Продвинутое использование robots.txt без ошибок
Содержание:
Настройка оформления страницы техобслуживания
На вкладке «Дизайн» мы можем изменять внешний вид страницы технического обслуживания на которую попадают посетители сайта.
Здесь вы, прежде всего, вы можете изменить текст, который высвечивается на странице техобслуживания. Изменить тег title, заголовок страницы и ввести сюда какой-то свой текст. Так же, вы можете выбирать здесь цвет шрифта заголовка, текст шрифта основного текста, выбирать фон, загружать какое-то изображение в качестве фона.

После того, как вы зададите все эти настройки вам, конечно же, нужно нажать на кнопку «Сохранить настройки».
На вкладке «Mодули» у вас есть возможность добавить различные дополнительные элементы на страницу технического обслуживания. Например, такие как таймер обратного отсчета.
Для того, что бы это сделать в поле «Показывать обратный отсчет» выбираем «Да». Далее, выставляете определенную дату, либо часы, для обратного отсчета времени. Так же, здесь выбирается цвет для таймера. Для того, что бы он отобразился, нужно будет сохранить изменения.

Помимо таймера, здесь можно так же добавить поле «Подписаться». Для этого , так же, выбираем пункт «Да». Далее задаём в поле «Текст» пишем какой-то свой текст и выбираем для него цвет.


Здесь же можно выбрать, использовать Google Analytics или нет для страницы данного сайта, и если использовать, то вам здесь нужно будет вставить код отслеживания. После того как вы все задали, нажимаете на кнопку «Сохранить настройки».

Не смотря на то, что данный плагин очень много настроек, для того, что бы просто включить режим техобслуживания и запретить посетителям доступ к вашему сайту достаточно просто установить данный плагин, перейти в его настройки, поставить статус включено и нажать на кнопку «Сохранить настройки».
После того, как вы выполнили все необходимые манипуляции с вашим сайтом, не забудьте отключить режим технического обслуживания.
Так же, после того как вы отключили режим техобслуживания можно и вовсе деактивировать данный плагин. Затем, если понадобится, вы его снова активируете и включите режим обслуживания.
Способ 1. Создать файл Site Closed
Способ подразумевает кастомизацию стандартной заглушки, которая включается в главном модуле, кнопкой “Закрыть публичную часть сайта”.
Стандартная заглушка заменяется посредством создания файла site_closed.php в «/bitrix/php_interface/include» или «/local/php_interface/include».
Такая заглушка — обычная страница, поэтому размещенные на ней компоненты тоже будут работать. В то же время страница может быть собрана в
и никак не связана с дизайном сайта.
А такую заглушку мы используем на наших проектах. Если вам понравилась эта заглушка, то не пропустите — в конце статьи будет ссылка на скачивание.
Используемые директивы
User-agent
Все блоки правил начинаются с директивы User-agent, в которой указывается название робота, для которого задается правило. Запись вида User-agent: * означает, что правило задается для всех поисковых роботов.
Например, при следующей записи правило будет применено только к основному индексирующему боту Яндекса:
User-agent: YandexBot
Правило будет применено ко всем роботам Яндекса и Google:
User-agent: Yandex User-agent: Googlebot
Правило будет применено вообще ко всем роботам:
User-agent: *
Disallow и Allow
Директивы используются, чтобы запретить и разрешить доступ к определенным разделам сайта.
Например, можно запретить индексацию всего сайта (Disallow: /), кроме определенного каталога (Allow: /catalog):
User-agent: имя_бота Disallow: / Allow: /catalog
Запретить индексацию страниц, начинающихся с /catalog, но разрешить для страниц, начинающихся с /catalog/auto и /catalog/new:
User-agent: имя_бота Disallow: /catalog Allow: /catalog/auto Allow: /catalog/new
В каждой строке указывается только одна директория. Для запрещения (или разрешения) доступа к нескольким каталогам, для каждого требуется отдельная запись.
С помощью Disallow можно ограничить доступ к сайту для нежелательных ботов, тем самым снизив создаваемую ими нагрузку. Например, чтобы запретить доступ ко всему сайту для MJ12bot и AhrefsBot — ботов сервиса majestic.com и ahrefs.com — используйте:
User-agent: MJ12bot User-agent: AhrefsBot Disallow: /
Аналогичным образом устанавливается блокировка и для других ботов (скажем, DotBot, SemrushBot и других).
Примечания:
- Пустая директива Disallow: равнозначна Allow: /, то есть «не запрещать ничего».
- В директивах может использоваться символ $ для обозначения точного соответствия указанному параметру. Например, запись Disallow: /catalog аналогична Disallow: /catalog * и запретит доступ ко всем страницам с /catalog (/catalog, /catalog1, /catalog-new, /catalog/clothes и др.).Использование $ это изменит. Disallow: /catalog$ запретит доступ к /catalog, но разрешит /catalog1, /catalog-new, /catalog/clothes и др.
Sitemap
При использовании файла sitemap.xml для описания структуры сайта, можно указать путь к нему с помощью соответствующей директивы:
User-agent: * Disallow: Sitemap: https://mydomain.com/путь_к_файлу/mysitemap.xml
Можно перечислить несколько файлов Sitemap, каждый в отдельной строке.
Host
Директива используется для указания роботам Яндекса основного зеркала сайта и полезна, когда сайт доступен по нескольким доменам.
User-agent: Yandex Disallow: /catalog1$ Host: https://mydomain.com
Примечания:
- Директива Host может быть только одна; если в файле указано несколько, роботом будет учтена только первая.
- Необходимо указывать протокол https, если он используется. Если вы используете http, зеркало можно записать в виде mydomain.com
- Для корректного прочтения директивы, ее нужно указывать в блоке правил User-agent после директив Disallow и Allow.
Crawl-delay
Директива устанавливает минимальный интервал в секундах между обращениями робота к сайту, что может быть полезно для снижения создаваемой роботами нагрузки. Чем выше указанное значение, тем меньше страниц робот загрузит за сессию.
Значения можно указывать целыми или дробными числами (разделитель — точка).
User-agent: Yandex Disallow: Crawl-delay: 0.5
Примечания:
- Для корректного прочтения директивы, ее нужно указывать в блоке правил User-agent после директив Disallow и Allow.
Clean-param
Директива используется для робота Яндекса. Она позволяет исключить из индексации страницы с динамическими параметрами в URL-адресах (это могут быть идентификаторы сессий, пользователей, рефереров), чтобы робот не индексировал одно и то же содержимое повторно, повышая тем самым нагрузку на сервер.
Например, на сайте есть страницы:
www.mydomain.ru/news.html?&parm1=1&parm2=2 www.mydomain.ru/news.html?&parm2=2&parm3=3
По факту по обоим адресам отдается одна и та же страница — www.mydomain.ru/news.html, при этом в URL присутствуют дополнительные динамические параметры.
Чтобы робот не индексировал каждую подобную страницу, можно использовать директиву:
User-agent: Yandex Disallow: Clean-param: parm1&parm2&parm3 /news.html
Через знак & указываются параметры, которые робот должен игнорировать. Далее указывается страница, для которой применяется данное правило
Как в Битрикс закрыть сайт от индексации
Для этого нужно использовать метатег <meta name=»robots» content=»noindex, nofollow»>. Для скрытия какой-либо страницы от индексирования нужно, добавляя или изменяя условия, выбрать пункт «Закрыть от индексации».

Кроме того, возможно отключение индексации всех страниц с подключенным компонентом sotbit:seo.meta. Для этого нужно зайти в общие настройки модуля SEO умного фильтра и включить опцию «Отключить индексацию всех страниц».
Приоритетными будут настройки индексации в условии, а не эта опция. То есть в случае отключения в настройках условия опции «Закрыть от индексации» страница, удовлетворяющая этому условию, будет проиндексирована.
Настройка файла robots.txt: основные директивы
Чтобы правильно настроить файл robots.txt, необходимо знать директивы – команды, которые воспринимают роботы поисковых систем. Ниже рассмотрим основные директивы для настройки индексации сайта в файле robots.txt:
| Директива | Назначение |
| User-agent: | Указывает робота поисковой системы, для которого предназначены команды ниже. Названия роботов можно посмотреть в справочной информации, которую предоставляют поисковые системы. |
Директива User-agent: * обозначает, что команды ниже предназначены для всех роботов, для которых нет персональных команд в файле.
Важно соблюдать последовательность команд в файле. В начале прописываются команды для конкретных роботов (Yandex, Googlebot и т.д.), потом – для всех остальных.. Существуют другие директивы, которые используется реже
Посмотреть информацию обо всех директивах, которые можно настроить в файле robots.txt, можно здесь
Disallow:
Данная директива в файле robots.txt закрывает индексацию определенной страницы или раздела на сайте. Сама страница или раздел указываются от корневой папки сайта, без домена (см. скриншот в начале статьи).
Allow:
Разрешает индексацию определенной страницы или раздела на сайте. Директивы Allow необходимо располагать ниже директив Disallow.
Host:
Указывает главное зеркало сайта (либо с www, либо без www). Учитывается только Яндексом.
Sitemap:
В данной директиве необходимо прописать путь к карте сайта, если она имеется на сайте.
Существуют другие директивы, которые используется реже. Посмотреть информацию обо всех директивах, которые можно настроить в файле robots.txt, можно здесь.
Частные случаи команд в файле robots.txt
Разберем некоторые команды, которые потребуются Вам в работе:
| Команда | Что обозначает |
| User-agent: Yandex | Начало блока команд для основного робота поисковой системы Яндекс. |
| User-agent: Googlebot | Начало блока команд для основного робота поисковой системы Google. |
| User-agent: *Disallow: / | Данная команда в файле robots.txt полностью закрывает сайт от индексации всеми поисковыми системами. |
| User-agent: *Disallow: /Allow: /test.html | Данные команды закрывают все документы на сайте от индексации, кроме страницы /test.html |
| Disallow: /*.doc | Данная команда запрещает индексировать файлы MS Word на сайте. Если на сайте содержится конфиденциальная информация в файлах определенного типа, имеет смысл закрыть такие файлы от индексации. |
| Disallow: /*.pdf | Данная команда в robots.txt запрещает индексировать на сайте файлы в формате PDF. Если Вы выкладываете на сайте какие-либо файлы, доступные для скачивания после оплаты или после авторизации, имеет смысл закрыть их от индексации. В ином случае данные файлы смогут найти в поисковых системах. |
| Disallow: /basket/ | Команда запрещает индексировать все документы в разделе /basket/. |
| Host: www.yandex.ru | Команда задает для сайта yandex.ru основным зеркалом адрес сайта с www. Соответственно, в поиске с высокой вероятностью будут выводиться адреса страниц с www. |
| Host: yandex.ru | Данная команда задает для сайта yandex.ru в качестве основного зеркала адрес yandex.ru (без www). |
Спортивная ходьба по граблям
Сразу оговоримся: мы против пиратства в сети. Нелегальное распространение и скачивание любого авторского контента не только незаконно, но и недостойно честного человека. Увы, с появлением электронных носителей информации пиратство стало неизбежным злом. Бороться с ним необходимо. Вопрос лишь в адекватности и эффективности тех или иных мер.
В январе 2016 года РКН заблокировал портал RuTracker, крупнейший российский каталог торрент-ссылок на мультимедийный контент. Несмотря на это, сайт продолжает работу — ведь для многих пользователей обход блокировки несложен. Закон предписывает блокировать ресурсы только провайдерам; если же пользователь находит способ обхода блокировки, чтобы получить доступ к закрытой информации, формально он не нарушает закон.
Более того, если до блокировки владельцы RuTracker охотно шли навстречу правообладателям и удаляли нелегальный контент по требованию владельцев, теперь это стало невозможно. Раз доступ к ресурсу в России заблокирован, значит нарушения нет. А тем временем миллионы пользователей получают доступ к пиратским фильмам и музыкальным альбомам.
Эпическая битва Роскомнадзора с Телеграмом, развернувшаяся в марте текущего года, до сих пор на слуху у публики. С Телеграмом РКН тоже пытался бороться блокировками (в данном случае речь шла не о борьбе с нелегальным контентом). В реестр запрещенных материалов были внесены миллионы сетевых адресов. Миллионы, Карл!
А что же Телеграм? Он продолжает работать, как ни в чем не бывало.
Казалось бы, эти ситуации должны были убедить российского законодателя и РКН, что блокировки — не идеальный способ перекрыть информационные потоки. Не то, чтобы они совсем не работали, просто их эффективность недостаточно высока.
Закрытие от индексации страниц сайта
Существует три способа закрытия от индексации страниц сайта:
- использование мета-тега «robots» (<meta name=»robots» content=»noindex,nofollow» />);
- создание корневого файла robots.txt;
- использование служебного файла сервера Apache.
Это не взаимоисключающие опции, чаще всего их используют вместе.
Закрыть сайт от индексации с помощью robots.txt
Файл robots.txt располагается в корне сайта и используется для управления индексированием сайта поисковыми роботами. С помощью набора инструкций можно разрешить либо запретить индексацию всего сайта, отдельных страниц, каталогов, страниц с параметрами (типа сортировки, фильтры и пр.). Его особенность в том, что в robots.txt можно прописать четкие указания для конкретного поискового робота (User-agent), будь то googlebot, YandexImages и т.д.
 Для того, чтобы обратиться сразу ко всем поисковым ботам, необходимо прописать диерективу «User-agent: *». В таком случае, поисковик прочитав весь файл и не найдя конкретных указаний для себя, будет следовать общей инструкции.
Для того, чтобы обратиться сразу ко всем поисковым ботам, необходимо прописать диерективу «User-agent: *». В таком случае, поисковик прочитав весь файл и не найдя конкретных указаний для себя, будет следовать общей инструкции.
Все о файле robots.txt и о том, как его правильно составить читайте здесь, а также рекомендации по использованию этого файла от Яндекс и .
Например, ниже приведен файл robots.txt для сайта «Розетки»:
Как видим, сайт закрыт от индексации для поисковой системы Yahoo!
Зачем закрывать сайт от поисковых систем?
Лучше всего Robots.txt использовать в таких случаях:
- при полном закрытии сайта от индексации во время его разработки;
- для закрытия сайта от нецелевых поисковых систем, как в случае с Розеткой, чтоб не нагружать «лишними» запросами свои сервера.
Во всех остальных случаях лучше использовать методы, описанные ниже.
Запрет индексации с помощью мeтa-тега «robots»
Meta-тег «robots» указывает поисковому роботу можно ли индексировать конкретную страницу и ссылки на странице. Отличие этого тега от файла robots.txt в том, что невозможно прописать отдельные директивы для каждого из поисковых ботов.
Есть 4 способа объяснить поисковику как индексировать данный url.
1. Индексировать и текст и ссылки
<meta name=»robots» content=»index, follow«> (используется по умолчанию) эквивалентна записи <META NAME=»Robots» CONTENT=»ALL»>
<meta name=»robots» content=»noindex, nofollow«>

3. Не индексировать на странице текст, но индексировать ссылки
<meta name=»robots» content=»noindex,follow«>
Такая запись означает, что данную страницу индексировать не надо, а следовать по ссылкам с данной страницы для изучения других страниц можно. Это бывает полезно при распределения внутреннего индекса цитирования (ВИЦ).
Что выбрать мета-тег «robots» или robots.txt?
Параллельное использование мeтa-тега «robots» и файла robots.txt дает реальные преимущества.
Дополнительная гарантия, что конкретная страница не будет проиндексирована. Но это все равно не застрахует вас от произвола поисковых систем, которые могут игнорировать обе директивы. Особенно любит пренебрегать правилами robots.txt Google, выдавая вот такие данные в SERP (страница с результатами поиска):
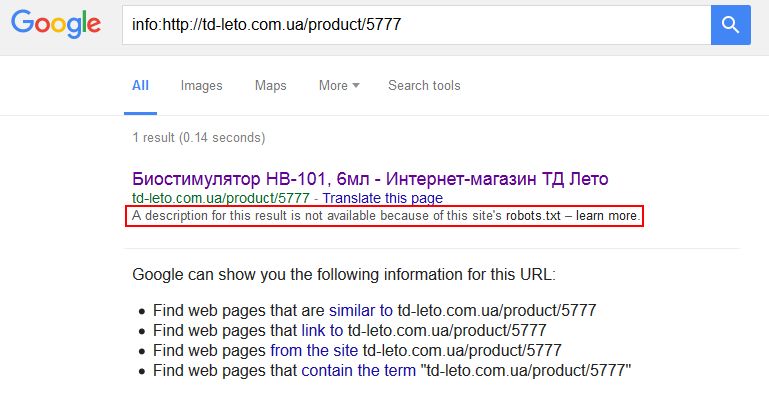
В случае, когда в robots.txt мы закрываем какой-то каталог, но определенные страницы из этого каталога нам все-таки нужны для индексации, мы можем использовать мета-тег «robots». Это же работает и в обратном порядке: в индексируемой папке (каталоге сайта) есть страницы, которые нужно запретить для индексации.
Вобщем, необходимо запомнить правило: мета-тег robots является преимущественным по сравнению с файлом robots.txt.
Подробнее об использовании мета-тегов читайте у Яндекса и .
Закрыть сайт от индексации с помощью .htaccess
.htaccess – это служебный файл веб-сервера Apache. Мэтт Каттс, бывший руководитель команды Google по борьбе с веб-спамом, утверждает, что использовать .htaccess для закрытия сайта от индексации – это самый лучший вариант и в видео рисует довольный смайлик.
С помощью регулярных выражений можно закрыть весь сайт, его части (разделы), ссылки, поддомены.
Описание robots.txt
Чтобы правильно написать robots.txt, предлагаем вам изучить разделы этого сайта. Здесь собрана самая полезная информация о синтаксисе robots.txt, о формате robots.txt, примеры использования, а также описание основных поисковых роботов Рунета.
- Как работать с robots.txt — узнайте, что вы можете сделать, чтобы управлять роботами, которые посещают ваш веб-сайт.
- Роботы Рунета — разделы по роботам поисковых систем, популярных на просторах Рунета.
- Частые ошибки в robots.txt — список наиболее частых ошибок, допускаемых при написании файла robots.txt.
- ЧаВо по веб-роботам — часто задаваемые вопросы о роботах от пользователей, авторов и разработчиков.
- Ссылки по теме — аналог оригинального раздела «WWW Robots Related Sites», но дополненый и расширенный, в основном по русскоязычной тематике.
Где размещать файл robots.txt
Робот просто запрашивает на вашем сайте URL «/robots.txt», сайт в данном случае – это определенный хост на определенном порту.
| URL Сайта | URL файла robots.txt |
| http://www.w3.org/ | http://www.w3.org/robots.txt |
| http://www.w3.org:80/ | http://www.w3.org:80/robots.txt |
| http://www.w3.org:1234/ | http://www.w3.org:1234/robots.txt |
| http://w3.org/ | http://w3.org/robots.txt |
На сайте может быть только один файл «/robots.txt». Например, не следует помещать файл robots.txt в пользовательские поддиректории – все равно роботы не будут их там искать. Если вы хотите иметь возможность создавать файлы robots.txt в поддиректориях, то вам нужен способ программно собирать их в один файл robots.txt, расположенный в корне сайта. Вместо этого можно использовать Мета-тег Robots.
Не забывайте, что URL-ы чувствительны к регистру, и название файла «/robots.txt» должно быть написано полностью в нижнем регистре.
| Неправильное расположение robots.txt | |
| http://www.w3.org/admin/robots.txt | Файл находится не в корне сайта |
| http://www.w3.org/~timbl/robots.txt | Файл находится не в корне сайта |
| ftp://ftp.w3.com/robots.txt | Роботы не индексируют ftp |
| http://www.w3.org/Robots.txt | Название файла не в нижнем регистре |
Как видите, файл robots.txt нужно класть исключительно в корень сайта.
Что писать в файл robots.txt
В файл robots.txt обычно пишут нечто вроде:
В этом примере запрещена индексация трех директорий.
Затметьте, что каждая директория указана на отдельной строке – нельзя написать «Disallow: /cgi-bin/ /tmp/». Нельзя также разбивать одну инструкцию Disallow или User-agent на несколько строк, т.к. перенос строки используется для отделения инструкций друг от друга.
Регулярные выражения и символы подстановки так же нельзя использовать. «Звездочка» (*) в инструкции User-agent означает «любой робот». Инструкции вида «Disallow: *.gif» или «User-agent: Ya*» не поддерживаются.
Конкретные инструкции в robots.txt зависят от вашего сайта и того, что вы захотите закрыть от индексации. Вот несколько примеров:
Запретить к индексации все файлы кроме одного
Это довольно непросто, т.к. не существует инструкции “Allow”. Вместо этого можно переместить все файлы кроме того, который вы хотите разрешить к индексации в поддиректорию и запретить ее индексацию:
Либо вы можете запретить все запрещенные к индексации файлы:
Юридические тонкости
Роскомнадзор требовал от Яндекса удалить ссылки на пиратский контент. Однако ни суд, ни РКН не смогли дать ясных рекомендаций, как отличить пиратскую копию файла от легальной. Ведь телеканал, владеющий правами на сериал, может выложить отдельные серии или ознакомительные фрагменты. При общем количестве ссылок на видеофайлы, исчисляющемся десятками тысяч, невозможно выявить среди них принадлежащие правообладателям. Ни Яндексу, ни другим поисковым системам не предложили механизмов, по которым можно было бы отделить пиратский контент от легального.
Есть радикальное решение: поисковая система может удалить все ссылки на тот или иной сериал (Яндекс именно так и поступил). Но в этом случае под раздачу попадут и вполне легальные ссылки. А значит, упадет посещаемость ресурса, и пострадает правообладатель (и потребитель).
Яндекс, выдавая ссылку на пиратский контент, не нарушает закон: ведь он не хранит видеофайлы на своих серверах, а лишь предоставляет пользователям информацию, где найти файлы. Если хранение этих данных считать преступлением, то и РКН придется признать виновным: у него есть реестр запрещенных в РФ сайтов! К тому же, удаление ссылок не повлияет на судьбу ресурса, который разместил видео. Пользователь найдет нужный сериал с помощью любой другой поисковой системы (Гугл или Рамблер), или зайдет на ресурс и воспользуется внутренним поиском.
Получается, что борьба с нелегальным контентом подменяется противостоянием с сервисом, владеющим списками такого контента. При этом контент остается нетронутым.
Dura lex, sed lex: каким бы странным и нелогичным ни казалось требование РКН — оно основано на определении суда, а значит, его необходимо исполнять. Яндекс удалил из баз ссылки на спорные сериалы, и причин для его блокировки больше нет. Остается вопрос — насколько разумно бороться с нелегальным контентом с помощью блокировок? Не будет ли это борьбой с ветряными мельницами?
Установка плагина WP Maintenance Mode
Данный плагин очень прост в настройке, имеет много различных возможностей и не нагружает ваш сайт.
Вы можете его активировать только тогда, когда он вам нужен, а если вы не используете данный плагин, то вы его просто деактивируете и он вообще не дает ни какой нагрузки на сайт.
- 1.Копируем его название и переходим в админку сайта.
- 2.Устанавливаем и активируем его как любой другой плагин.
- 3.И после его установки у вас в разделе «Настройки» появится пункт «Техническое обслуживание». Переходим в этот раздел, и мы видим, что все настройки данного плагина разбиты на несколько вкладок.
-
4.Прежде всего, что бы включить режим техобслуживания и закрыть ваш сайт для посетителей необходимо выставить здесь «Включено»
- 5.На этой же вкладке вы можете выбрать закрывать ли ваш сайт от индексации
-
6.Так же вы можете выбрать, пользователи с какими правами, а точнее ролями, могут иметь доступ к административной части вашего сайта.
Когда вы создаете нового пользователя или редактируете уже существующего, WordPress позволяет назначать этому пользователю определенную роль. Это может быть подписчик, участник, автор, редактор и администратор.
Так вот, в настройках данного плагина вы можете задать определенные группы пользователей с определенными ролями для доступа к панели управления сайтом и к фронт-энду сайта.
Если вам нужно просто временно закрыть ваш сайт для внесения определенных правок, то выставлять здесь ни чего не нужно.
Так же, здесь можно выставить мета тэг для роботов, но, опять таки, если вы кратковременно закрываете сайт, то все эти настройки вам не понадобятся.
Ещё у данного плагина есть возможность перенаправлять всех посетителей, зашедших по адресу вашего сайта на какую-то определенную страницу, или на какой-то другой сайт.
Здесь же можно добавить определенные исключения, то есть, что бы у посетителя был доступ к новостной ленте, архивам сайта, страницам, и так далее.
7.После того, как вы включаете режим технического обслуживания у вас, в административной части сайта, при редактировании каких-то страниц и установке плагинов, постоянно высвечивается предупреждение о том, что у вас включен режим технического обслуживания.
Это делается для того, что бы вы ни забыли его отключить после того, как внесете все необходимые правки. На вкладке «Общие» вы можете выбрать, высвечивать это предупреждение, или нет. Я рекомендую вам оставить здесь «Да».
8.Так же, при желании, на странице технического обслуживания вы можете добавить, либо не добавлять, ссылку для входа в панель управления.
9.После того, как все настройки заданы нажимаем на кнопку «Сохранить настройки».
Если я сейчас из админки перейду на страницу данного сайта, то для меня как для администратора, данный сайт будет, по-прежнему, доступен. Однако, если я, например, выйду из административной части сайта, или зайду на сайт через другой браузер, то я увижу вот такую картину:
Текст данного сообщения вы так же можете менять в настройках плагина.