Screaming frog seo spider
Содержание:
9) Canonicals & Pagination Tabs & Filters
Canonicals and pagination were previously included under the directives tab. However, neither are directives and while they are useful to view in combination with each other, we felt they were deserving of their own tabs, with their own set of finely tuned filters, to help identify issues faster.
So, both have their own new tabs with updated and more granular filters. This also helps expose data that was only previously available within reports, directly into the interface. For example, the new now includes a ‘Non-Indexable Canonical’ filter which could only be seen previously by reviewing response codes, or viewing ‘Reports > Non-Indexable Canonicals’.

Pagination is something websites get wrong an awful lot, it’s nearly at hreflang levels. So, there’s now a bunch of useful ways to filter paginated pages under the to identify common issues, such as non-indexable paginated pages, loops, or sequence errors.

The more comprehensive filters should help make identifying and fixing common pagination errors much more efficient.
Small Update – Version 11.3 Released 30th May 2019
We have just released a small update to version 11.3 of the SEO Spider. This release is mainly bug fixes and small improvements –
- Added relative URL support for robots.txt redirects.
- Fix crash importing crawl file as a configuration file.
- Fix crash when clearing config in SERP mode
- Fix crash loading in configuration to perform JavaScript crawling on a platform that doesn’t support it.
- Fix crash creating images sitemap.
- Fix crash in right click remove in database mode.
- Fix crash in scheduling when editing tasks on Windows.
- Fix issue with Sitemap Hreflang data not being attached when uploading a sitemap in List mode.
- Fix configuration window too tall for small screens.
- Fix broken FDD HTML export.
- Fix unable to read sitemap with BOM when in Spider mode.
7) Updated SERP Snippet Emulator
Google increased the average length of SERP snippets significantly in November last year, where they jumped from around 156 characters to over 300. Based upon our research, the default max description length filters have been increased to 320 characters and 1,866 pixels on desktop within the SEO Spider.
The lower window has also been updated to reflect this change, so you can view how your page might appear in Google.

It’s worth remembering that this is for desktop. Mobile search snippets also increased, but from our research, are quite a bit smaller – approx. 1,535px for descriptions, which is generally below 230 characters. So, if a lot of your traffic and conversions are via mobile, you may wish to update your max description preferences under ‘Config > Spider > Preferences’. You can switch ‘device’ type within the SERP snippet emulator to view how these appear different to desktop.
As outlined previously, the SERP snippet emulator might still be occasionally a word out in either direction compared to what you see in the Google SERP due to exact pixel sizes and boundaries. Google also sometimes cut descriptions off much earlier (particularly for video), so please use just as an approximate guide.
Serpstat
Serpstat — многофункциональная платформа, которая дает возможность:
- seo-аудита сайта,
- поисковой аналитики,
- мониторинга позиций,
- исследования рынка,
- анализа ключевых фраз, платной выдачи, ссылок и конкурентов.
Помогает выявить и исправить такие seo-ошибки, как некорректные заголовки, неправильно настроенная карта сайта, ошибки в адресах страниц и др. Анализирует ссылочную массу сайта, определяет сайты-конкуренты, их позиции в поисковой выдаче и видимость, отслеживает динамические изменения различных показателей, например, объема трафика вашего сайта и конкурентов. Собирает самые эффективные ключевые слова из разных региональных баз и определяет их ценность. Осуществляет анализ рекламных компаний и контента сайтов-конкурентов, популярных запросов в той или иной бизнес-нише.
Особенности:
- есть расширения для браузеров Chrome, Mozilla, Opera,
- есть API и возможность интеграции с системами сбора информации вашего сайта,
- можно добавлять пользователей без дополнительной платы: открывать доступ к проекту или давать возможность отслеживать его показатели,
- для визуализации данных используется коннектор Serpstat и Google Data Studio, но он доступен только для пользователей с учетной записью Serpstat и лимитами для API,
- при долгосрочной подписке действуют скидки.
4) Configurable Accept-Language Header
Google introduced local-aware crawl configurations earlier this year for pages believed to adapt content served, based on the request’s language and perceived location.
This essentially means Googlebot can crawl from different IP addresses around the world and with an Accept-Language HTTP header in the request. Hence, like Googlebot, there are scenarios where you may wish to supply this header to crawl locale-adaptive content, with various language and region pairs. You can already use the proxy configuration to change your IP as well.
You can find the new ‘Accept-Language’ configuration under ‘Configuration > HTTP Header > Accept-Language’.
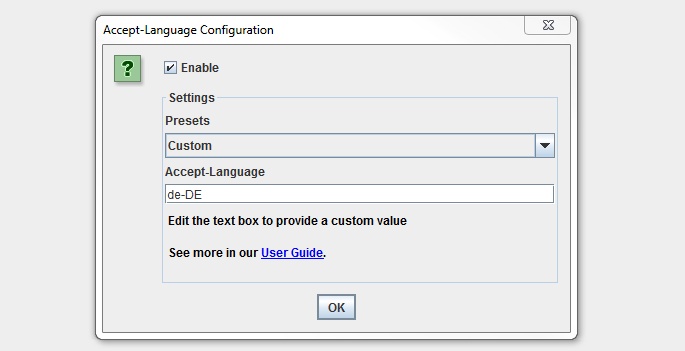
We have some common presets covered, but the combinations are huge, so there is a custom option available which you can just set to any value required.
1) Tree View
You can now switch from the usual ‘list view’ of a crawl, to a more traditional directory ‘tree view’ format, while still mantaining the granular detail of each URL crawled you see in the standard list view.
This additional view will hopefully help provide an alternative perspective when analysing a website’s architecture.
The SEO Spider doesn’t crawl this way natively, so switching to ‘tree view’ from ‘list view’ will take a little time to build, & you may see a progress bar on larger crawls for instance. This has been requested as a feature for quite sometime, so thanks to all for their feedback.
Подробная инструкция по использованию Screaming Frog SEO Spider
Правильный аудит сайта – это половина успешной оптимизации. Но для его проведения требуется ряд инструментов и их понимание.
Одним из наиболее полезных сервисов является Screaming Frog (SF), который дает возможность с помощью парсинга (сбора информации) получить необходимые данные, например, массово выгрузить пустые страницы или найти все дубликаты по метатегу Title.
В процессе оптимизации мы часто используем данный сервис, поэтому решили составить цикл обзорных статей, чтобы упростить специалистам навигацию по инструментарию и поиску решений нетривиальных задач. В этой статье-переводе расскажем о настройке парсинга и опишем, как без лишних проблем сканировать большие сайты.
Ознакомиться с сервисом более подробно можно в разделе первоисточника User Guide , на этом же сайте можно скачать бесплатную версию (предел парсинга – до 500 страниц, есть ограничение в настройках, поэтому рекомендуем использовать полную версию).
Robots.txt (настройки влияния robots.txt)
Здесь мы указываем парсеру, как именно учитывать файл robots.txt. Блок разделен на две вкладки – Settings и Custom.
Settings
Ignore robots.txt
По умолчанию SF будет подчиняться протоколу robots.txt: например, если сайт запрещен для сканирования в robots.txt, краулер не сможет его спарсить. Однако данная опция позволяет игнорировать этот протокол, таким образом разрешая попадание в отчет всех папок и файлов.
Respect robots.txt
При выборе опции мы можем получить отчет по внутренним и внешним ссылкам, закрытым от индексации в robots.txt. Для этого необходимо выбрать соответствующие чекбоксы: для отчета по внешним ссылкам – Show external URLs blocked by robots.txt, по внутренним – Show internal URLs blocked by robots.txt.
Custom

Пользовательский файл robots.txt использует выбранный User Agent в конфигурации, таким образом данная опция позволит просканировать или протестировать robots.txt без необходимости внесения правок для актуальных директив или использования панелей вебмастеров.
Сначала укажите в основной строке название, нажмите кнопку Add, в итоге вы получите robots.txt домена:

В правом нижнем углу есть кнопка Test. Если слева вписать нужный URL домена и нажать на нее, программа покажет доступность URL для индекса с учетом указанных в robots.txt настроек.
Возможности Screaming Frog SEO Spider
- Мощный сканер веб-сайтов, блогов и т.д;
- Отображение данных по мета тегам;
- Встроенный анализатор скриптов CSS;
- Расширяемость за счёт установки плагинов;
- Тонкая настройка парсинга для вебмастеров;
- Работа с библиотеками JavaScript Underscore;
- Удобная визуализация анализируемого контента;
- Поддерживает экспорт данных в форматы CSV, TXT, HTML, Word;
- Выгрузка содержимого нужных тегов по регулярному выражению;
- Интегрировано средство аудита входящего и исходящего трафика;
- Генерация отчётов о показателях ранжирования и индексации сайта;
- Позволяет учитывать cookies (аналогично поисковому роботу GoogleBot);
- Можно узнать тип, кодировку и уровень вложенности определённой веб-страницы;
- Помощь в выполнении перелинковки для увеличения позиций по продвигаемым запросам.
Преимущества
- Поддержка прокси;
- Поиск дублирующих тайтлов;
- Выставление лимита таймаутов;
- Невысокое потребление RAM и CPU;
- Защита аккаунта логином и паролем;
- Визуализация ссылочного текста;
- Полное соответствие стандартам языка разметки;
- Утилита более функциональна на фоне многих конкурентов;
- Выведение рекомендаций с директивами во всплывающем окне;
- Совместимость с операционными системами Виндовс, разрядностью x86, x64;
- Можно настроить столбцы с отображаемыми сведениями при помощи фильтров и опции сортировки;
- Дополнительные чекбоксы с типами валидации микроразметки (Schema.org, Google Validation, Case-Sensitive);
- Обнаруживает причину возникновения и помогает исключить критические ошибки (Error 404, «Нет ответа от сервера» и пр).
Недостатки
7) Compare Raw & Rendered HTML
You may wish to store and view HTML and rendered HTML within the SEO Spider when working with JavaScript. This can be set-up under ‘Configuration > Spider > Extraction’ and ticking the appropriate & options.
This then populates the lower window ‘view source’ pane, to enable you to compare the differences, and be confident that critical content or links are present within the DOM.

This is super useful for a variety of scenarios, such as debugging the differences between what is seen in a browser and in the SEO Spider, or just when analysing how JavaScript has been rendered, and whether certain elements are within the code.
2) Database Storage Crawl Auto Saving & Rapid Opening
Last year we introduced mode, which allows users to choose to save all data to disk in a database rather than just keep it in RAM, which enables the SEO Spider to crawl very large websites.
Based upon user feedback, we’ve improved the experience further. In database storage mode, you no longer need to save crawls (as an .seospider file), they will automatically be saved in the database and can be accessed and opened via the ‘File > Crawls…’ top-level menu.

The ‘Crawls’ menu displays an overview of stored crawls, allows you to open them, rename, organise into project folders, duplicate, export, or delete in bulk.

The main benefit of this switch is that re-opening the database files is significantly quicker than opening an .seospider crawl file in database storage mode. You won’t need to load in .seospider files anymore, which previously could take some time for very large crawls. Database opening is significantly quicker, often instant.
You also don’t need to save anymore, crawls will automatically be committed to the database. But it does mean you will need to delete crawls you don’t want to keep from time to time (this can be done in bulk).
You can export the database crawls to share with colleagues, or if you’d prefer export as an .seospider file for anyone using memory storage mode still. You can obviously also still open .seospider files in database storage mode as well, which will take time to convert to a database (in the same way as version 11) before they are compiled and available to re-open each time almost instantly.
Export and import options are available under the ‘File’ menu in database storage mode.

To avoid accidentally wiping crawls every time you ‘clear’ or start a new crawl from an existing crawl, or close the program – the crawl is stored. This leads us nicely onto the next enhancement.
8) Adjust The AJAX Timeout
Based upon the responses of your crawl, you can choose when the snapshot of the rendered page is taken by adjusting the ‘‘ which is set to 5 seconds, under ‘Configuration > Spider > Rendering’ in JavaScript rendering mode.

Previous internal testing indicated that Googlebot takes their snapshot of the rendered page at 5 seconds, which many in the industry concurred with when we discussed it more publicly in 2016.
In reality, this was via Google Search Console and real-life Googlebot is more flexible than the above, they adapt based upon how long a page takes to load content, considering network activity and things like caching play a part. However, Google obviously won’t wait forever, so content that you want to be crawled and indexed, needs to be available quickly, or it simply won’t be seen. We’ve seen cases of misfiring JS causing the render to load much later, and entire websites plummeting in rankings due to pages suddenly being indexed and scored with virtually no content.
It’s worth noting that a crawl by our software will often be more resource intensive than a regular Google crawl over time. This might mean that the site response times are typically slower, and the AJAX timeout requires adjustment.
You’ll know this might need to be adjusted if the site fails to crawl properly, ‘response times’ in the ‘Internal’ tab are longer than 5 seconds, or web pages don’t appear to have loaded and rendered correctly in the ‘rendered page’ tab.
Расширенное сканирование в режиме списка
Режим списка действительно эффективен при правильной настройке. Есть несколько интересных продвинутых способов применения, которые помогут вам сфокусировать анализ и сэкономить время и силы.
Сканирование списка URL-адресов и другого элемента
Режим списка может быть очень гибким и позволяет сканировать список загружаемых URL и другой элемент.
Например, если вы хотите просканировать список URL-адресов и их изображений. Или вам нужно было проверить список URL-адресов и их недавно реализованные канонические, AMP или hreflang, а не весь сайт. Или вы хотели собрать все внешние ссылки из списка URL-адресов для построения неработающих ссылок. Вы можете выполнить все это в режиме списка, и процесс практически такой же.
Перейдя в режим списка, удалите , которое автоматически устанавливается равным «0». Перейдите в «Конфигурация> Паук> Ограничения» и снимите флажок с конфигурации.
Это означает, что SEO Spider теперь будет сканировать ваш список URL-адресов – и все URL-адреса в том же субдомене, на который они ссылаются.
Поэтому вам необходимо контролировать, что именно сканируется, с помощью параметров детальной конфигурации. Перейдите в “Конфигурация> Паук> Сканирование”. Отключите все «Ссылки на ресурсы» и «Ссылки на страницы» в меню конфигурации для «Сканирование».
Затем выберите элементы, которые вы хотите сканировать, рядом со списком URL-адресов. Например, если вы хотите просканировать список URL-адресов и их изображений, настройка будет такой.
А если вы загрузите один URL, например страницу SEO Spider, вы увидите, что страница и ее изображения просканированы.
Эта расширенная настраиваемость позволяет проводить лазерный аудит именно тех элементов связи, которые вам нужны.
Аудит перенаправлений
Если вы проверяете перенаправления при миграции сайта, может быть особенно полезно сканировать их целевые URL-адреса и любые встречающиеся цепочки перенаправления. Это избавляет от необходимости загружать несколько списков целевых URL-адресов каждый раз, чтобы добраться до конца.
В этом случае мы рекомендуем использовать конфигурацию «всегда следовать перенаправлениям» в разделе «Конфигурация> Паук> Дополнительно». Включение этой конфигурации означает, что «предел глубины сканирования» игнорируется, и перенаправления будут выполняться до тех пор, пока они не достигнут ответа, отличного от 3XX (или вашего, пока не будет достигнут предел «» в разделе «Конфигурация> Паук> Ограничения»).
Если вы затем воспользуетесь отчетом «Все перенаправления», он отобразит полную цепочку перенаправлений в одном отчете.
Пожалуйста, прочтите наше руководство по аудиту перенаправлений при миграции сайта для получения более подробной информации об этом процессе.
Подключение к API
В режиме списка вы можете подключиться к API-интерфейсам , , и инструментов анализа обратных ссылок для получения данных. Например, вы можете подключиться к и получить такие данные, как ссылающиеся домены, ключевые слова, трафик и ценность, которые затем отображаются на вкладке «Показатели ссылок».
Это может быть очень полезно, например, при сборе данных для конкурентного анализа.
Extract
Now that the tool can crawl and render our chosen URLs, we need to tell it what data we actually want to pull out, (i.e: those glorious PageSpeed scores).
Open up the custom extraction panel, (Configuration > Custom > Extraction) and enter in the following Xpath variables depending on which metrics you want to pull.

Desktop Estimated Input Latency
If done correctly you should have a nice green tick next to each entry, a bit like this:

(Be sure to add custom labels to each one, set the type to Xpath and change the far right drop down from extract HTML to extract text.)
(There are also quite a lot of variables so you may want to split your crawl by mobile & desktop or take a selection of metrics you wish to report on.)
Hit OK.
5) Internal Link Score
A useful way to evaluate and improve internal linking is to calculate internal PageRank of URLs, to help get a clearer understanding about which pages might be seen as more authoritative by the search engines.
The SEO Spider already reports on a number of useful metrics to analyse internal linking, such as crawl depth, the number of inlinks and outlinks, the number of unique inlinks and outlinks, and the percentage of overall URLs that link to a particular URL. To aid this further, we have now introduced an advanced ‘link score’ metric, which calculates the relative value of a page based upon its internal links.

This uses a relative 0-100 point scale from least to most value for simplicity, which allows you to determine where internal linking might be improved.
The link score metric algorithm takes into consideration redirects, canonicals, nofollow and much more, which we will go into more detail in another post.
This is a relative mathematical calculation, which can only be performed at the end of a crawl when all URLs are known. Previously, every calculation within the SEO Spider has been performed at run-time during a crawl, which leads us on to the next feature.
Small Update – Version 15.1 Released 14th April 2021
We have just released a small update to version 15.1 of the SEO Spider. This release is mainly bug fixes and small improvements –
- Fix bug that allowed selection of a project directory in ‘Compare’ mode triggering a crash.
- Fix bug in crawls dialog with crawls not being ordered by modified date.
- Fix tool tip alignment issues in Compare mode.
- Fix bug in JavaScript rendering causing a stall when crawling PDFs.
- Fix bug where re-spidered URLs that previously failed rendering appeared in the External tab.
- Fix crash in Locales that use non ASCII numbering systems when crawling sites with multiple instances of HTML elements.
- Fix crash removing URLs from Tree View.
Small Update – Version 15.2 Released 18th May 2021
We have just released a small update to version 15.2 of the SEO Spider. This release is mainly bug fixes and small improvements –
- Include ‘Current Indexability Status’ (and previous) columns in ‘Change Detection > Indexability’.
- Added right-click ‘Respider’ to details panel.
- Add status and status code to right click ‘Export > Inlinks’.
- Improve usability of comparison mode crawls dialog.
- Improve usability of Crawl Comparison URL Mapping UI.
- Remove new lines from Link Paths.
- Fix various issues with Forms based authentication.
- Fix bug where cells containing lots of data would cause Google Sheets exports to fail.
- Fix bug reading sitemaps containing a DOCTYPE.
- Fix bug where not all image types were shown in the Image Preview tab.
- Fix crash performing a search in the master view after changing a Custom Search or Extraction.
- Fix bug where doing a respider on loaded in completed crawl with GSC/GA looses columns in master view when saved.
- Fix bug with change detection metrics missing when upgrading crawl to 15.2.
- Fix bug with Server Response Times columns showing incorrect data if ‘server response times category’ is also configured.
- Fix bug with persistent spell check dictionary being cleared on startup.
- Fix bug with Word Cloud Visualisation HTML export not working.
- Fix bug with trailing slashes being stripped from file names in screenshots bulk export.
- Fix bug with class name shown in Gnome menu on Ubuntu 18.04.
- Fix bug with SERP description clipping behind table.
- Fix crash in Image Details preview pane.
- Fix bug with PSI exports showing headings as Secs, but data as MS.
- Fix Duplicate ‘Max Image Size’ label in Spider Preferences.
- Fix crash with using an invalid regex in Regex Replace UI.
Small Update – Version 12.5 Released 28th January 2020
We have just released a small update to version 12.5 of the SEO Spider. This release is mainly bug fixes and small improvements –
- Update Googlebot User Agent strings to include latest Chrome version.
- Report 200 ‘OK’ URLs that are redirected by PSI in the PSI Error Column.
- Update Structured Data validation to account for Google Receipe changes.
- Fix bug in PSI causing it to request too fast when faced with slow responeses from the API.
- Fix broken visualisations export when it contains diacritical characters.
- Fix issue loading in a crawl with PSI data in database mode.
- Fix issue with column ordering is not persisted.
- Fix crash due to corrupt configuration file.
- Fix crash when running out of disk space in a database crawl.
- Fix crash pasting in robots.txt files.
- Fix crash switching mode when no tabs are selected.
- Fix crash in speed configuration UI.
- Fix crash when sorting/searching tables.
- Fix crash in PSI when server response is slow.
- Fix crash removing/re-spidering URLs.
Include/Exclude (включение и исключение папок при парсинге)
Во вкладке Include мы вписываем выражения для парсинга только указанных папок, во вкладке Exclude – исключения, для парсинга всех, кроме указанных.
Разберем логику на примере вкладки Exclude:
Чтобы проверить выражение, можно использовать вкладку Test. Например, нужно запретить парсинг домена.
Если правило указано верно, то в Test при вводе нужного URL будет следующее:
Примеры других выражений:
Чтобы исключить конкретный URL или страницу: http://www.example.com/do-not-crawl-this-page.html
Чтобы исключить подкаталог или папку: http://www.example.com/do-not-crawl-this-folder/.*
Чтобы исключить все после бренда, где иногда могут быть другие папки: http://www.example.com/.*/brand.*
Если нужно исключить URL с определенным параметром, таким как price, содержащимся во множестве различных каталогов, можно использовать следующее выражение: .*\?price.*
Small Update – Version 3.1 Released 24th February 2015
We have just released another small update to version 3.1 of the Screaming Frog SEO Spider. There’s a couple of tweaks and some bug fixes from the update, which include –
- The insecure content report has been improved to also include canonicals. So if you have a secure HTTPS URL, with an insecure HTTP canonical, these will be identified within the ‘insecure content’ report now, as well.
- Increased the size of the URL input field by 100px in Spider mode.
- Fixed a bug with ‘Respect Canonicals’ option, not respecting HTTP Header Canonicals.
- Fixed a bug with ‘Crawl Canonicals’ not crawling HTTP Header Canonicals.
- Fixed a crash on Windows, when users try to use the ‘Windows look and feel’, but have an older version of Java, without JavaFX.
- Fixed a bug where we were not respecting ‘nofollow’ directives in the X-Robots-Tag Header, as reported by Merlinox.
- Fixed a bug with the Sitemaps file writing ‘priorities’ attribute with a comma, rather than a full stop, due to user locale.
- Updated the progress percentage & average response time to format according to default locale.
- Fixed a crash caused by parsing pages with an embed tag containing an invalid src attribute, eg embed src=”about:blank”.
2) View & Audit URLs Blocked By Robots.txt
You can now view URLs disallowed by the robots.txt protocol during a crawl.
Disallowed URLs will appear with a ‘status’ as ‘Blocked by Robots.txt’ and there’s a new ‘Blocked by Robots.txt’ filter under the ‘Response Codes’ tab, where these can be viewed efficiently.

The ‘Blocked by Robots.txt’ filter also displays a ‘Matched Robots.txt Line’ column, which provides the line number and disallow path of the robots.txt entry that’s excluding each URL. This should make auditing robots.txt files simple!
Historically the SEO Spider hasn’t shown URLs that are disallowed by robots.txt in the interface (they were only available via the logs). I always felt that it wasn’t required as users should know already what URLs are being blocked, and whether robots.txt should be ignored in the configuration.
However, there are plenty of scenarios where using robots.txt to control crawling and understanding quickly what URLs are blocked by robots.txt is valuable, and it’s something that has been requested by users over the years. We have therefore introduced it as an optional configuration, for both internal and external URLs in a crawl. If you’d prefer to not see URLs blocked by robots.txt in the crawl, then simply untick the relevant boxes.
URLs which are linked to internally (or externally), but are blocked by robots.txt can obviously accrue PageRank, be indexed and appear under search. Google just can’t crawl the content of the page itself, or see the outlinks of the URL to pass the PageRank onwards. Therefore there is an argument that they can act as a bit of a dead end, so I’d recommend reviewing just how many are being disallowed, how well linked they are, and their depth for example.
Что конкретно всё это даёт?
Это все конечно хорошо, но как применять весь этот арсенал на практике? На бложиках пишут обзорчики типа «ой, а тут у нас вот тайтлы отображаются… ой, а тут дескрипшен вот считается…» Ну и? Что это даёт? Вот конкретные 9 профитов от Screaming Frog:
- 404 ошибки и редиректы. Находим через Лягушку и исправляем.
- Дубли страниц (по одинаковым Title). Находим и удаляем.
- Пустые, короткие и длинные Title. Находим, заполняем, дополняем, правим.
- Страницы с недостаточным уровнем вложенности. Выгружаем в Excel, в столбец с урлами вставляем список продвигаемых страниц, выделяем повторяющиеся значения. Смотрим, у каких продвигаемых страниц УВ не 1, не 2, и не 3 и работаем с этой проблемой.
- Длина урлов. Находим длинные урлы, сокращаем, проставляем редиректы со старых.
- «Пустые» страницы. По данным из столбца Word Count вычисляем страницы, где контента меньше, чем в среднем (или просто мало), и либо их закрываем через роботс, либо удаляем, либо наполняем.
- Самые медленные страницы. Смотрим по столбцу Response Time.
- Внешние ссылки. Удаляем либо вообще все, либо битые, которые 404 отдают.
- Совпадающие Title и H1. Находим, правим.
- Теги <strong>, <b>, <br> и так далее. Screaming Frog позволяет найти все страницы на сайте, где используются эти теги.
Это из важного. Про баловство вроде кликабельного вида Title в выдаче или пустых description я тут промолчу
Есть еще один недостаток перед PageWeight — программа не считает вес страниц. Но тут уж выручит Netpeak Spider — он умеет.
Exporting Data
You’re able to export all data into spread sheets from the crawl. Simply click the ‘export’ button in the top left hand corner to export data from the top window tabs and filters.

To export lower window data, right click on the URL(s) that you wish to export data from in the top window, then click on one of the options.

There’s also a ‘Bulk Export’ option located under the top level menu. This allows you to export the source links, for example the ‘inlinks’ to URLs with specific status codes such as 2XX, 3XX, 4XX or 5XX responses.

In the above, selecting the ‘Client Error 4XX In Links’ option above will export all inlinks to all error pages (pages that link to 404 error pages).
Closing Thoughts
The guide above should help you identify JavaScript websites and crawl them efficiently using the Screaming Frog SEO Spider tool in mode.
While we have performed plenty of research internally and worked hard to mimic Google’s own rendering capabilities, a crawler is still only ever a simulation of real search engine bot behaviour.
We highly recommend using log file analysis and Google’s own URL Inspection Tool, or using the relevant version of Chrome to fully understand what they are able to crawl, render and index, alongside a JavaScript crawler.
Additional Reading
- Understand the JavaScript SEO Basics – From Google.
- Core Principles of JS SEO – From Justin Briggs.
- Progressive Web Apps Fundamentals Guide – From Builtvisible.
- Crawling JS Rich Sites – From Onely.
If you experience any problems when crawling JavaScript, or encounter any differences between how we render and crawl, and Google, we’d love to hear from you. Please get in touch with our support team directly.
2) Google Sheets Export
You’re now able to export directly to Google Sheets.

You can add multiple Google accounts and connect to any, quickly, to save your crawl data which will appear in Google Drive within a ‘Screaming Frog SEO Spider’ folder, and be accessible via Sheets.

Many of you will already be aware that Google Sheets isn’t really built for scale and has a 5m cell limit. This sounds like a lot, but when you have 55 columns by default in the Internal tab (which can easily triple depending on your config), it means you can only export around 90k rows (55 x 90,000 = 4,950,000 cells).
If you need to export more, use a different export format that’s built for the size (or reduce your number of columns). We had started work on writing to multiple sheets, but really, Sheets shouldn’t be used in that way.
This has also been integrated into and the . This means you can schedule a crawl, which automatically exports any tabs, filters, exports or reports to a Sheet within Google Drive.
You’re able to choose to create a timestamped folder in Google Drive, or overwrite an existing file.

This should be helpful when sharing data in teams, with clients, or for Google Data Studio reporting.
4) Cookies
You can now also store cookies from across a crawl. You can choose to extract them via ‘Config > Spider > Extraction’ and selecting ‘Cookies’. These will then be shown in full in the lower window Cookies tab.

You’ll need to use mode to get an accurate view of cookies, which are loaded on the page using JavaScript or pixel image tags.
The SEO Spider will collect cookie name, value, domain (first or third party), expiry as well as attributes such as secure and HttpOnly.
This data can then be analysed in aggregate to help with cookie audits, such as those for GDPR via ‘Reports > Cookies > Cookie Summary’.

You can also highlight multiple URLs at a time to analyse in bulk, or export via the ‘Bulk Export > Web > All Cookies’.
Please note – When you choose to store cookies, the auto exclusion performed by the SEO Spider for Google Analytics tracking tags is disabled to provide an accurate view of all cookies issued.
This means it will affect your analytics reporting, unless you choose to exclude any tracking scripts from firing by using the configuration (‘Config > Exclude’) or filter out the ‘Screaming Frog SEO Spider’ user-agent similar to .
Виды парсеров по сферам применения
Для организаторов СП (совместных покупок)
Есть специализированные парсеры для организаторов совместных покупок (СП). Их устанавливают на свои сайты производители товаров (например, одежды). И любой желающий может прямо на сайте воспользоваться парсером и выгрузить весь ассортимент.
Чем удобны эти парсеры:
- интуитивно понятный интерфейс;
- возможность выгружать отдельные товары, разделы или весь каталог;
- можно выгружать данные в удобном формате. Например, в Облачном парсере доступно большое количество форматов выгрузки, кроме стандартных XLSX и CSV: адаптированный прайс для Tiu.ru, выгрузка для Яндекс.Маркета и т. д.
Популярные парсеры для СП:
- SPparser.ru,
- Облачный парсер,
- Турбо.Парсер,
- PARSER.PLUS,
- Q-Parser.
Вот три таких инструмента:
- Marketparser,
- Xmldatafeed,
- ALL RIVAL.
Парсеры для быстрого наполнения сайтов
Такие сервисы собирают названия товаров, описания, цены, изображения и другие данные с сайтов-доноров. Затем выгружают их в файл или сразу загружают на ваш сайт. Это существенно ускоряет работу по наполнению сайта и экономят массу времени, которое вы потратили бы на ручное наполнение.
В подобных парсерах можно автоматически добавлять свою наценку (например, если вы парсите данные с сайта поставщика с оптовыми ценами). Также можно настраивать автоматический сбор или обновление данных по расписания.
Примеры таких парсеров:
- Catalogloader,
- Xmldatafeed,
- Диггернаут.
7) Web Forms Authentication (Crawl Behind A Login)
The SEO Spider has standards-based authentication for some time, which enables users to crawl staging and development sites. However, there are other web forms and areas which require you to log in with cookies which have been inaccessible, until now.
We have introduced a new ‘authentication’ configuration (under ‘Configuration > Authentication), which allows users to log in to any web form within the SEO Spider Chromium browser, and then crawl it.

This means virtually all password-protected areas, intranets and anything which requires a web form login can now be crawled.
Please note – This feature is extremely powerful and often areas behind logins will contain links to actions which a user doesn’t want to press (for example ‘delete’). The SEO Spider will obviously crawl every link, so please use responsibly, and not on your precious fantasy football team. With great power comes great responsibility(!).
You can block the SEO Spider from crawling links or areas by using the or .