Как создать облако тегов онлайн
Содержание:
Построение облака слов
Чтобы построить облако слов нужно:
- Получить данные для анализа, в нашем случае — твиты. Но это может быть и обычный текстовый файл.
- Выделить текст из твитов.
- Создать лексический корпус и терм-документную матрицу (с помощью функций пакета tm).
- Получить ключевые слова и частоту их упоминания.
- Нарисовать облако слов.
Шаг 1. Получим твиты и сохраним их в переменной tweets:
tweets <- ("data mining", n=500, lang="en")
Ограничимся пока твитами на английском языке.
Rемарка 3. Типы данных. Основным типом данных в R является вектор — последовательность данных одного типа. Векторы бывают числовые и символьные. Пример создания символьного вектора: . Функция выполняет конкатенацию. Скаляров как таковых нет, скаляром считается вектор, состоящий из одного элемента. Есть еще списки — они похожи на векторы, но могут хранить элементы любого типа.
Для хранения двумерных данных существуют матрицы и таблицы (data frame). Матрицы быстрее, но могут хранить только один тип данных. Таблицы могут хранить в разных колонках данные разных типов и, кроме того, к колонкам можно обращаться по имени, а не по индексу.
Шаг 2. К каждому твиту применим функцию выделения текста:
text = sapply(tweets, function(x) x$getText())
Шаг 3. Вообще говоря, лексический корпус — это коллекция текстов, подлежащих анализу. В нашем случае — это символьный вектор с несколькими дополнительными атрибутами.
Терм-документная матрица описывает частоту терминов, которые встречаются в документах корпуса: строки матрицы соответствуют документам, столбцы — терминам. Значение элемента матрицы равно частоте употребления термина в документе.
Для построения лексического корпуса и терм-документной матрицы используются функции и :
corpus <- Corpus(VectorSource(text))
tdm <- TermDocumentMatrix(corpus,
control = list(removePunctuation = TRUE,
stopwords = c("data", "mining", stopwords("english")),
removeNumbers = TRUE,
tolower = TRUE))
С помощью параметра мы выполняем очистку текста от символов пунктуации, стоп-слов (например, артиклей английского языка), чисел и переводим все буквы в строчные.
Шаг 4. Сохраним терм-документную матрицу как обычную матрицу, отсортируем частоты в порядке убывания и сохраним результат в виде таблицы:
m <- as.matrix(tdm) word_freqs <- sort(rowSums(m), decreasing=TRUE) dm <- data.frame(word=names(word_freqs), freq=word_freqs)
Напомню, что в — это часть имени, а не оператор доступа к полям структуры.
Шаг 5. Осталось лишь нарисовать облако. Это делается функцией одноименного пакета:
wordcloud(dm$word, dm$freq, random.order=FALSE, colors=brewer.pal(8, "Dark2"))
Можно сохранить историю команд c помощью меню «Файл», исправить ее, если нужно, а затем загрузить с помощью все того же меню полученный скрипт (текстовый файл с расширением .r или .R). В нем всего 16 строк:
library()
library(tm)
library(wordcloud)
api_key <- "..."
api_secret <- "..."
access_token <- "..."
access_token_secret <- "..."
(api_key,api_secret,access_token,access_token_secret)
tweets <- ("data mining", n=500, lang="en")
text <- sapply(tweets, function(x) x$getText())
corpus <- Corpus(VectorSource(text))
tdm <- TermDocumentMatrix(corpus, control = list(removePunctuation = TRUE, stopwords = c("data", "mining", stopwords("english")), removeNumbers = TRUE, tolower = TRUE))
m <- as.matrix(tdm)
word_freqs <- sort(rowSums(m), decreasing=TRUE)
dm <- data.frame(word=names(word_freqs), freq=word_freqs)
wordcloud(dm$word, dm$freq, random.order=FALSE, colors=brewer.pal(8, "Dark2"))
Значения ключей Twitter API у вас будут свои. Вставьте их вместо многоточий.
Не факт, что результат у вас совпадет с моим — ведь появятся новые твиты. А параметров у них много, например, географические координаты. Так что теперь мы можем с помощью R построить карту пристрастий пользователей Twitter. Можем смотреть, как эти пристрастия изменяются со временем. Можем… Но все это — темы для других статей.
Простое облако слов
Сперва подготовим входной текст:
Мы импортировали в проект только что установленную библиотеку wikipedia и библиотеку re для работы с регулярными выражениями. Затем указали язык «Википедии» и имя интересующей нас страницы (сохранили её в переменную wiki). Разумеется, вы можете взять любую другую страницу.

Текстовое содержимое страницы ушло в переменную text, после чего с помощью регулярных выражений мы удалили из него ненужные символы (знаки препинания, перевода абзацев, лишние разделители).
Теперь нам нужны библиотека и функция для визуализации текста. Библиотеку мы импортируем, а функцию напишем сами — она нам ещё пригодится.
Команда %matplotlib inline указывает, что графики будут отрисованы прямо в блокноте колаба, а не где-то в отдельном окне.
Что касается функции plot_cloud, то она принимает параметром облако слов (мы создадим его ниже), устанавливает размер картинки в дюймах и выводит её, а метод axis c аргументом «off» отключает подписи внизу и слева.
Всё почти готово, осталось главное.
Вы можете добавить свои стоп-слова в переменную STOPWORDS_RU с помощью метода .add (‘новое стоп-слово’).
Параметр random_state=1 — если не указать, то при каждом запуске функции облако слов будет отличаться от предыдущего.
Параметр collocations определяет, включать ли в итоговую картинку сочетания из двух слов (так называемые биграммы). У нас он отключён, поэтому фраз в облаке не будет.

Сохраним получившуюся картинку в файл:
Её можно будет найти в меню «Файлы» слева и скачать.
Типы применения тегов
Облако данных показывает население всех стран мира. Создано с помощью языка программирования R с помощью пакета облако слов. Данные получены из списка, содержащего название стран и количество жителей
Обратите внимание, что относительные размеры Китая и Индии были разделены пополам.
Существует три основных типа применения облаков тегов в социальном программном обеспечении, различающихся скорее по назначению, чем по внешнему виду:
-
- в первом типе есть тег для частоты каждого элемента,
- во втором типе есть глобальные облака тегов, где частоты агрегированы по всем элементам и пользователям,
- в третьем типе облако содержит категории, размер которых обозначает количество подкатегорий.
В первом типе облаков тегов размер представляет собой количество применений тега к элементу. Это полезно в качестве способа отображения метаданных о предмете, за который сколько-то раз «проголосовали», и когда точные данные не предусмотрены. Примером такого применения является Last.fm (для определения жанра музыки группы) и LibraryThing (для определения ключевых слов книги).
Во втором типе размер соответствует числу предметов, к которым был применен тег, что обозначает популярность тега. Примеры данного типа облаков тегов можно найти на сайте сервиса хранения и распространения цифровых фотографий Flickr, RSS-агрегатора Technorati и введя в поисковый запрос DeeperWeb.
Категоризация путём создания кластера тегов
В третьем типе теги используются как способ категоризации элементов. Теги представлены в облаке, где бо́льшие теги представляют количество элементов в этой категории.
Есть несколько подходов для построения кластера тегов вместо облака тегов, например, применяя теги совместной встречаемости в документах.
Более обще, то же самое визуальное представление может быть использовано для отображения не тегов например, облако тегов или облака данных.
Термин облако ключевых слов иногда используется как термин поисковый маркетинг, где он обозначает группы ключевых слов, относящихся к некоторому веб-сайту. В последние годы облака тегов стали популярны из-за своей значимости в поисковом маркетинге веб-страниц, наряду с помощью пользователям в эффективной навигации по сайтам. Облака тегов, как средства навигации, позволяют связать ресурсы веб-сайта более тесно,обход таких ресурсов поисковым роботом может улучшить позицию сайта в результатах выдачи поисковой системы. С точки зрения пользовательского интерфейса облака тегов часто используются, чтобы помочь пользователю найти информацию в конкретной системе более быстро, обобщая результаты поиска.
Создание облака тегов
В общем размер шрифта тега в облаке тегов обусловлен распространенностью тега. Для облака слов, например, категорий блога, частота соответствует количеству записей в блоге, которым присвоена данная категория. Для меньших частот можно указать размеры шрифта непосредственно, от единицы до максимально используемого размера шрифта. Для больших частот необходимо провести масштабирование. Например, используя линейное преобразование, вес ti{\displaystyle t_{i}} тега масштабируется по шкале множителей от of 1 до f, где tmin{\displaystyle t_{min}} и tmax{\displaystyle t_{max}} определяют диапазон разрешенных весов.
si=⌈fmax⋅(ti−tmin)tmax−tmin⌉{\displaystyle s_{i}=\left\lceil {\frac {f_{\mathrm {max} }\cdot (t_{i}-t_{\mathrm {min} })}{t_{\mathrm {max} }-t_{\mathrm {min} }}}\right\rceil } для ti>tmin{\displaystyle t_{i}>t_{\mathrm {min} }}; иначе si=1{\displaystyle s_{i}=1}
Набор слов из списка 1000 избранных статей Википедии, упорядоченный по количеству просмотров, доступный в галерее Wordle gallery.
- si{\displaystyle s_{i}}: размер шрифта
- fmax{\displaystyle f_{\mathrm {max} }}: максимальный размер шрифта
- ti{\displaystyle t_{i}}: вес тега
- tmin{\displaystyle t_{\mathrm {min} }}: минимальный вес
- tmax{\displaystyle t_{\mathrm {max} }}: максимальный вес
Так как число учтённых элементов на каждый тег обычно распределено по экспоненциальному закону распределения, поэтому для больших диапазонов значений имеет смысл использовать логарифмическое представление.
Реализация облака тегов также включает синтаксический анализ фильтрацию ненужных тегов, таких как предлоги, местоимения, чи́сла и знаки препинания.
Также существуют веб-сайты, которые создают искусственные или случайно распределённые облака тегов для рекламы или с юмористической целью.
Создание структуры облака тегов
Дабы не запутываться в бесконечном количестве тегов, я решил разбить их по трем основным направлениям: темы постов, типы и цели. К темам в моем случае относятся:Web разработка: HTML, CSS, JavaScript, PHP, Ajax, CMS.ИТ (информационный технологии): Hardware, Software, Web, компьютерные игры.Дизайн: фотография, веб-дизайн, графические редакторы, кисти, иконки, photoshop.Блогинг: новости блогосферы, движки, тенденции, социальные сети.SEO и монетизация: SEO, монетизация блога, заработок в интернете.
Это лишь небольшое количество тем и подразделов. Все приводить нет смысла, многие еще появятся – это необратимый процесс. Так, например, в моем блоге можно встретить совсем не интернетовские теги «Юмор» и «Футбол».
Разбить посты по типу немного проще, это новости, статьи, обзоры, мысли вслух. В принципе, все понятно. Последний тег означает некоторые личные заметки, размышления. Что касается целей, то я выделил следующие теги: интересное, полезное, практика, советы.
«Облако тегов» – что же это такое?
В общем понимании «облако тегов» – это набор ключевых характеристик товаров, которые пользуются спросом у пользователей.
Расшифруем:
- Тег – это запрос категории/товара с определенным наборов свойств. Например: «красный диван», «крем для лица 50 », «блокнот 48 листов».
- Облако тегов – это формат вывода под различные категории каталога уникальных тегов.
- Еще есть термин «тегирование» – это обозначение самого действия по формированию облака тегов на основе запросов (тегов).
Основная задача тегирования – создание наибольшего количества точек входа на сайт по низко- и среднечастотным запросам.
Основная цель тегирования – возможность «на пустом месте» заметно увеличить семантическое ядро сайта, и тем самым повлиять на посещаемость сайта через наращивание количества точек входа из поиска.
Поговорим немного о юзабилити и о том, как облако тегов изменилось более чем за 15 лет.
Облако тегов в далеком 2000-м году:
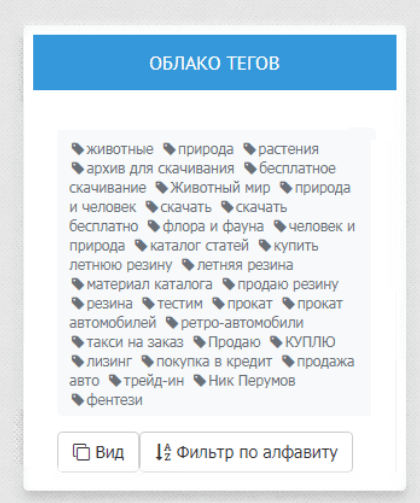
Облако тегов сейчас:


Что же изменилось:
- нет того большого блока с перечнем всевозможных тегов, от которого и произошло выражение «облако тегов»;
- тегирование стали реализовывать более функционально – с помощью слайдера или раскрытия тегов;
- стало сложнее подбирать теги для облака в связи с колоссальными изменениями требований поисковых систем.
Можно сделать вывод, что облако тегов просто модернизировалось с годами и стало, на наш взгляд, гораздо удобнее в использовании.
TagCrowd

TagCrowd has some unique features – and limitations – compared to the other word cloud generators on this list. For example, you can paste in the URL of any website and create a word cloud from the text on that page. You can also opt to add a number alongside each word in the cloud, to explicitly show how often it appears on the webpage (or in whatever text you used). These features and others make TagCrowd feel more like an analysis tool than an artwork creator. On that note, visualizations are . What you see is what you get. Use TagCrowd when strict, clear measurement is more important than aesthetics.
Dataset
Для демонстрации я взял весь отрывок из одного из моихсредние статьи, Я скопировал весь текст независимо от содержания и поместил его вфайл. Затем я запустил небольшой скрипт на python, чтобы сохранить слова и их частоты в файле CSV. Вы можете использовать любой набор данных по вашему выбору.
from collections import Counterdef word(fname): with open(fname) as f: return Counter(f.read().split())print(word_count("text.txt"))

import csvmy_dict = word_count("text.txt")with open('test.csv', 'w') as f: for key in my_dict.keys(): f.write("%s,%s\n"%(key,my_dict))
это файл, который содержит наш набор данных и будет выглядеть так:
Теперь переключитесь на Tableau.
Создайте облако слов, как описано выше, используя слова вtext.csvфайл.

Если вы хотите ограничить количество записей, вы можете использовать количество слов в качестве фильтра и показывать только слова с минимальной частотой.

Удалить наиболее распространенные слова -Даже после фильтрации по количеству слов мы видим, что есть такие слова, как ‘’,‘ вИ т. Д., Которые не имеют большого значения, но появляются по всему листу. Давайте избавимся от них. Мы начнем с созданиясписок общих слов на английском языкек которому можно получить доступ изВот, Список содержит слова, имеющие связанный с ними ранг, который мы будем использовать в качестве меры для фильтрации.
общие слова на английском
- Теперь давайте добавим этот лист в нашу книгу. Два листа будут смешаны ссловастолбец, так как это является общим для обоих источников.
- Создайте новый параметр и назовите его «Слова должны быть исключены»Со следующими настройками:

Показать элемент управления параметрами и исключить наиболее распространенные слова из облака путем фильтрации.

рабочая тетрадь
Теперь измените настройки, и у вас получится более качественное облако слов с параметрами фильтра.

Типы
Облако данных, показывающее население каждой из стран мира. Создано в R с помощью пакета wordcloud . Данные по населению страны
Обратите внимание, что пропорциональные размеры Китая и Индии разделились пополам
В социальном программном обеспечении существует три основных типа приложений облака тегов , которые различаются по своему значению, а не по внешнему виду. В первом типе есть тег для частоты каждого элемента, тогда как во втором типе есть глобальные облака тегов, в которых частоты агрегированы по всем элементам и пользователям. В третьем типе облако содержит категории, размер которых указывает на количество подкатегорий.
Частота
В первом типе размер представляет количество раз, когда тег был применен к одному элементу. Это полезно как средство отображения метаданных об элементе, за который демократическим путем «проголосовали» и где точные результаты нежелательны.
Во втором, более часто используемом типе, размер представляет собой количество элементов, к которым был применен тег, как представление популярности каждого тега .
Значимость
Вместо частоты можно использовать размер для представления значимости слов и их совпадения по сравнению с фоновым корпусом (например, по сравнению со всем текстом в Википедии). Этот подход нельзя использовать отдельно, он основан на сравнении частот документов с ожидаемыми распределениями.
Категоризация
В третьем типе теги используются как метод категоризации для элементов контента. Теги представлены в облаке, где более крупные теги представляют количество элементов контента в этой категории.
Существует несколько подходов к созданию кластеров тегов вместо облаков тегов, например, путем применения одновременного появления тегов в документах.
В более общем плане для отображения данных без тегов можно использовать тот же визуальный прием, как в облаке слов или облаке данных.
Термин « облако ключевых слов» иногда используется в качестве термина поискового маркетинга (SEM), который относится к группе ключевых слов, имеющих отношение к определенному веб-сайту. В последние годы облака тегов приобрели популярность из-за их роли в поисковой оптимизации веб-страниц, а также в поддержке пользователя в эффективной навигации по контенту в информационной системе. Облака тегов в качестве инструмента навигации делают ресурсы веб-сайта более связанными при сканировании пауком поисковой системы, что может улучшить рейтинг сайта в поисковых системах . С точки зрения пользовательского интерфейса они часто используются для обобщения результатов поиска, чтобы помочь пользователю быстрее найти контент в конкретной информационной системе.
Thought-provoking word clouds
These ones make your participants think, feel, and give your meeting or event a bit of a personal touch. And we mean that literally – some of these word clouds are really quite touching.
What’s the first thing you will do once the quarantine is over?
In one word, what’s the biggest challenge you’re facing when working from home?
Who was your silent hero last week/month?
Who is your ultimate female role model?
Pro tip #3: Running a word cloud is a great interactive activity for virtual or hybrid meetings and events because it allows everyone – remote or on-site – to join and chip in with their idea.
Pro tip #4: As a speaker, use the collected words in the word cloud to kick-off your presentation on a positive note. Once the word cloud starts to fill in with words, comment on how your audience voted and make funny remarks.
More word cloud ideas:
- If you’d like to say thanks to someone, you can do it here.
- Which industry figure is your personal hero?
- What’s the first thing that comes to your mind when you hear the word ‘leader’?
- Which global brand do you admire?
- If you could go for a coffee with one historical figure, who would it be?
- In one word, what’s the best tech invention of the 21st Century?
- Which skills or qualities make one a good manager?
- What makes a great webinar/event/meeting?
Read also: 80+ Best Poll Questions To Ask Your Online Audience
Внешний вид
Облака тегов обычно представлены с помощью встроенных HTML- элементов. Теги могут располагаться в алфавитном порядке, в произвольном порядке, их можно отсортировать по весу и так далее. Иногда в дополнение к размеру шрифта манипулируют и другими визуальными свойствами, такими как цвет, интенсивность или насыщенность шрифта. Наиболее популярным является прямоугольное расположение тегов с сортировкой по алфавиту в последовательном построчном макете. Решение об оптимальном макете должно определяться ожидаемыми целями пользователя. Некоторые предпочитают группировать теги семантически, чтобы похожие теги появлялись рядом друг с другом, или используют методы встраивания , такие как tSNE, для позиционирования слов. Края могут быть добавлены, чтобы подчеркнуть совместное появление тегов и визуализировать взаимодействия. Эвристику можно использовать для уменьшения размера облака тегов, независимо от того, является ли цель кластеризацией тегов.
Визуальная таксономия облака тегов определяется рядом атрибутов: правилом упорядочения тегов (например, в алфавитном порядке, по важности, по контексту, случайным образом, в порядке визуального качества), формой всего облака (например, прямоугольник, круг, заданные границы карты), форма границ тега (прямоугольник или тело символа), вращение тега (нет, свободно, ограничено), вертикальное выравнивание тега (придерживаясь типографских базовых линий, бесплатно). Облако тегов в Интернете должно решать проблемы моделирования и управления эстетикой, построения двумерного макета тегов, и все это должно выполняться в короткие сроки на изменчивой платформе браузера
Облака тегов, которые будут использоваться в Интернете, должны быть в формате HTML , а не в графике, чтобы сделать их удобочитаемыми для роботов, они должны быть созданы на стороне клиента с использованием шрифтов, доступных в браузере, и они должны помещаться в прямоугольное поле.
Как создать слово облако с помощью Python?
Итак, давайте начнем с создания собственного облака слова, используя Python.
1. Установите библиотеки WordCloud и Wikipedia
Чтобы создать слово облако, нам нужно иметь Python 3.x на наших машинах, а также WordCloud установлены. Чтобы установить WordCloud, вы можете использовать команда PIP :
sudo pip install wordcloud
Для этого я буду пользоваться веб-страницей из Википедии, а именно – Python (язык программирования) Отказ Чтобы использовать содержимое Wikipedia, нам нужно установить Зависимости Wikipedia Отказ
sudo pip install wikipedia
2. Поиск Википедии на основе запроса
Во-первых, мы импортируем Библиотека, использующая фрагмент кода ниже:
import wikipedia
Мы будем использовать Функция и только сделать первый элемент из этого, поэтому мы используем . Это будет название нашей страницы.
def get_wiki(query): title = wikipedia.search(query) # get wikipedia page for selected title page = wikipedia.page(title) return page.content
После извлечения мы используем и извлечь содержимое страницы. После этого мы вернем только страницы, используя Отказ
Если вы запустите вышеуказанный код на консоли, вы получите все необработанные данные с сайта на консоли. Но наша задача здесь не заканчивается, нам нужно сделать слово облако.
3. Создайте облачную маску и установите сложные слова
Для начала мы импортируем Библиотека и импортировать определенные пакеты, такие как и Отказ
Мы импортируем Потому что мы хотим удалить основные статьи, такие как а, а и другие общие слова используется на английском языке.
from wordcloud import WordCloud, STOPWORDS
Мы будем использовать Отказ Эта грубая диаграмма названа как «Cloud.png» в текущем рабочем каталоге, обозначенном Отказ Мы откроем это изображение и храним его в Numpy Array.
Наша следующая задача – определить набор стоп-слов и, следовательно, мы используем Отказ
Мы создаем облако слова, используя объект Python, используя (). Мы пройдем параметры, такие как , (Здесь мы выбираем наше ограничение словом как 200), и Отказ
Затем мы будем использовать и пройти необработанный текст в качестве параметра.
Мы также можем сохранить облако слова, создаваемые в файл, и мы назовем его как Отказ
def create_wordcloud(text): mask = np.array(Image.open(path.join(currdir, "cloud.png"))) stopwords = set(STOPWORDS) # create wordcloud object wc = WordCloud(background_color="white", max_words=200, mask=mask, stopwords=stopwords) wc.generate(text) # save wordcloud wc.to_file(path.join(currdir, "output.png"))
Запуск этих 2 функций может принять до 30-40 секунд в первый раз и может уменьшиться в дальнейшем прогона. Полный код и выходное изображение так, как показано ниже в следующем разделе.
When Not To Use Word Clouds
Simply dumping a scene from your current work in progress into a word cloud generator might show you that you used “said” a lot, but won’t give you the insights you want. But using word clouds to compare your scenes against each other can show you where they’re too similar, use too many of the same unimportant word choices, or simply aren’t consistent between scenes when they need to be.
Likewise, in copywriting for business, you wouldn’t use a word cloud when your content isn’t optimized for keywords. A word cloud on a blog post that’s not SEO enhanced won’t tell you much about your keyword density.
No matter what you’re writing, word clouds are something to use as a last step in your writing process. Word choice falls under «line edits.» If you have an unedited first draft, word clouds won’t help you much. You’ll likely need to make major structural changes before you use a word cloud.
Восприятие
Облака тегов были предметом изучения в нескольких исследованиях удобства использования. Нижеследующее резюме основано на обзоре результатов исследования, сделанного Ломанн и др .:
- Размер тега: большие теги привлекают больше внимания пользователя, чем маленькие теги (эффект зависит от дополнительных свойств, например, количества символов, положения, соседних тегов).
- Сканирование: пользователи сканируют, а не читают облака тегов.
- Центрирование: теги в середине облака привлекают больше внимания пользователя, чем теги рядом с границами (эффект зависит от макета ).
- Позиция: левый верхний квадрант привлекает больше внимания пользователей, чем другие (западные читательские привычки).
- Исследование: облака тегов обеспечивают неоптимальную поддержку при поиске определенных тегов (если они не имеют очень большого размера шрифта).
Феликс и др. сравнили, чем производительность чтения человеком отличается от традиционных облаков тегов, которые сопоставляют числовые значения с размером шрифта, и альтернативных дизайнов, которые используют, например, цвет или дополнительные формы, такие как круг и полосы. Они также сравнили, как различное расположение слов влияет на производительность.
- Использование дополнительной полосы или кружка вместо размера шрифта повышает точность чтения числового значения
- Однако пользователи могут быстрее находить конкретное слово, если не используется дополнительная отметка.
- Производительность зависит от задачи, простые задачи, такие как поиск слова, сильно зависят от выбора дизайна, однако влияние на такие задачи, как определение темы облака тегов, намного меньше.
Abcya.com

ABCya’s word cloud generator is more toy than tool. It feels like a simplified version of WordCloud.com, sacrificing all but the most basic customization options for a kid-friendly interface that’s easy to use. You can whip up a basic word cloud in moments using a handful of preset color schemes, shapes, and fonts. If WordCloud.com is a blank canvas, then ABCya is a coloring book. The only hiccup I found occurred when saving an image of my word cloud. The bottom of the image was cut off, but fiddling with the options fixed the issue. This is probably the generator to choose if you’re planning to make word clouds in an elementary school classroom.
Что учесть, создавая теги?
Про плюсы инструмента мы рассказали, про ошибки в применении – тоже
А про то, на что важно обратить внимание, формируя облако тегов? Хм – нет. Исправляемся!
Список основных факторов, влияющих на эффективность тегирования
Динамичность спроса.
Также не забывайте про сезонность. Согласитесь, товарную категорию «лыжи» летом пользователи будут искать реже, чем зимой. Данные Wordstat Yandex этому доказательство:

Время от времени обновляйте семантическое ядро или хотя бы частотность по уже имеющимся запросам: убирайте теги по неактуальным запросам и добавляйте новые под средне- и низкочастотные запросы. Частоту обновлений вы можете выбрать сами: раз в месяц, квартал или раз в полгода.
Уникальный набор товаров.
Страницы тегов должны иметь уникальный контент, подходящий под параметры запросов тегов.
Нюансы по запросам.
Не используйте слишком длинные запросы. Да, они хороши для оптимизации под голосовой поиск, но представьте, как будет выглядеть тег из шести длинных слов с пятью характеристиками.
Частотность – а нужно?
Подбирайте запросы для тегов только на основе точной или уточненной частотности. Во-первых, нет смысла использовать запрос с общей частотностью 259, если ее точная частотность 0, потому что в такой формулировке продукцию никто не ищет. Во-вторых, точный подбор даст понять, какой из запросов на самом деле принесет выгоду вашему сайту.
Думать – нужно, придумывать – сложно.
Не придумывайте запросы, а находите их различными способами: расширением запросов в Key Collector, с помощью подсказок поисковых систем, постраничной выгрузкой семантики конкурентов и так далее. Если все-таки вы творческая натура и запросы генерируются в голове сами, то не забывайте их проверять по вышеперечисленным пунктам.
Как же без интента?
Анализировать запросы нужно не только на частотность, но и на интент. Это слово очень часто используют специалисты по продвижению, но что уж говорить – оно несет в себе важнейший смысл. Напомним: «интент» означает намерение пользователя, которое отражается в запросе. Или проще – то, что хочет увидеть пользователь при вводе определенного запроса.
Говоря про ошибки, мы уже убедились, как запрос с неправильным интентом может не только не дать результатов, но даже ухудшить ситуацию (если дублей страниц тегов большое количество).
Шпионаж.
Не забывайте про конкурентов! Кто они? Зачем их учитывать?
1. Это сайты компаний, которые вызывают у вас вау-эмоции или мысль «вот бы по этому запросу тоже на первое место».
Что делаем: с помощью сервисов выгружаем уже активную семантику на страницах конкурента
Начинаем с маржинальных категорий (нам же важно увеличить трафик, а вместе с ним и количество покупок). Далее «чистим семантику», собираем частотность, группируем, собираем позиции
После этого дело останется за малым – выбрать запросы для наших тегов.
2. Также конкурентами можно считать сайты, которые очень быстро попали в топ-10 (или сразу в топ-5) по запросам вашей тематики. Оказались они там, вероятнее всего, по трем причинам:
- на сайте проведено большое количество работ по оптимизации и поисковые системы, наконец-то, оценили весь его потенциал. В этом случае просто необходимо понять, какие действия были совершены;
- накрутили поведенческие факторы (не будем об этом);
- попали туда случайно.
Пока мы не проанализируем такой сайт, увы, не поймем причину. Если она кроется в действиях по оптимизации, то делаем оптимизацию. Если нет, то идем искать точки входа другими способами.
Уникальность
Для каждого тега необходимо выполнить следующее:
- Создать отдельную страницу с ЧПУ.
- Прописать мета-теги. Одного шаблона на все теги будет достаточно, но после проведения динамики показателей их можно, а чаще даже нужно, корректировать.
- По возможности на страницы тегов добавить похожие (смежные) теги.