Регулярное выражение в php. что такое регулярные выражения?
Содержание:
Введение в регулярные выражения
Язык регулярных выражений предназначен специально для обработки строк. Он включает два средства:
-
Набор управляющих кодов для идентификации специфических типов символов
-
Система для группирования частей подстрок и промежуточных результатов таких действий
С помощью регулярных выражений можно выполнять достаточно сложные и высокоуровневые действия над строками:
-
Идентифицировать (и возможно, помечать к удалению) все повторяющиеся слова в строке
-
Сделать заглавными первые буквы всех слов
-
Преобразовать первые буквы всех слов длиннее трех символов в заглавные
-
Обеспечить правильную капитализацию предложений
-
Выделить различные элементы в URI (например, имея http://www.professorweb.ru, выделить протокол, имя компьютера, имя файла и т.д.)
Главным преимуществом регулярных выражений является использование метасимволов — специальные символы, задающие команды, а также управляющие последовательности, которые работают подобно управляющим последовательностям C#. Это символы, предваренные знаком обратного слеша (\) и имеющие специальное назначение.
В следующей таблице специальные метасимволы регулярных выражений C# сгруппированы по смыслу:
Метасимволы, используемые в регулярных выражениях C#
Символ
Значение
Пример
Соответствует
Классы символов
Любой из символов, указанных в скобках
В исходной строке может быть любой символ английского алфавита в нижнем регистре
Любой из символов, не указанных в скобках
В исходной строке может быть любой символ кроме цифр
.
Любой символ, кроме перевода строки или другого разделителя Unicode-строки
\w
Любой текстовый символ, не являющийся пробелом, символом табуляции и т.п.
\W
Любой символ, не являющийся текстовым символом
\s
Любой пробельный символ из набора Unicode
\S
Любой непробельный символ из набора Unicode
Обратите внимание, что символы \w и \S — это не одно и то же
\d
Любые ASCII-цифры. Эквивалентно
\D
Любой символ, отличный от ASCII-цифр
Эквивалентно
Символы повторения
{n,m}
Соответствует предшествующему шаблону, повторенному не менее n и не более m раз
s{2,4}
«Press», «ssl», «progressss»
{n,}
Соответствует предшествующему шаблону, повторенному n или более раз
s{1,}
«ssl»
{n}
Соответствует в точности n экземплярам предшествующего шаблона
s{2}
«Press», «ssl», но не «progressss»
?
Соответствует нулю или одному экземпляру предшествующего шаблона; предшествующий шаблон является необязательным
Эквивалентно {0,1}
+
Соответствует одному или более экземплярам предшествующего шаблона
Эквивалентно {1,}
*
Соответствует нулю или более экземплярам предшествующего шаблона
Эквивалентно {0,}
Символы регулярных выражений выбора
|
Соответствует либо подвыражению слева, либо подвыражению справа (аналог логической операции ИЛИ).
(…)
Группировка. Группирует элементы в единое целое, которое может использоваться с символами *, +, ?, | и т.п. Также запоминает символы, соответствующие этой группе для использования в последующих ссылках.
(?:…)
Только группировка. Группирует элементы в единое целое, но не запоминает символы, соответствующие этой группе.
Якорные символы регулярных выражений
^
Соответствует началу строкового выражения или началу строки при многострочном поиске.
^Hello
«Hello, world», но не «Ok, Hello world» т.к. в этой строке слово «Hello» находится не в начале
$
Соответствует концу строкового выражения или концу строки при многострочном поиске.
Hello$
«World, Hello»
\b
Соответствует границе слова, т.е. соответствует позиции между символом \w и символом \W или между символом \w и началом или концом строки.
\b(my)\b
В строке «Hello my world» выберет слово «my»
\B
Соответствует позиции, не являющейся границей слов.
\B(ld)\b
Соответствие найдется в слове «World», но не в слове «ld»
Поиск текста между тегами
Допустим, у нас есть следующий текст:
И из него нужно достать текст, который находится между тегами <span> и </span>.
Проще всего это сделать с помощью регулярных выражений:
Функция preg_match_all() принимает 3 параметра: шаблон поиска, сам текст и переменную, в которую эта функция сохранит результаты поиска.
Поскольку функция возвращает количество найденных строк (или false в случае ошибки), мы можем сразу подставить её в оператор if.
Массив с результатами поиска (в нашем случае $result) состоит из двух частей: в $result будут найденные строки вместе с открывающим и закрывающим тегами span, а в $result будут те же строки без тега span, т.е. тот текст, что находится в круглых скобках.
Маска регулярного выражения находится между вертикальными чертами |. В шаблоне (.*) точка означает любой символ, звёздочка — любое количество символов (т.е. суммарно получаем «любое количество любых символов»).
Скобки говорят, что найденный текст нам нужно получить отдельно. Без скобок мы получим только $result, а $result не будет существовать.
Чтобы найти только не пустые теги, можно заменить .* на .+. Плюсик означает любое количество символов, но не меньше одного.
Uis — модификаторы. U означает работу с UTF-8, i — регистронезависимый поиск, s — что символ точка включает в себя переносы строк, т.е. поиск будет по всем строкам, а не по одной.
preg_split()
Функция preg_split() аналогична split() за одним исключением — параметр шаблон может содержать регулярное выражение.
Синтаксис функции preg_split():
array preg_split(string шаблон, string строка ])
Необязательный параметр порог определяет максимальное количество элементов, на которые делится строка. В следующем примере функция preg_split() используется для выборки информации из переменной.
$user_info="+wj+++Gilmore+++++wjgi]more@hotmail.com+++++++Columbus+++OH";
$fields = preg_split("/\+{1.}/", $user_info);
while($x < sizeof($fields)):
print $fields. "<br>";
$x++;
endwhile;
Результат:
WJ Gilmore wjgilmore@hotmail.com Columbus OH
Повторения (квантификаторы)
Комбинация типа означает, что цифра должна повторяться два раза. Но бывают задачи, когда повторений очень много или мы не знаем, сколько именно. В таких члучаях нужно использовать специальные метасимволы.
Повторения символов или комбинаций описываются с помощью квантификаторов (метасимволов, которые задают количественные отношения). Есть два типа квантификаторов: общие (задаются с помощью фигурных скобок ) и сокращенные (сокращения наиболее распространенных квантификаторов). Фигурные скобки задают число повторений предыдущего символа (в этом случае выражение ищет от 1 до 7 идущих подряд букв «x»).
| Квантификатор | Описанте |
|---|---|
| a+ | Один и более раз a |
| a* | Ноль и более раз a |
| a? | Одна a или пусто |
| a{3} | 3 раза a |
| a{3,5} | От 3 до 5 раз a |
| a{3,} | 3 и более раз a |
Примечание: Если в выражении требуется поиск одного из метасимволов, вы можете использовать обратный слэш . Например, для поиска одного или нескольких вопросительных знаков можно использовать следующее выражение:
Что такое регулярные выражения PHP?
PHP regexp — это мощный алгоритм сопоставления шаблонов, которое может быть выполнено в одном выражении. Регулярные выражения PHP используют арифметические операторы (такие как +, -, ^) для создания сложных выражений.
Для чего используются регулярные выражения:
- Регулярные выражения упрощают идентификацию строковых данных путем вызова одной функции. Это экономит время при составлении кода;
- При проверке введенных пользователем данных, таких как адрес электронной почты, домен сайта, номер телефона, IP-адрес;
- Выделение ключевых слов в результатах поиска;
- Регулярные выражения могут использоваться для идентификации тегов и их замены.
«Петя любит Дашу».replace(/Дашу|Машу|Сашу/, «Катю») ¶
Не трудно догадаться, что результатом работы js-выражения выше будет текст . Даже, если Петя неровно дышит к Маше или Саше, то результат всё равно не изменится.
Рассмотрим базовые спец. символы, которые можно использовать в шаблонах:
| Символ | Описание | Пример использования | Результат |
|---|---|---|---|
| \ | Символ экранирования или начала мета-символа | /путь\/к\/папке/ | Надёт текст |
| ^ | Признак начала строки | /^Дом/ | Найдёт все строки, которые начинаются на |
| $ | Признак конца строки | /родной$/ | Найдёт все строки, которые заканчиваются на |
| . | Точка означает любой символ, кроме перевода строки | /Петя ..бит Машу/ | Найдёт как , так и |
| | | Означает ИЛИ | /Вася|Петя/ | Найдёт как Васю, так и Петю |
| ? | Означает НОЛЬ или ОДИН раз | /Вжу?х/ | Найдёт и |
| * | Означает НОЛЬ или МНОГО раз | /Вжу*х/ | Найдёт , , , и т.д. |
| + | Означает ОДИН или МНОГО раз | /Вжу+х/ | Найдёт , , и т.д. |
Помимо базовых спец. символов есть мета-символы (или мета-последовательности), которые заменяют группы символов:
| Символ | Описание | Пример использования | Результат |
|---|---|---|---|
| \w | Буква, цифра или _ (подчёркивание) | /^\w+$/ | Соответствует целому слову без пробелов, например |
| \W | НЕ буква, цифра или _ (подчёркивание) | /\W\w+\W/ | Найдёт полное слово, которое обрамлено любыми символами, например |
| \d | Любая цифра | /^\d+$/ | Соответствует целому числу без знака, например |
| \D | Любой символ НЕ цифра | /^\D+$/ | Соответствует любому выражению, где нет цифр, например |
| \s | Пробел или табуляция (кроме перевода строки) | /\s+/ | Найдёт последовательность пробелов от одного и до бесконечности |
| \S | Любой символ, кроме пробела или табуляции | /\s+\S/ | Найдёт последовательность пробелов, после которой есть хотя бы один другой символ |
| \b | Граница слова | /\bдом\b/ | Найдёт только отдельные слова , но проигнорирует |
| \B | НЕ граница слова | /\Bдом\b/ | Найдёт только окночние слов, которые заканчиваются на |
| \R | Любой перевод строки (Unix, Mac, Windows) | /.*\R/ | Найдёт строки, которые заканчиваются переводом строки |
Нужно отметить, что спец. символы \w, \W, \b и \B не работают по умолчанию с юникодом (включая кириллицу). Для их правильной работы нужно указывать модификатор . К сожалению, на окончание 2019 года JavaScript не поддерживает регулярные выражения для юникода даже с модификатором, поэтому в js эти мета-символы работают только для латиницы.
Ещё регулярные выражения поддерживают разные виды скобочек:
| Выражение | Описание | Пример использования | Результат |
|---|---|---|---|
| (…) | Круглые скобки означают под-шаблон, который идёт в результат поиска | /(Петя|Вася|Саша) любит Машу/ | Найдёт всю строку и запишет воздыхателя Маши в результат поиска под номером 1 |
| (?:…) | Круглые скобки с вопросом и двоеточием означают под-шаблон, который НЕ идёт в результат поиска | /(?:Петя|Вася|Саша) любит Машу/ | Найдёт только полную строку, воздыхатель останется инкогнито |
| (?P<name>…) | Задаёт имя под-шаблона | /(?P<воздыхатель>Петя|Вася|Саша) любит Машу/ | Найдёт полную строку, а воздыхателя запишет в результат под индексом 1 и ‘воздыхатель’ |
| Квадратные скобки задают ЛЮБОЙ СИМВОЛ из последовательности (включая спец. символы \w, \d, \s и т.д.) | /^+$/ | Соответствует любому выражению , но не | |
| Если внутри квадратных скобок указать минус, то это считается диапазоном | /+/ | Аналог /\w/ui для JavaScript | |
| Если минус является первым или последним символом диапазона, то это просто минус | /+/ | Найдёт любое целое числое с плюсом или минусом (причём не обязательно, чтобы минус или плюс были спереди) | |
| Квадратные скобки с «крышечекой» означают любой символ НЕ входящий в диапазон | //i | Найдёт любой символ, который не является буквой, числом или пробелом | |
| ] | Квадратные скобки в квадратных скобках задают класс символов (alnum, alpha, ascii, digit, print, space, punct и другие) | /]+/ | Найдёт последовательность непечатаемых символов |
| {n} | Фигурные скобки с одним числом задают точное количество символов | /\w+н{2}\w+/u | Найдёт слово, в котором две буквы н |
| {n,k} | Фигурные скобки с двумя числами задают количество символов от n до k | /\w+н{1,2}\w+/u | Найдёт слово, в котором есть одна или две буквы н |
| {n,} | Фигурные скобки с одним числом и запятой задают количество символов от n до бесконечности | /\w+н{3,}\w+/u | Найдёт слово, в котором н встречается от трёх и более раз подряд |
Задачки (пока без картинок)
- На вход скрипта дан введенный пользователем номер телефона в
виде 8-911-404-44-11 или +7(812)6786767 (в начале 8 или +7, потом идут 10 цифр и, возможно, какие-то символы).
То есть, как и в прошлой задаче, человек вводит номер как хочет.
Надо проверить номер на правильность и привести любой номер к единому формату 89114044411
(то есть, заменить +7 на 8 и выкинуть весь мусор вроде пробелов, скобок и минусов, кроме цифр) - Автозамена. Напиши скрипт, заменяющий определенное слово на другое (например, слово
«дурак» на «хороший человек» в фразе «ты дурак»). Скрипт должен не пропускать слово,
если оно написано буквами в разном регистре (ДуРАк), с заменой русских букв
на похожие английские (а -> a), или через пробелы («ты — д у р а к») - Дан текст, содержащий в себе email’ы (адреса почты вроде you+me@some.domain-domain.com ). Напиши
скрипт, выводящий все email, встречающиеся в этом тексте - «Grammar Nazi». Напиши скрипт, проверяющий текст на наличие злостных ошибок:
- нет пробела после запятой, точки с запятой, восклицательного знака,
вопросительного знака, двоеточия - «жи» или «ши» написано с буквой ы
- в тексте есть слово «координально» или «сдесь», «зделал», «зделаю», «зделан»
- в тексте есть слова «а» или «но» без запятой перед ними.
- (можешь добавить еще несколько правил, если хорошо знаешь русский язык)
В случае обнаружения ошибки скрипт должен писать сообщение об этом и выводить
кусок текста с ошибкой (чтобы было понятно, что не так). - нет пробела после запятой, точки с запятой, восклицательного знака,
- Если ты сделал задачу про Grammar Nazi, сделай скрипт, которы вместо сообщения об ошибках будет
молча их исправлять.
Основы основ
Для начала нужно понять что в Regex есть специальные символы (например символ начала строки — ), если вы хотите просто найти данный символ, то нужно ввести обратный слеш перед символом для того, чтобы символ не работал как команда.
Для того чтобы найти текст, нужно собственно просто ввести этот текст:
Якори
— символ который обозначает начало строки
— символ который обозначает конец строки
Найдем строки которые начинаются с The Beginning:
Найдем строки, которые заканчиваются на The End:
Найдем строки, которые начинаются и заканчиваются на The Beginning and The End:
Найдем пустые строки:
Квантификаторы
— символ, который указывает на то, что выражение до него должно встретиться 0 или 1 раз
— символ, который указывает на то, что выражение до него должно встретиться один или больше раз
— символ, который указывает на то, что выражение до него должно встретиться 0 или неопределённое количество раз
— скобки с одним аргументом указывают сколько раз выражение до них должно встретиться
— скобки с двумя аргументами указывают на то, от скольки до скольки раз выражение до них должно встретиться
— скобки объединяют какое-то предложение в выражение. Обычно используется в связке с квантификаторами
Давайте попробуем найти текст, в котором будут искаться все слова, содержащие ext или ex:
Давайте попробуем найти текст, в котором слова будут содержать ext или e:
Найти все размеры одежды (XL, XXL, XXXL):
Найти все слова, у которых есть неограниченное число символов c, после которых идёт haracter:
Найти выражение, в котором слово word повторяется от одного до неограниченного количества раз:
Найти выражение, в котором выражение ch повторяется от 3 до неограниченного количества раз:
Выражение «или»
— символ, который обозначает оператор «или»
— выражение в квадратных скобках ставит или между каждым подвыражением
Найти все слова, в которых есть буквы a,e,c,h,p:
Найти все выражения в которых есть ch или pa:
Escape-последовательности
— отмечает один символ, который является цифрой (digit)\
— отмечает символ, который не является цифрой
— отмечает любой символ (число или букву (или подчёркивание)) (word)
— отмечает любой пробельный символ (space character)
— отмечает любой символ (один)
Выражения в квадратных скобках
Кроме того, что квадратные скобки служат оператором «или» между каждым символом, который в них заключён, они также могут служить и для некоторых перечислений:
— один символ от 0 до 9
— любой символ от a до z
— любой символ от A до Z
— любой символ кроме a — z
Найти все выражения, в которых есть английские буквы в нижнем регистре или цифры:
Флаги
Флаги — символы (набор символов), которые отвечают за то, каким именно образом будет происходить поиск.
Форма условия поиска в Regex выглядит вот так:
— флаг, который будет отмечать все выражения, которые соответствуют условиям поиска (по умолчанию поиск возвращает только первое выражение, которое подходит по условию) (global)
— флаг, который заставляет искать выражения вне зависимости от региста (case insensitive)
Теперь вы знаете базовые знания по Regex и можете использовать их в языках программирования, консольных утилитах или в программируемых редакторах (привет, Vim). Если вам интересен данный материал, а также интересны темы веб-разработки и администрирования Unix-подобных систем, то вы можете подписаться на мой телеграм-канал, там много всякого разного и полезного.
Специальные конструкции в регулярках
-
ищет одну любую цифру, — один
любой символ, кроме цифры -
соответствует одной любой букве (любого алфавита), цифре
или знаку подчеркивания . соответствует
любому символу, кроме буквы, цифры, знака подчеркивания.
Также, есть удобное условие для указания на границу слова: .
Эта конструкция обозначает, что с одной стороны от нее должен стоять символ,
являющийся буквой/цифрой/знаком подчеркивания (), а с
другой стороны — не являющийся. Ну, например, мы хотим найти в тексте слово
«кот». Если мы напишем регулярку , то она
найдет последовательность этих букв в любом месте — например, внутри слова
«скотина». Это явно не то, что мы хотели. Если же мы добавим
условие границы слова в регулярку: , то теперь
искаться будет только отдельно стоящее слово «кот».
Скобки в регулярных выражениях
Давай повторим, что обозначают разные виды скобок:
- Фигурные скобки задают число повторений предыдущего
символа — в этом примере выражение ищет от 1 до 5 идущих подряд
букв «a» - Квадратные скобки означают «один любой из
этих символов», в данном случае — буквы a, b, c, x, y, z или
цифра от 0 до 5. Внутри квадратных скобок не работают другие спецсимволы
вроде или — они обозначают обычный символ. Если
в квадратных скобках в начале стоит символ то смысл меняется
на противоположный: «любой один символ, кроме указанных» —
например значит «один любой символ,
кроме a, b или c». - Круглые скобки группируют символы и выражения. Например в
выражении знак «плюс» относится только
к букве c и это выражение ищет слова вроде abc, abcc, abccc. А если
поставить скобки то квантифиактор плюс относится
уже к последовательности и выражение ищет слова
abc, abcbc, abcbcbc
Примечание: в квадратных скобках можно указывать диапазоны
символов, но помни, что русская буква ё идет отдельно от
алфавита и чтобы написать «любая русская буква»,
надо писать .
Регулярные выражения PHP
PHP содержит встроенные функции, которые позволяют работать с регулярными выражениями. Теперь рассмотрим часто используемые функции регулярных выражений PHP.
- preg_match — используется для выполнения сопоставления с шаблоном строки. Она возвращает true, если совпадение найдено, и false, если совпадение не найдено;
- preg_split — используется для разбивки строки по шаблону, результат возвращается в виде числового массива;
- preg_replace – используется для поиска по шаблону и замены на указанную строку.
Ниже приведен синтаксис функций регулярных выражений, таких как preg_match, preg_split или PHP regexp replace:
<?php
имя_функции('/шаблон/',объект);
?>
, где
«имя_функции» — это либо preg_match, либо preg_split, либо preg_replace.«/…/» — косые черты обозначают начало и конец регулярного выражения.«‘/шаблон/’» — шаблон, который нам нужно сопоставить.«объект» — строка, с которой нужно сопоставлять шаблон.
Теперь рассмотрим практические примеры использования упомянутых выше функций.
Preg match PHP
В первом примере функция preg_match используется для выполнения простого сопоставления шаблоном для слова guru в заданном URL-адресе.
В приведенном ниже коде показан вариант реализации данного примера:
<?php
$my_url = "www.guru99.com";
if (preg_match("/guru/", $my_url))
{
echo "the url $my_url contains guru";
}
else
{
echo "the url $my_url does not contain guru";
}
?>
«preg_match (‘/ guru /’, $ my_url)»
Здесь:
«preg_match(…)» — функция PHP match regexp.«‘/Guru/’» — шаблон регулярного выражения.«$My_url» — переменная, содержащая текст, с которым нужно сопоставить шаблон.
Preg split PHP
Рассмотрим другой пример, в котором используется функция preg_split.
Мы возьмем фразу и разобьем ее на массив; шаблон предназначен для поиска единичного пробела:
<?php $my_text="I Love Regular Expressions"; $my_array = preg_split("/ /", $my_text); print_r($my_array ); ?>
Preg replace PHP
Рассмотрим функцию preg_replace, которая выполняет сопоставление с шаблоном и заменяет найденный результат другой строкой.
Приведенный ниже код ищет в строке слово guru. Он заменяет его кодом css, который задает цвет фона:
<?php
$text = "We at Guru99 strive to make quality education affordable to the masses. Guru99.com";
$text = preg_replace("/Guru/", '<span style="background:yellow">Guru</span>', $text);
echo $text;
?>
Опережающие и ретроспективные проверки — (?=) and (?
d(?=r) соответствует d, только если после этого следует r, но r не будет входить в соответствие выражения -> тест(?<=r)d соответствует d, только если перед этим есть r, но r не будет входить в соответствие выражения -> тест
Вы можете использовать оператор отрицания !
d(?!r) соответствует d, только если после этого нет r, но r не будет входить в соответствие выражения -> тест(?<!r)d соответствует d, только если перед этим нет r, но r не будет входить в соответствие выражения -> тест
Заключение
Как вы могли убедиться, области применения регулярных выражений разнообразны. Я уверен, что вы сталкивались с похожими задачами в своей работе (хотя бы с одной из них), например такими:
- Валидация данных (например, правильно ли заполнена строка time)
- Сбор данных (особенно веб-скрапинг, поиск страниц, содержащих определённый набор слов в определённом порядке)
- Обработка данных (преобразование сырых данных в нужный формат)
- Парсинг (например, достать все GET параметры из URL или текст внутри скобок)
- Замена строк (даже во время написания кода в IDE, можно, например преобразовать Java или C# класс в соответствующий JSON объект, заменить “;” на “,”, изменить размер букв, избегать объявление типа и т.д.)
- Подсветка синтаксиса, переименование файла, анализ пакетов и многие другие задачи, где нужно работать со строками (где данные не должны быть текстовыми).
Перевод статьи Jonny Fox: Regex tutorial — A quick cheatsheet by examples
Примеры шаблонов
Начнем с пары простых примеров. Первое выражение на картинке ниже ищет
последовательность из 3 букв, где первая буква это «к», вторая — любая русская буква и
третья — это «т» без учета регистра (например, «кот» или «КОТ» подходит
под этот шаблон). Второе выражение ищет в тексте время в формате .

Любое выражение начинается с символа-ограничителя (delimiter по англ.). В качестве
него обычно используют символ , но можно использовать и другие
символы, не имеющие специального назначения в регулярках, например, ,
или . Альтернативные разделители используют, если в
выражении может встречаться символ . Затем идет сам шаблон строки,
которую мы ищем, за
ним второй ограничитель и в конце может идти одна или несколько букв-флагов. Они
задают дополнительные опции при поиске текста. Вот примеры флагов:
-
— говорит, что поиск должен вестись без учета
регистра букв (по умолчанию регистр учитывается) -
— говорит, что выражение и текст, по которому идет поиск,
исплоьзуют кодировку utf-8, а не только латинские буквы. Без него поиск
русских (и любых других нелатинских) символов может работать некорректно,
потому стоит ставить его всегда.
Сам шаблон состоит из обычных символов и специальных конструкций. Ну
например, буква «к» в регулярках обозначает саму себя, а вот символы
значат «в этом месте может быть любая цифра от 0 до 5». Вот полный список
специальных символов (в мануале php их называют метасимволы),
а все остальные символы в регулярке — обычные:
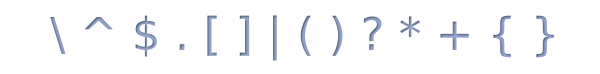
Ниже мы разберем значение каждого из этих символов (а также объясним почему буква
«ё» вынесена отдельно в первом выражении), а пока попробуем
применить наши регулярки к тексту и посмотреть, что выйдет. В php есть
специальная функция ,
которая принимает на вход регулярку, текст и пустой массив. Она проверяет,
есть ли в тексте подстрока, соответствующая данному шаблону и возвращает
, если нет,
или , если она есть. А в переданный массив в элемент с индексом
0 кладется первое найденное совпадение с регуляркой. Напишем простую
программу, применяющую регулярные выражения к разным строкам:
| Код | Результат |
|---|---|
Строка: рыжий кот + Найдено слово 'кот' Строка: рыжий крот - Ничего не найдено Строка: кит и кот + Найдено слово 'кит' |
Познакомившись с примером, изучим регулярные выражения более подробно.


Кванторы
Частоту или положение заключенных в скобки символьных последовательностей и одиночных символов можно обозначить специальным символом. Каждый особый персонаж имеет конкретную коннотацию. +, * ,? , {int. range} и $ flags следуют за символьной последовательностью.
| # | Значение | Описание |
|---|---|---|
| р + | Он соответствует любой строке, содержащей хотя бы один p. | |
| п* | Он соответствует любой строке, содержащей ноль или более p. | |
| p ? | Он соответствует любой строке, содержащей ноль или более p. Это просто альтернативный способ использования p *. | |
| р {N} | Он соответствует любой строке, содержащей последовательность из N p | |
| р {2,3} | Он соответствует любой строке, содержащей последовательность из двух или трех p. | |
| p {2,} | Он соответствует любой строке, содержащей последовательность не менее двух p. | |
| р $ | Он соответствует любой строке с p в конце ее. | |
| ^ р | Он соответствует любой строке с p в начале ее. |
Примеры
Следующие примеры дают понятия о совпадении символов.
| Значение | Описание |
|---|---|
| Он соответствует любой строке, не содержащей ни одного символа в диапазоне от a до z и от A до Z. | |
| p.p | Он соответствует любой строке, содержащей p, за которой следует любой символ, в свою очередь, за которым следует другой p. |
| ^. {2} $ | Он соответствует любой строке, содержащей ровно два символа. |
| (.*). | Он соответствует любой строке, заключенной внутри b и / b. |
| p ( hp ) * | Он соответствует любой строке, содержащей ap, а затем ноль или более экземпляров последовательности php. |
Практические примеры сложных регулярных выражений
Теперь, когда вы знаете теорию и основной синтаксис регулярных выражений в PHP, пришло время создать и проанализировать некоторые более сложные примеры.
1) Проверка имени пользователя с помощью регулярного выражения
Начнем с проверки имени пользователя. Если у вас есть форма регистрации, вам понадобится проверять на правильность имена пользователей. Предположим, вы не хотите, чтобы в имени были какие-либо специальные символы, кроме «» и, конечно, имя должно содержать буквы и возможно цифры. Кроме того, вам может понадобиться контролировать длину имени пользователя, например от 4 до 20 символов.
Сначала нам нужно определить доступные символы. Это можно реализовать с помощью следующего кода:
После этого нам нужно ограничить количество символов следующим кодом:
{4,20}
Теперь собираем это регулярное выражение вместе:
^{4,20}$
В случае Perl-совместимого регулярного выражения заключите его символами ‘‘. Итоговый PHP-код выглядит так:
<?php
$pattern = '/^{4,20}$/';
$username = "demo_user-123";
if (preg_match($pattern, $username)) {
echo "Проверка пройдена успешно!";
} else {
echo "Проверка не пройдена!";
}
?>
2) Проверка шестнадцатеричного кода цвета регулярным выражением
Шестнадцатеричный код цвета выглядит так: , также допустимо использование краткой формы, например . В обоих случаях код цвета начинается с и затем идут ровно 3 или 6 цифр или букв от a до f.
Итак, проверяем начало кода:
^#
Затем проверяем диапазон допустимых символов:
После этого проверяем допустимую длину кода (она может быть либо 3, либо 6). Полный код регулярного выражения выйдет следующим:
^#(({3}$)|({6}$))
Здесь мы используем логический оператор, чтобы сначала проверить код вида , а затем код вида . Итоговый PHP-код проверки регулярным выражением выглядит так:
<?php
$pattern = '/^#(({3}$)|({6}$))/';
$color = "#1AA";
if (preg_match($pattern, $color)) {
echo "Проверка пройдена успешно!";
} else {
echo "Проверка не пройдена!";
}
?>
3) Проверка электронной почты клиента с использованием регулярного выражения
Теперь давайте посмотрим, как мы можем проверить адрес электронной почты с помощью регулярных выражений. Сначала внимательно рассмотрите следующие примеры адресов почты:
john.doe@test.com john@demo.ua john_123.doe@test.info
Как мы можем видеть, символ является обязательным элементом в адресе электронной почты. Помимо этого должен быть какой-то набор символов до и после этого элемента. Точнее, после него должно идти допустимое доменное имя.
Таким образом, первая часть должна быть строкой с буквами, цифрами или некоторыми специальными символами, такими как . В шаблоне мы можем написать это следующим образом:
^+
Доменное имя всегда имеет, скажем, имя и tld (top-level domain) – т.е, доменную зону. Доменная зона – это , , и тому подобное. Это означает, что шаблон регулярного выражения для домена будет выглядеть так:
+\.{2,5}$
Теперь, если мы соберем все в кучу, то получим полный шаблон регулярного выражения для проверки адреса электронной почты:
^+@+\.{2,5}$
В коде PHP эта проверка будет выглядеть следующим образом:
<?php
$pattern = '/^+@+\.{2,5}$/';
$email = "john_123.doe@test.info";
if (preg_match($pattern, $email)) {
echo "Проверка пройдена успешно!";
} else {
echo "Проверка не пройдена!";
}
?>
Надеемся, что сегодняшняя статья помогла вам при знакомстве с регулярными выражениями в PHP, а практические примеры пригодятся вам при использовании регулярных выражений в собственных PHP скриптах.
-
3204
-
35
-
Опубликовано 16/04/2019
-
PHP, Уроки программирования