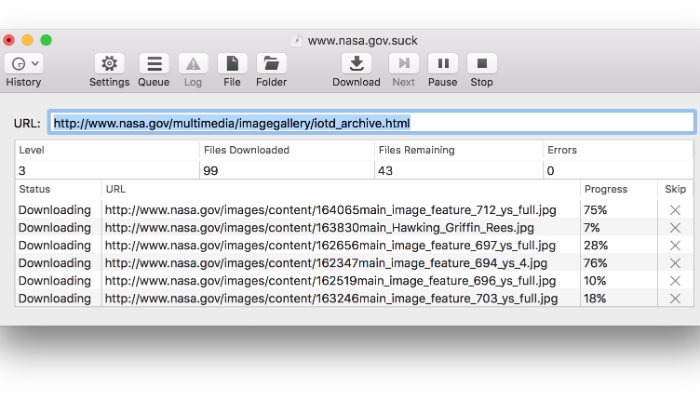
Каким был сайт раньше
Содержание:
Как просмотреть старые версии сайтов на Wayback Machine
Если вам необходимо найти старую версию страниц какого-либо веб сайта, выполните следующие действия:

Важно! Если веб-страницу через некоторое время не удается просмотреть, это может быть вызвано несколькими причинами:
- Правообладатель обратился на платформу архива интернета с требованием удалить копии.
- Сам веб-проект был закрыт из-за нарушения авторских прав и закона об использовании интеллектуальной собственности.
- Разработчики закрыли страницы своего онлайн-ресурса от индексации роботами поисковых систем.
Если вы хотите посмотреть, как выглядел веб-сайт, но на сохраненной копии нет изображений или других элементов дизайна (иногда они не сохраняются), нужно открыть другую версию, которую веб-архив сохранил в другой день.

archive.md
Адреса данного Архива Интернета:
На главной странице говорящие за себя поля:
- Архивировать страницу, которая сейчас онлайн
- Искать сохранённые страницы
Для поиска по сохранённым страницам можно как указывать конкретный URL, так и домены, например:
- microsoft.com покажет снимки с хоста microsoft.com
- *.microsoft.com покажет снимки с хоста microsoft.com и всех его субдоменов (например, www.microsoft.com)
- покажет архив данного url (поиск чувствителен к регистру)
- поиск архивных url начинающихся с http://twitter.com/burg
Данный сервис сохраняет следующие части страницы:
- Текстовое содержимое веб страницы
- Изображения
- Содержимое фреймов
- Контент и изображения загруженные или сгенерированные с помощью Javascript на сайтах Web 2.0
- Скриншоты размером 1024×768 пикселей.
Не сохраняются следующие части веб-страниц:
- Flash и загружаемый им контент
- Видео и звуки
- RSS и другие XML-страницы сохраняются ненадёжно. Большинство из них не сохраняются, или сохраняются как пустые страницы.
Архивируемая страница и все изображения должны быть менее 50 Мегабайт.
Для каждой архивированной страницы создаётся ссылка вида http://archive.is/XXXXX, где XXXXX это уникальный идентификатор страницы. Также к любой сохранённой странице можно получить доступ следующим образом:
- http://archive.is/2013/http://www.google.de/ — самый новый снимок в 2013 году.
- http://archive.is/201301/http://www.google.de/ — самый новый снимок в январе 2013.
- http://archive.is/20130101/http://www.google.de/ — самый новый снимок в течение дня 1 января 2013.
Дату можно продолжить далее, указав часы, минуты и секунды:
- http://archive.is/2013010103/http://www.google.de/
- http://archive.is/201301010313/http://www.google.de/
- http://archive.is/20130101031355/http://www.google.de/
Для улучшения читаемости, год, месяц, день, часы, минуты и секунды могут быть разделены точками, тире или двоеточиями:
- http://archive.is/2013-04-17/http://blog.bo.lt/
- http://archive.is/2013.04.17-12:08:20/http://blog.bo.lt/
Также возможно обратиться ко всем снимкам указанного URL:
http://archive.is/http://www.google.de/
Все сохранённые страницы домена:
http://archive.is/www.google.de
Все сохранённые страницы всех субдоменов
http://archive.is/*.google.de
Чтобы обратиться к самой последней версии страницы в архиве или к самой старой, поддерживаются адреса вида:
- http://archive.is/newest/http://reddit.com/
- http://archive.is/oldest/http://reddit.com/
Чтобы обратиться к определённой части длинной страницы имеется две опции:
В доменах поддерживаются национальные символы:
- http://archive.is/www.maroñas.com.uy
- http://archive.is/*.测试
Обратите внимание, что при создании архивной копии страницы архивируемому сайту отправляется IP адрес человека, создающего снимок страницы. Это делается через заголовок X-Forwarded-For для правильного определения вашего региона и показа соответствующего содержимого.
Уникальный контент из веб-архива
Многие коммерческие сайты через некоторое время существования закрываются. Если на них был опубликован полезный контент (экспертные статьи, аналитические обзоры и другая важная информация), то после закрытия первоисточника они могут быть востребованными. То есть, сайт уже не работает и ранее написанные статьи могут использоваться на информационных порталах (если они уникальны).
Веб-архив является очень полезным сервисом, который может пригодиться в различных ситуациях. Быстрое восстановление потерянных данных может значительно сэкономить время и финансы, если сайт подвергнется хакерской атаке или же перестанет работать из-за серьезной технической проблемы. Веб-архив дает возможность не только просматривать старые версии своего сайта, но и анализировать контент конкурентов, сохраненный в разные периоды времени.
Борьба с добром и российской судебной практикой
Организация Internet Archive зарегистрирована в Сан-Франциско (Калифорния, США), а одноименный ресурс, согласно законам штата Калифорния, официально считается библиотекой. Организация располагает обширным списком партнеров, в число которых входят многие крупные организации со всего мира. К ним относятся, в частности, Национальный научный фонд США и Библиотека конгресса США
Как пандемия изменила подходы к организации рабочего пространства
Бизнес

В России «Архив интернета» нередко используется российскими судами как доверенную третью сторону и источники информации, в том числе улик и доказательств расследования.
История создания архива интернета
Wayback Machine является одним из двух главных проектов archive.org. Этот некоммерческий сервис был создан в 1996 году Брюстером Кейлом. Машина времени сайтов имеет четкую цель: сбор и хранение копий ресурсов вместе со всем контентом для возможности свободного просмотра несуществующих или неподдерживающихся страниц в будущем. С 1999-го робот стал фиксировать еще и аудио, видео, иллюстрации, программное обеспечение.
База современного архива собиралась в течение 20 лет, у нее не существует аналогов. Статистика впечатляет: на сегодняшний день в сервисе находится 279 миллиардов страниц, 11 миллионов книг и статей, 100 тысяч программ и миллион картинок.
А знаете ли вы? Веб-архив сайтов часто имеет проблемы на законодательном уровне из-за нарушения авторских прав. По требованию правообладателей библиотека удаляет материалы из публичного доступа.
Компании, архивирующие интернет
Архив Интернета
В 1996 году была основана некоммерческая организация «Internet Archive». Архив собирает копии веб-страниц, графические материалы, видео-, аудиозаписи и программное обеспечение. Архив обеспечивает долгосрочное архивирование собранного материала и бесплатный доступ к своим базам данных для широкой публики. Размер архива на 2019 год — более 45 петабайт; еженедельно добавляется около 20 терабайт. На начало 2009 года он содержал 85 миллиардов веб-страниц., в мае 2014 года — 400 миллиардов. Сервер Архива расположен в Сан-Франциско, зеркала — в Новой Александрийской библиотеке и Амстердаме. С 2007 года Архив имеет юридический статус библиотеки. Основной веб-сервис архива — The Wayback Machine. Содержание веб-страниц фиксируется с временны́м промежутком c помощью бота. Таким образом, можно посмотреть, как выглядела та или иная страница раньше, даже если она больше не существует по старому адресу.
В июне 2015 года сайт был заблокирован на территории России по решению Генпрокуратуры РФ за архивы страниц, признанных содержащими экстремистскую информацию, позднее был исключён из реестра.
WebCite
«WebCite» — интернет-сервис, который выполняет архивирование веб-страниц по запросу. Впоследствии на заархивированную страницу можно сослаться через url. Пользователи имеют возможность получить архивную страницу в любой момент и без ограничений, и при этом неважен статус и состояние оригинальной веб-страницы, с которой была сделана архивная копия. В отличие от Архива Интернета, WebCite не использует веб-краулеров для автоматической архивации всех подряд веб-страниц. WebCite архивирует страницы только по прямому запросу пользователя. WebCite архивирует весь контент на странице — HTML, PDF, таблицы стилей, JavaScript и изображения. WebCite также архивирует метаданные о архивируемых ресурсах, такие как время доступа, MIME-тип и длину контента. Эти метаданные полезны для установления аутентичности и происхождения архивированных данных. Пилотный выпуск сервиса был выпущен в 1998 году, возрождён в 2003.
По состоянию на 2013 год проект испытывает финансовые трудности и проводит сбор средств, чтобы избежать вынужденного закрытия.
Peeep.us
Сервис peeep.us позволяет сохранить копию страницы по запросу пользования, в том числе и из авторизованной зоны, которая потом доступна по сокращённому URL. Реализован на Google App Engine.
Сервис peeep.us, в отличие от ряда других аналогичных сервисов, получает данные на клиентской стороне — то есть, не обращается напрямую к сайту, а сохраняет то содержимое сайта, которое видно пользователю. Это может использоваться для того, чтобы можно было поделиться с другими людьми содержимым закрытого для посторонних ресурса.
Таким образом, peeep.us не подтверждает, что по указанному адресу в указанный момент времени действительно было доступно заархивированное содержимое. Он подтверждает лишь то, что у инициировавшего архивацию по указанному адресу в указанный момент времени подгружалось заархивированное содержимое. Таким образом, Peeep.us нельзя использовать для доказательства того, что когда-то на сайте была какая-то информация, которую потом намеренно удалили (и вообще для каких-либо доказательств). Сервис может хранить данные «практически вечно», однако оставляет за собой право удалять контент, к которому никто не обращался в течение месяца.
Возможность загрузки произвольных файлов делает сервис привлекальным для хостинга вирусов, из-за чего peeep.us регулярно попадаёт в чёрные списки браузеров.
Archive.today
Сервис archive.today (ранее archive.is) позволяет сохранять основной HTML-текст веб-страницы, все изображения, стили, фреймы и используемые шрифты, в том числе страницы с Веб 2.0-сайтов, например с Твиттер.
Как сделать так, чтобы сайт не попал в библиотеку веб-архива?
Если вы дорожите контентом и не хотите видеть свою онлайн-площадку в электронной библиотеке, пропишите запретную директиву в файле robots.txt:
User-agent: ia_archiver Disallow: /
User-agent: ia_archiver-web.archive.org Disallow: /
После изменения в настройках веб-сканер перестанет создавать архивные копии вашего сайта, к тому же удалит уже сделанные слепки. Однако учтите, что ваш запрет действует лишь до тех пор, пока доступен robots.txt — когда закончится срок регистрации доменного имени, машина времени сайтов станет демонстрировать статьи всем желающим.
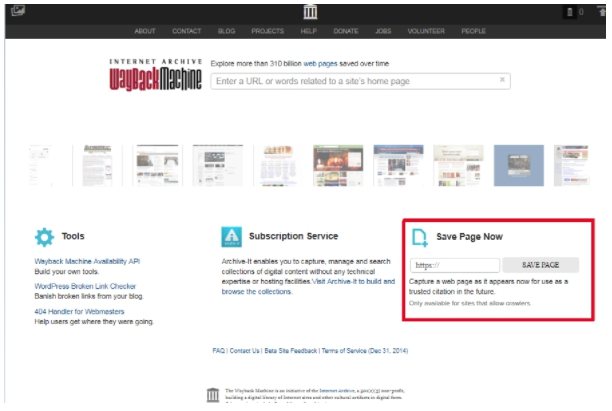
Важно! Если вы, наоборот, желаете активно пользоваться веб-архивом, введите соответствующий запрос на главной странице сервиса. Просто укажите адрес проекта в разделе Save Page Now, после чего нажмите кнопку Save Page
Повторяйте процедуру после внесения любых правок.
Смотрим, как выглядела страница раньше
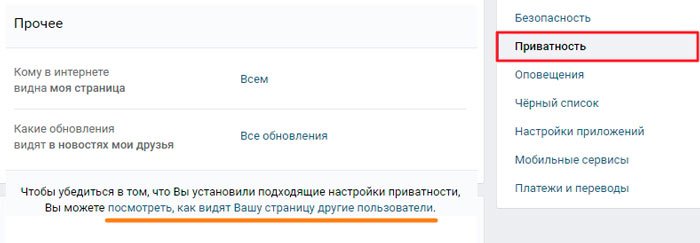
Первым делом нужно отметить, что просмотр ранней копии страницы, будь то действующий или уже удаленный аккаунт пользователя, возможен лишь тогда, когда настройки приватности не ограничивают работу поисковых систем. В противном случае сторонние сайты, включая сами поисковики, не могут кэшировать данные для дальнейшей демонстрации.
Подробнее: Как открыть стену ВК
Способ 1: Поиск Google
Наиболее известные поисковые системы, имея доступ к определенным страницам ВКонтакте, способны сохранять копию анкеты в своей базе данных. При этом срок жизни последней копии сильно ограничен, вплоть до момента повторного сканирования профиля.
- Воспользуйтесь одной из наших инструкций, чтобы найти нужного пользователя в системе Google.
Подробнее: Поиск без регистрации ВК
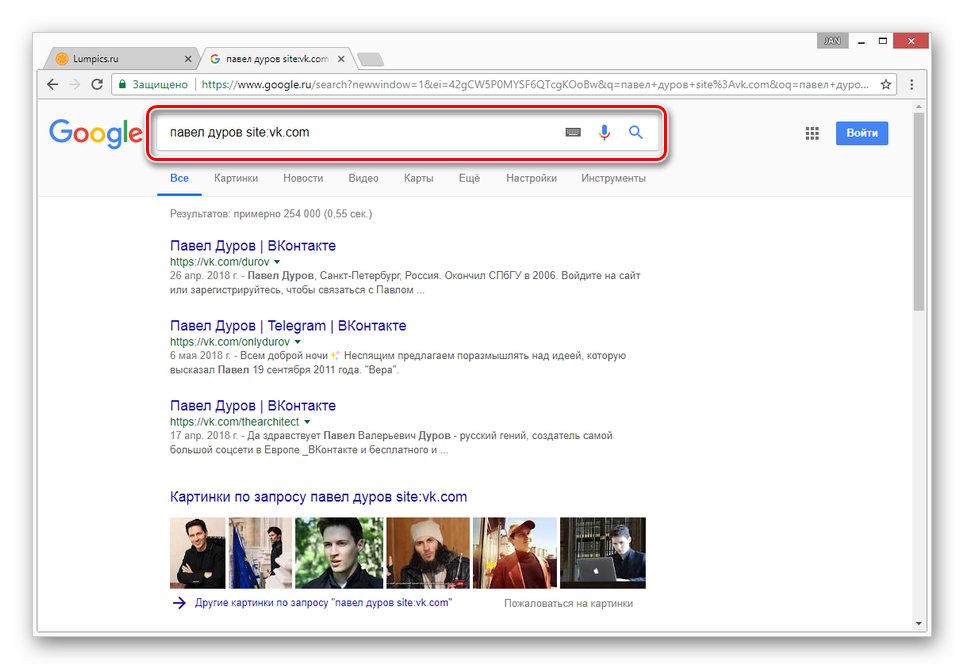
Среди представленных результатов отыщите нужный и кликните по иконке с изображением стрелочки, расположенной под основной ссылкой.

Из раскрывшегося списка выберите пункт «Сохраненная копия».

После этого вы будете перенаправлены на страницу человека, выглядящую в полном соответствии с последним сканированием.
Даже при наличии активной авторизации ВКонтакте в браузере, при просмотре сохраненной копии вы будете анонимным пользователем. В случае попытки авторизации вы столкнитесь с ошибкой или же система вас автоматически перенаправит на оригинальный сайт.
Допускается просмотр только той информации, что загружается вместе со страницей. То есть, например, посмотреть подписчиков или фотографии у вас не получится, в том числе из-за отсутствия возможности авторизации.

Использование этого метода нецелесообразно в случаях, когда необходимо найти сохраненную копию страницы очень популярного пользователя. Связано это с тем, что подобные аккаунты часто посещаются сторонними людьми и потому гораздо активнее обновляются поисковыми системами.
Способ 2: Internet Archive
В отличие от поисковых систем, веб-архив не ставит требований перед пользовательской страницей и ее настройками. Однако на данном ресурсе сохраняются далеко не все страницы, а только те, что были добавлены в базу данных вручную.
Главным отрицательным фактором способа является то, что любая информация на странице, за исключением вручную введенных данных, представлена на английском языке. Избежать этой проблемы можно, прибегнув к следующему сервису.
Способ 3: Web Archive
Данный сайт является менее популярным аналогом предыдущего ресурса, но со своей задачей справляется более чем хорошо. Кроме того, вы всегда можете воспользоваться этим веб-архивом, если ранее рассмотренный сайт по каким-либо причинам оказался временно недоступен.
- Открыв главную страницу сайта, заполните основную поисковую строку ссылкой на профиль и нажмите кнопку «Найти».

После этого под формой поиска появится поле «Результаты», где будут представлены все найденные копии страницы.

В списке «Другие даты» выберите колонку с нужным годом и кликните по наименованию месяца.

С помощью календаря кликните по одному из найденных чисел.

По завершении загрузки вам будет представлена анкета пользователя, соответствующая выбранной дате.

Как и в прошлом методе, все возможности сайта, кроме непосредственного просмотра информации, будут блокированы. Однако на сей раз содержимое полностью переведено на русский язык.

Вы также можете прибегнуть к еще одной статье на нашем сайте, рассказывающей о возможности просмотра удаленных страниц. Мы же завершаем данный способ и статью, так как изложенного материала более чем достаточно для просмотра ранней версии страницы ВКонтакте.
Опишите, что у вас не получилось.
Наши специалисты постараются ответить максимально быстро.
Как посмотреть сайт в прошлом
Есть несколько сервисов, в которых можно посмотреть, как менялось визуальное оформление страниц сайта, его структуру страниц и контент, положение в поисковой выдаче и какие изменения вносились в регистрационные данные за время существования ресурса.
Сервис Веб-архив
При его использовании сначала заходим на сайт https://web.archive.org/ и после вводим адрес страницы.
График ниже показывает количество сохранений: первое было в 1998 году.
Дни, в которые были сохранения, отмечены кружком. При клике на время во всплывающем окне, открывается сохраненная версия. Показано ниже:
Как выгрузить сайт из ВебАрхива, расскажем дальше.
Сервис Whois History
Для его использования заходим на сайт http://whoishistory.ru/ и вводим данные в поиске по доменам и IP, либо по домену:
Сервис покажет информацию по данным Whois, где собраны сведения от всех регистраторов доменных имен. Посмотреть можно возраст домена, кто владелец, какие изменения вносились в регистрационные данные и т.д.
Что такое веб-архив и зачем он нужен?
Веб-архив — история миллионов сайтов
Веб-архив — это специализированный сайт, который предназначен для сбора информации о различных интернет-ресурсах. Робот осуществляет сохранение копии проектов в автоматическом и ручном режиме, все зависит лишь от площадки и системы сбора данных.
На текущий момент имеется несколько десятков сайтов со схожей механикой и задачами. Некоторые из них считаются частными, другие — открытыми для общественности некоммерческими проектами. Также ресурсы отличаются друг от друга частотой посещения, полнотой сохраняемой информации и возможностями использования полученной истории.
Как отмечают некоторые эксперты, страницы хранения информационных потоков считаются важной составляющей Web 2.0. То есть, частью идеологии развития сети интернет, которая находится в постоянной эволюции
Механика сбора весьма посредственная, но более продвинутых способов или аналогов не имеется. С использованием веб-архива можно решить несколько проблем: отслеживание информации во времени, восстановление утраченного сайта, поиск информации.
Что такое веб-архив
Веб-архив сайтов позиционируется как своеобразная бесплатная машина времени, позволяющая вернуться на месяцы или годы назад, чтобы увидеть, как выглядел ресурс на тот момент. При этом у каждого сайта сохраняются многочисленные версии от разных дат, которые зависят от посещений проекта краулерами веб-архива. У популярных сайтов может сохраняться тысячи версий, которые обновлялись ежедневно множество раз на протяжении всего периода существования проекта:
Веб-архив основан в начале 1996 года и с этого времени в нем сохранено более 330 миллиардов веб-страниц, включая 20 миллионов книг, 4,5 миллионов аудиофайлов и 4 миллиона видео, занимающие свыше тысячи терабайт. Ежедневно сайт посещают миллионы пользователей, и он входит в ТОП-300 самых популярных проектов мира.
Цензура и другие угрозы
Archive.org в настоящее время заблокирован в Китае . После того, как террористическая организация «Исламское государство» была запрещена, Интернет-архив был полностью заблокирован в России в течение короткого периода в 2015–2016 годах, в котором размещалось информационное видео этой организации. С 2016 года веб-сайт вернулся и стал доступен полностью, хотя местные коммерческие лоббисты подали иск против Интернет-архива в местный суд, чтобы запретить его на основании авторских прав.
Элисон Макрина , директор проекта «Библиотечная свобода», отмечает, что «библиотекари глубоко ценят личную неприкосновенность частной жизни, но мы также категорически против цензуры».
Известны редкие случаи, когда интернет-доступ к контенту, который «напрасно» подвергал опасности людей, был отключен веб-сайтом.
Другие угрозы включают стихийные бедствия, разрушение (удаленное или физическое), манипуляции с содержимым архива (см. Также: кибератаки , резервное копирование ), проблемные законы об авторском праве и наблюдение за пользователями сайта.
Александр Роуз, исполнительный директор Long Now Foundation , подозревает, что в долгосрочной перспективе несколько поколений «почти ничего» выживут полезным способом, заявляя: «Если у нас будет преемственность в нашей технологической цивилизации, я подозреваю, что многие голые данные останутся доступными для поиска и поиска. Но я подозреваю, что почти ничто из формата, в котором они были доставлены, не будет узнаваемым «, потому что сайты» с глубокими внутренними системами управления контентом, такими как Drupal, Ruby и Django «труднее архив.
В статье, посвященной сохранению человеческих знаний, The Atlantic отметила, что Интернет-архив, который описывает себя как построенный на долгосрочную перспективу, «яростно работает над сбором данных до того, как они исчезнут без какой-либо долгосрочной инфраструктуры. из.»
Аспекты архивирования
Веб-архивирование, как и любой другой вид деятельности, имеет юридические аспекты, которые необходимо учитывать в работе:
- Сертификация в надёжности и целостности содержания веб-архива.
- Сбор проверяемых веб-активов.
- Предоставление поиска и извлечения из массива данных.
- Сопоставимость содержания коллекции
Ниже представлен набор инструментов, который использует Консорциум по архивированию интернета
- Heretrix — архивация.
- NutchWAX — поиск коллекции.
- Открытый исходный код «Wayback Machine» — поиск и навигация.
- Web Curator Tool — выбор и управление.
Другие инструменты с открытым исходным кодом для манипуляций над веб-архивами:
WARC-инструменты — для программного создания, чтения, анализа и управления веб-архивами.
Просто бесплатное ПО:
- Инструменты поиска Google — для полнотекстового поиска.
- WSDK — набор утилит, Erlang-модулей для создания WARC-архива.
Как проверять полученные статьи на уникальность
Есть несколько способов проверки статей на уникальность и наверное многие из них вам известны. Тем не мене здесь мы приведем лучшие способы проверки контента на уникальность.
- Проверка статей с использованием специализированных сервисов типа etxt.ru, text.ru или адвего. Данный способ подходит когда нужно проверить одну или две статьи, так как проверка занимает длительное время и существуют ограничения по количеству проверок в день с конкретного IP адреса.
- Если вам не жалко немного денег, то для ускорения процесса можно использовать пакетную проверку статей предоставляемую такими сервисами.
- Использовать специализированное программное обеспечение для проверки уникальности статей типа Advego Plagiatus.

Программа для проверки уникальности статей из Вебархива
После чего открываем программу и загружаем наши статьи для пакетной проверки используйте меню программы: «Операции -> Пакетная проверка».

Настройка программы для проверки уникальных статей из вебархива
Если у вас отсутствует необходимость проверять много статей, то просто включите отображение каптчи и вводите ее вручную.
На этом пожалуй все. Мы рассмотрели как можно получить множество уникальных статей абсолютно бесплатно. Желаем вам удачи !
Ссылки используемые в статье
- 1. web.archive.org – интернет архив веб сайтов
- 2. Web Arhcive Downloder – это уникальная программа для сохранения сайтов из интернет архива.
Как скачать все изменения страницы из веб-архива
Если вас интересует не весь сайт, а определённая страница, но при этом вам нужно проследить все изменения на ней, то в этом случае используйте программу Waybackpack.
К примеру для скачивания всех копий главной страницы сайта suip.biz, начиная с даты (—to-date 2017), эти страницы должны быть помещены в папку (-d /home/mial/test), при этом программа должна следовать HTTP редиректам (—follow-redirects):
waybackpack suip.biz -d ./suip.biz-copy --to-date 2017 --follow-redirects
Структура директорий:
Чтобы для указанного сайта (hackware.ru) вывести список всех доступных копий в веб-архиве (—list):
waybackpack hackware.ru --list
Онлайн сервисы для копирования простых сайтов
В сети существуют сервисы, которые копируют лендинг, чистят и изменяют его. Нужно указать целевой сайт, а сервис его скачает, очистит скопированную страницу от лишнего кода и чужих ссылок. Клиент получит новый одностраничник в виде готового архива для загрузки на хостинг.
Примеры таких сервисов:
copysta.ru — вы указываете адрес «донора» и сервис полностью скачивает лендинг, очищает его от лишнего кода, меняются контакты, формы заявок перестраиваются на почту заказчика, устанавливается админка для управления лендингом на хостинге заказчика. Стоимость услуг: 1 500-3 000 рублей. В самый дорогой тариф входит редактирование контента, стилей, замена изображений с целью сделать новый лендинг уникальным;
7lend.club – этот сервис предлагает услуги от простого скачивания, до очистки кода, установки счетчиков и форм заказчика и уникализации контента. Стоимость от $8 до $50 за лендинг;
copyland.pro – предлагает сделать копию лендинга любой сложности с очисткой от старых контактов, ссылок, счетчиков веб статистики и перестройку реквизитов, форм и счетчиков для заказчика. Стоимость услуг от 500 рублей; xdan.ru/copysite/ позволяет сделать локальную копию сайта. При этом можно очистить HTML от счетчиков, заменить ссылки или домен в ссылках, заменять указанные слова, всего 11 настроек. Минимальная подписка — 75 рублей на 24 часа.
Это лишь примеры сервисов. Таких подобных можно найти сотни если поискать.
Отказ от ответственности: Автор или издатель не публиковали эту статью для вредоносных целей. Вся размещенная информация была взята из открытых источников и представлена исключительно в ознакомительных целях а также не несет призыва к действию. Создано лишь в образовательных и развлекательных целях. Вся информация направлена на то, чтобы уберечь читателей от противозаконных действий. Все причиненные возможные убытки посетитель берет на себя. Автор проделывает все действия лишь на собственном оборудовании и в собственной сети. Не повторяйте ничего из прочитанного в реальной жизни. | Так же, если вы являетесь правообладателем размещенного на страницах портала материала, просьба написать нам через контактную форму жалобу на удаление определенной страницы, а также ознакомиться с инструкцией для правообладателей материалов. Спасибо за понимание.