |
Cервис позволяет получить информацию о ключевых словах конкурентов в SEO и контекстной рекламе |
от 69$ до 499$ |
Есть |
|
SpyWords |
Сервис позволяющий узнать ключевые слова конкурентов, осуществить подбор ключевых слов для сайта, сравнить видимость и другие параметры на уровне доменов |
от 1 978 руб. до 4 950 руб. |
Нет |
|
Keys.so |
Сервис дает возможность анализа сайта по видимости в поисковых системах, в сетях контекстной рекламы. Оценивает стоимость трафика и ключевых слов |
от 1 500 руб./мес. до 14 500 руб./мес. |
Нет |
|
SimilarWeb |
Сервис для анализа сайтов, в платной версии позволяет узнать ключевые фразы, источники трафика |
от 199$/мес. |
Есть |
|
Ahrefs |
Сервис для анализа сайтов, позволяет оценить ключевые фразы конкурентов, наиболее популярный контент и много других параметров |
от 82$ до 832$ в месяц |
Есть |
|
Semrush |
Сервис отлично работает с западным сегментом, позволяет проанализировать ключевые слова, оценить конкурентов, увидеть распределение трафика по страницам |
от 119$ и до 449$ в месяц |
Есть |
|
SpyFu |
Анализ конкурентов в разрезе платного и бесплатного трафика |
от 33$ до 299$ в месяц |
Нет |
Расширения для браузера Яндекс Wordstat
Использовать Яндекс Wordstat по старинке, то есть копипастить подходящие запросы – вчерашний день. Использование бесплатных расширений для браузера дает гораздо больше возможностей.
Рассмотрим основные из них на примере плагина Wordstat Assistant. После установки его панель управления находится в левой области страницы Яндекс Wordstat.
Итак, плагины Вордстата позволяют:
1) Формировать собственный список ключей, отбирая из выдачи Вордстата нужные в пару кликов.
Знаком «+» около каждого результата вы добавляете фразу в свой список. Кликом по кнопке «Добавить все» – все фразы со страницы выдачи, на которой сейчас вы находитесь:
Удалить фразы можно из результатов поиска Яндекс Wordstat (1) или прямо из панели управления (2). Либо крестиком вверху панели управления (3), если нужно очистить весь список:
2) Видеть автоматически рассчитанное количество фраз и частотность по списку благодаря встроенным счетчикам;
3) Добавлять собственные ключи:
Правда, частотность для них не подтягивается из данных Вордстата, а обозначается знаком вопроса.
4) Сортировать список ключей по частотности, алфавиту и порядку добавления.
5) Сохранять список в аккаунте Яндекса и редактировать при повторном открытии.
Более сложный плагин – WordStater. Он поддерживает все базовые функции, плюс свои уникальные вещи.
WordStater включает три вкладки:
1) Общий список из результатов Wordstat;
2) Список минус-слов;
3) Без минусов и дублей – список фраз, отфильтрованный от минус-слов.
В верхней строке плагина вы видите общее количество собранных фраз (1) и можете найти конкретную фразу в списке (2):
Теперь – об уникальных возможностях WordStater, связанных со сбором семантики.
1) Полуавтоматический сбор – с помощью специальных горячих клавиш:
- Ctrl+Shift+A – для добавления ключей с текущей страницы;
- Ctrl+Shift+(стрелка вправо) – со следующей, и т.д.
Так вы быстрее соберете много фраз, однако есть риск «схватить» за это капчу.
2) Исключение из выдачи Вордстата ранее минус-слов, заданных вручную или собранных из выдачи.
Активируйте минусацию, откройте вкладку «Сбор минус-слов»:
Или исключите слова прямо в выдаче Вордстата:
3) Генерация ключевых фраз в «Комбинаторе слов»:
Работает она по принципу перемножения:
Подробнее об этих и других возможностях расширений Яндекс Вордстат смотрите здесь.
Как работать с Вордстатом
Сервис подбора слов помогает просматривать обобщенную статистику по запросам, а также оценивать частотность в зависимости от различных факторов. В Wordstat также есть набор операторов, с помощью которых можно узнать реальное число запросов для определенной формы слова или фразы.
Фильтры
Чтобы посмотреть статистику в срезе по устройствам, используйте фильтр. Он доступен в каждом разделе. Wordstat разделяет мобильные устройства на телефоны и планшеты.
Для просмотра данных по разным регионам, нажмите «Все регионы». Откроется окно, где можно уточнить регион показов.
Переключитесь на вкладку «По регионам», чтобы узнать число показов страниц по запросам из конкретного города, страны или региона, а также по все регионам вместе. Здесь можно посмотреть статистику на карте, если удобно. Также можно применить фильтры по устройствам, чтобы сузить поиск.
Здесь доступны два столбца с цифрами:
- «показов в месяц» — количество показов из региона за месяц;
- «региональная популярность» — доля, которую занимает регион в показах по данному слову, деленная на долю всех показов результатов поиска в этом регионе.
100% — это среднее значение. Если оно меньше 100%, то интерес пользователей к этому слову понижен, и наоборот.
Яндекс уточняет, что региональная популярность — это affinity index в отчетах Яндекс.Метрики.
Следующий раздел в интерфейсе — «История запросов». В первую очередь он помогает подобрать слова для бизнесов, где ярко выражена сезонность и не получается собрать семантику на основе статистики за месяц. В «Истории запросов» показывается динамика показов за два года.
Статистику можно смотреть в абсолютных или относительных значениях. Для получения относительного значения абсолютная цифра нормируется на количество показов результатов поиска Яндекса за соответствующий месяц.
Операторы
Операторы в Wordstat помогают уточнить запросы и получить более детальную статистику по ним. Их можно применить только во вкладках «По словам» и «По регионам». Рассмотрим основные операторы, которые пригодятся специалисту на начальном этапе работе.
-
Кавычки фиксируют количество слов в запросе. Это помогает посмотреть, сколько раз пользователи вводили эту фразу. Система учитывает разный порядок слов и разные окончания. Повторяющиеся слова считаются за одно слово.
- Восклицательный знак нужен, чтобы посмотреть статистику по конкретной форме слова. Он ставится перед словом, которое не должно видоизменяться.
- С помощью оператора «Плюс» можно включать в запрос предлоги или другие служебные слова.
- «Минус» исключает слова из запроса.
- Если заключить ключевую фразу в квадратные скобки, система выдаст число запросов для фразы с сохранением порядка слов. При этом учитываются разные словоформы и предлоги.
Посмотрим на примеры использования. Если нужно узнать точное количество запросов исключительно по заданной фразе без дополнительных слов и без учета словоформ, нужно использовать два оператора: кавычки и восклицательный знак.
Чтобы исключить запросы, не совпадающие с тематикой продвижения, используйте оператор минус вместе с восклицательным знаком. Как в известном примере, вы не будете показывать рекламу бильярдного кия пользователям, которые интересуются покупкой машины Kia и ошиблись в правописании.
Для чего нужен Яндекс.Вордстат
Яндекс.Вордстат — бесплатный сервис для получения статистики поисковых запросов в Яндексе. С помощью сервиса можно посмотреть, сколько раз пользователи искали определенный поисковой запрос на протяжении месяца. Но это далеко не всё.
Какие данные выдает Вордстат
1. Статистика по частотности:
- указанного запроса;
- запросов, которые содержат указанную фразу или слово.
2. Похожие запросы для расширения семантики.
3. Данные по частотности с разбивкой по регионам и городам.
4. Данные по показам с разбивкой по типу устройств (десктопы, смартфоны, планшеты).
5. Сезонные колебания спроса по выбранной фразе (динамика популярности фразы за прошедшие два года в разрезе месяца или недели с разбивкой по типу устройств).
Инструменты оптимизации
Оценка популярности поисковых систем определяется по их доле трафика. Статистика рейтингов на первые пять месяцев 2017 года:
Поисковые системы отличаются друг от друга. Поэтому для лучшего продвижения сайта желательно сосредоточиться на какой-то одной. При оценке качества сайта Яндекс статистика рассматривает более 150 различных факторов, постоянно меняя и совершенствуя механизм поиска.
Штрафные фильтры сильно затрудняют действия серым, оранжевым и черным оптимизаторам. Поисковая статистика Яндекса рекомендует использовать только белую оптимизацию для достижения успеха. Она начинается с технических параметров. Для улучшения необходимо сделать:
- код ответа сервера 200 для конкретной страницы;
- кроссбраузерность сайта (одинаковое отображение в различных браузерах);
- оптимизацию под операционные системы для мобильных устройств;
- минимальное время загрузки сайта (до 2 секунд);
- доступность редактирования метатегов страниц;
- надежный хостинг;
- отсутствие ссылок на несуществующие страницы.
Статистика Яндекса советует выстроить навигационную конфигурацию сайта для правильной работы поискового робота. Поэтому желательно:
- расположить страницы строго по разделам и категориям;
- создать карту сайта при наличии большого количества страниц;
- присвоить уникальный адрес каждой странице;
- использовать robots.txt для закрытия ненужных страниц;
- удалить дублирующую информацию.
Простого набора ключей недостаточно для продвижения сайта. Информация должна удобно подаваться заинтересованным клиентам, причем ее суть необходимо раскрыть на первой странице и понятным языком. У посетителей сайта не должно возникать вопросов типа: как правильно пользоваться видео. При больших размерах текста разбивка на отдельные страницы облегчит работу Яндекс поиску.
Статистика поисковых запросов Яндекс отмечает, что строка поиска «видит» около 65 знаков. Поэтому длинные заголовки теряют смысл.
Статистика ключевых слов на Яндексе рекомендует использовать их в заголовках. Однако следует помнить, что заголовок из набора ключевых слов неприемлем. Сниппет (фрагмент текста для поисковых систем) желательно делать не более 60 знаков, а description до 150–170 символов.
Статистика запросов Яндекс также использует региональные факторы. Поэтому при прочих равных условиях web-ресурс местного региона будет в приоритете. Следовательно, не обойтись без указания адреса организации и регистрации в Яндекс Справочнике.
Оптимизируя под Яндекс браузер изображения не надо заменять графикой текст, т. к. робот не может определять по ним содержание страницы. Одним из главных требований к сайту является его безопасность. При обнаружении на странице вирусов статистика Яндекса фиксирует понижение их рейтинга. Для СЕО-оптимизаторов разработаны следующие инструменты:
- Яндекс Вебмастер.
- Яндекс Метрика.
- Яндекс Директ.
- Вордстат Яндекс (Wordstat Yandex).
Советы и рекомендации по использованию программ для парсинга
Специалисты советуют сочетать ручной и автоматический выбор запросов для составления семантического ядра, особенно для новичков. Пользуясь штатным инструментом Яндекс Вордстат Ассистент, вы нарабатываете навыки интуитивного подбора поисковых фраз, которые приводят на сайт целевых клиентов с помощью средне- и низкочастотных ключей. Высокочастотные фразы не всегда работают, особенно в конкурентной нише.
Если у вас нет времени на ручной парсинг в Яндекс Вордстат, используйте специальные инструменты. В интернете можно найти различное программное обеспечение, но большинство русскоязычных специалистов по SEO-оптимизации делают парсинг выдачи Яндекса с помощью Key Collector.
Это десктопный продукт, позволяющий создавать и хранить в локальной памяти компьютера проекты для каждого сайта, загружать и сохранять файлы и делать парсинг ключевых слов в соответствии с региональными настройками. Программа требует привязки к аккаунту. Для работы с ключевыми поисковыми запросами в Кей Коллекторе имеются пиктограммы основных поисковых систем в Рунете (в нашем случае это Yandex-парсер, хотя можно выбрать Google, Bing и другие).

Среди других полезных сервисов для SEO такие:
- Serpstat – многофункциональная платформа для профессионалов, имеющая триальную версию с ограниченным функционалом, а также платную подписку от 19 до 299$ в месяц;
- Ahrefs – веб-сервис с множеством полезных опций, включая мониторинг ниши, анализ конкурентов и улучшение индексации сайта. Для сбора семантического ядра предусмотрен инструмент Keywords Explorer. Протестировать его можно от 7$ в неделю;
- Semrush — аналог Ahrefs по части функционала, более дорогой по тарифам (от 99$ и выше).
Специалисты утверждают, что Кей Коллектор – это самая удобная и функциональная программа, позволяющая значительно облегчить жизнь оптимизатора. У нее есть множество полезных опций для точной настройки параметров парсера Yandex (например, глубины поиска, избирательного поиска запросов по базовой частотности и т.п.).
Но у программы есть нюанс – она платная. Стоимость лицензии составляет 1800-1900 рублей по электронному и безналичному расчету соответственно.
Совет! Если по какой-то причине вы не хотите пользоваться этим продуктом, можете попробовать его бесплатный аналог «Словоёб». Подойдет и более простой вариант — Букварикс – бесплатный сервис для сбора ключевых слов и формирования семантического ядра.
Парсинг Яндекс Вордстат можно делать самостоятельно и с помощью специальных программ. Ручной сбор посредством инструмента Wordstat Assistant оправдывает себя в том случае, если ваша ниша имеет узкую направленность и мало конкурентов, а перечень поисковых запросов относительно невелик. При больших объемах работ рекомендуется пользоваться специальными программами для парсинга и аналитики.
Онлайн парсеры
Подобные сервисы появились относительно недавно. Их преимущество – не нужно скачивать и устанавливать локально программные комплексы. Это экономит время, но сказывается на точности выборки КС. Причина – онлайн-парсеры не работают напрямую с базами данных Wordstat, а периодически скачивают их. Недостаток – не все запросы попадают в информационное поле сервиса.
Букварикс онлайн версия
Первым онлайн-сервисом с расширенными возможностями для SEO-оптимизаторов стал «Букварикс». До недавнего времени его использование было полностью бесплатным. Но с вводом нового функционала появилась платная подписка. Ее преимущества – фильтрация по частотности, количеству символов и слов. Есть ограничения для незарегистрированных пользователей. Но эта процедура бесплатная, возможна авторизация через социальные сети.
Особенности работы с «Букварикс»:
- максимальное количество поисковых фраз – 300 для платной версии;
- возможность скачивания отчета в формате .csv;
- группировка словоформ;
- дополнительные инструменты – анализ доменов, нормализатор, дубликатор и комбинатор слов.
Сервис значительно уступает по возможностям аналогичным программам, но прост в использовании. Рекомендован для начинающих оптимизаторов.
Дополнительные возможности
На иллюстрации выше, цифрами отмечены: 1 — сам запрос, 2 — дата обновления статистики Яндекса по данным фразам, 3 — суммарное число показов по фразам которые соответствуют запросу, 4 — общее число показов по фразе.
Здесь очень важно не путать общее число показов из колонки 4 и число точных запросов по фразе, которое можно получить с использованием операторов «Кавычки», «Восклицательный знак» и «Квадратные скобки». К дополнительным возможностям WordStat отнесем изучение истории (сезонности) спроса в тематике, получение частоты в заданном регионе и анализ популярности фраз в мобильном поиске (планшеты, мобильные телефоны)
К дополнительным возможностям WordStat отнесем изучение истории (сезонности) спроса в тематике, получение частоты в заданном регионе и анализ популярности фраз в мобильном поиске (планшеты, мобильные телефоны).
Данные функции часто оказываются полезны при планировании рекламных кампаний.
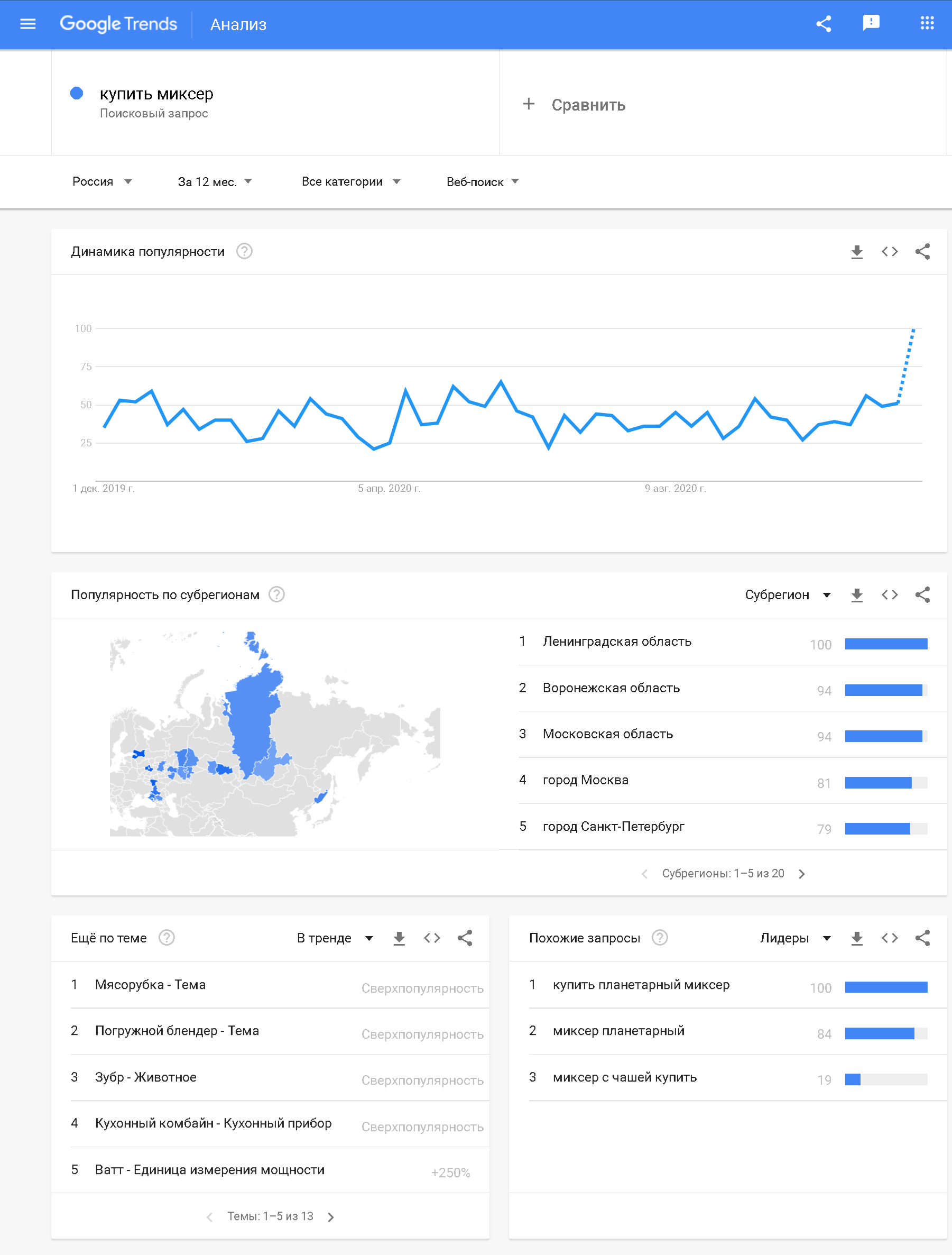
История запроса
Можно быстро понять, как меняется интерес к выходу новой модели «IPhone 6S». К сожалению, в текущий момент история запросов не поддерживает операторы («ИЛИ», «Группировка», «Квадратные скобки»).
Изучение динамики по запросу . Хорошо видны резкие сезонные всплески и провалы после наступления января.
Частота в заданном регионе
Отдельного упоминания заслуживает получение частоты запроса в заданном регионе. С помощью разделения общей частоты запроса по регионам можно оценить как частоту заданного запроса в интересующей нас регионе (Москва, Москва и область, Санкт-Петербург и т.д.), так и относительную популярность того или иного запроса в регионе.
Из примера приведенного ниже видно, что запросы со словами «купить» и «Казань» преимущественно задают жители г. Казань, что весьма очевидно. Использование данной функции на практике иногда открывает и более неожиданные закономерности.
Сбор (парсинг) запросов заданной длинны
На практике бывает полезным использовать приём парсинга запросов заданной длинны (из 2, 3, 4 слов и так далее) с вхождением ключевого слова. Данная возможность оказывается особенно актуальной, если вы работаете в популярной тематике и сбор первых 41 страниц не позволяет получить все поисковые фразы.
Для сбора всех фраз с длиной в 3 слова используется конструкция вида:
«IPhone IPhone IPhone»
Данный запрос позволяет собрать уже не просто 41 страницу поисковых фраз произвольной длины, а 41 страницу фраз из трёх слов с вхождением «IPhone». Последовательный анализ запросов с длиной от 2 до 7 слов позволяет существенно увеличить охват целевой аудитории.
Для ускорения сбора частот, быстрого парсинга Яндекс.Вордстат и хранения целевых ядер, рекомендуется использовать программы и онлайн-сервисы автоматизации, к числу которых можно отнести «Пиксель Тулс». После быстрой настройки параметров сбора, можно получить широкое семантического ядро в рамках тематики.
Анализ проведён с помощью инструментов в сервисе Пиксель Тулс.
Детальный анализ словоформ для ВЧ-запросов
Для ВЧ-запросов длиной в 2 и более слов может пригодиться анализ частоты встречаемости словоформ. Для этого требуется ввести исходную фразу, скажем, «продвижение сайтов» и далее последовательно исключать точные популярные написания с помощью комбинации операторов вида — -«», что приводит к исключению наиболее частотной формы написания из статистики и появлению второй по популярности версии. Далее процедуру можно повторить.
Кейс №4
Допустим, перед нами стоит задача быстро собрать теги для категории «Смартфоны» и у нас нет времени чистить огромное облако запросов данной категории от мусора. Чаще всего тегами являются 2 типа интентов – характеристика объекта (белый смартфон, мощный смартфон) и по назначению объекта (смартфон для пожилых, смартфон для девушки). С помощью Вордстата мы можем легко собрать теги 2-го типа – по назначению, так как все такие запросы содержат предлоги. Исходя из этого мы делаем следующую регулярку:
смартфоны (+до|+с|+на) -скачать -игры -интернет -мтс -фото
Так же указываем базовые стоп слова, чтобы не собирать мусор.
Сразу видны будущие теги – смартфоны на андроиде, с мощным аккумулятором, с хорошей камерой и т.д. Естественно у каждого могут быть индивидуальные проблемы и текущие кейсы не подойдут для решения вашей задачи, но включив логику, вы всегда можете видоизменить наши примеры под ваши нужды.
Все приведенные выше примеры работают в нашем парсере Wordstat – можете сами в этом убедиться. 🙂
Возможные настройки#
important
| Параметр | Значение по умолчанию | Описание |
|---|---|---|
| Region | All | Регион поиска |
| Remove + from keywords | ☐ | Удалять символ плюса (+) из найденных запросов |
| Use AntiGate | ☐ | Определяет использовать ли AntiGate для обхода каптч |
| AntiGate preset | default | Необходимо предварительно настроить парсер Util::AntiGate — указать свой ключ доступа и другие параметры, после чего выбрать созданный пресет здесь |
| First sleep | 50 | Задержка после первого запроса при использовании AntiGate для экономии каптч |
| Use session | Сохраняет хорошие сессии для дальнейшего использования | |
| Mobile only | ☐ | Получать статистику только для мобильного трафика |
Варианты вывода резульатов#
A-Parser поддерживает гибкое форматирование результатов благодаря встроенному шаблонизатору Template Toolkit, что позволяет ему выводить результаты в произвольной форме, а также в структуированной, например CSV или JSON
Вывод результата в JSON
Формат результата:
% data ={};
data.views=;
FOREACH i IN views;
item ={};
item.date= i.date;
item.relcount= i.relcount;
item.count= i.count;
data.views.push(item);
END;
result ={};
result = data;
result.json%
Скопировать
Пример результата:
{
«views»
{
«count»»9661734»,
«date»»2012-03-31»,
«relcount»»0.0019259985»
},
{
«count»»8567243»,
«date»»2012-04-30»,
«relcount»»0.0019512785»
},
{
«count»»9028986»,
«date»»2012-05-31»,
«relcount»»0.0021368683»
}
}
Скопировать
Вывод результата в CSV
Формат результата:
%FOREACH i IN views; tools.CSVline(query, i.count, i.date);END;%
Скопировать
Пример результата:
«тест»,9661734,2012-03-31
«тест»,8567243,2012-04-30
«тест»,9028986,2012-05-31
«тест»,6082099,2012-06-30
«тест»,5531950,2012-07-31
«тест»,5214663,2012-08-31
«тест»,6603865,2012-09-30
«тест»,9127457,2012-10-31
«тест»,9238652,2012-11-30
Скопировать
Дамп результата в SQL
Формат результата:
%FOREACH i IN views;»INSERT INTO views VALUES(‘» _ query _ «‘, ‘»; i.count _ «‘, ‘»; i.relcount _ «‘, ‘»; i.date _ «‘)\n»;END%
Скопировать
Пример результата:
INSERT INTO serp VALUES(‘тест’, ‘9661734’, ‘0.0019259985’, ‘2012-03-31’)
INSERT INTO serp VALUES(‘тест’, ‘8567243’, ‘0.0019512785’, ‘2012-04-30’)
INSERT INTO serp VALUES(‘тест’, ‘9028986’, ‘0.0021368683’, ‘2012-05-31’)
INSERT INTO serp VALUES(‘тест’, ‘6082099’, ‘0.0015732140’, ‘2012-06-30’)
INSERT INTO serp VALUES(‘тест’, ‘5531950’, ‘0.0013160071’, ‘2012-07-31’)
INSERT INTO serp VALUES(‘тест’, ‘5214663’, ‘0.0013327945’, ‘2012-08-31’)
INSERT INTO serp VALUES(‘тест’, ‘6603865’, ‘0.0015936909’, ‘2012-09-30’)
INSERT INTO serp VALUES(‘тест’, ‘9127457’, ‘0.0018740506’, ‘2012-10-31’)
INSERT INTO serp VALUES(‘тест’, ‘9238652’, ‘0.0018308715’, ‘2012-11-30’)
Скопировать