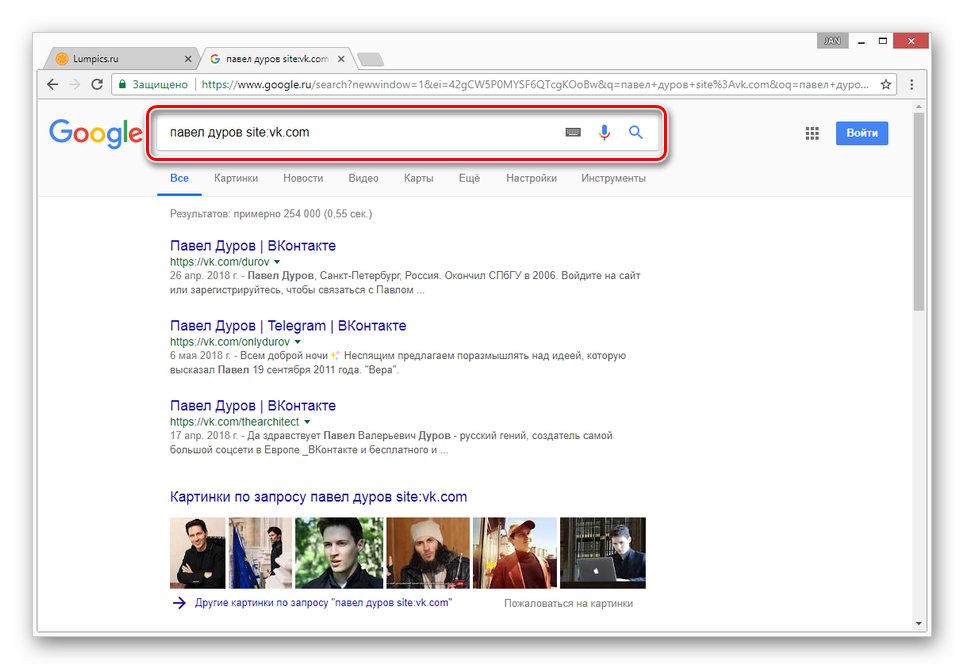
Руководство: как закрыть сайт от индексации в поисковых системах? работа с файлом robots.txt
Содержание:
Настройка
Для грамотной настройки файла роботов нам нужно точно знать, какие из разделов сайта должны быть проиндексированы, а какие – нет. В случае с простым одностраничником на html + css нам достаточно прописать несколько основных директив, таких как:
User-agent: *
Allow: /
Sitemap: site.ru/sitemap.xml
Host: www.site.ru
Здесь мы указали правила и значения для всех поисковых систем. Но лучше добавить отдельные директивы для Гугла и Яндекса. Выглядеть это будет так:
User-agent: *
Allow: /
User-agent: Yandex
Allow: /
Disallow: /politika
User-agent: GoogleBot
Allow: /
Disallow: /tags/
Sitemap: site.ru/sitemap.xml
Host: site.ru
Теперь на нашем html-сайте будут индексироваться абсолютно все файлы. Если мы хотим исключить какую-то страницу или картинку, то нам необходимо указать относительную ссылку на этот фрагмент в Disallow.
Вы можете использовать сервисы автоматической генерации файлов роботс. Не гарантирую, что с их помощью вы создадите идеально правильный вариант, но в качестве ознакомления можно попробовать.
Среди таких сервисов можно выделить:
- PR-CY,
- htmlweb.
С их помощью вы сможете создать robots.txt в автоматическом режиме. Лично я крайне не рекомендую этот вариант, потому как намного проще сделать это вручную, настроив под свою платформу.
Говоря о платформах, я имею ввиду всевозможные CMS, фреймворки, SaaS-системы и многое другое. Далее мы поговорим о том, как настраивать файл роботов WordPress и Joomla.
Но перед этим выделим несколько универсальных правил, которыми можно будет руководствоваться при создании и настройке роботс почти для любого сайта:
Закрываем от индексирования (Disallow):
Открываем (Allow):
- картинки;
- JS и CSS-файлы;
- прочие элементы, которые должны учитываться поисковыми системами.
Помимо этого, в конце не забываем указать данные sitemap (путь к карте сайта) и host (главное зеркало).
What is a robots.txt file?
Robots.txt is a text file webmasters create to instruct web robots (typically search engine robots) how to crawl pages on their website. The robots.txt file is part of the the robots exclusion protocol (REP), a group of web standards that regulate how robots crawl the web, access and index content, and serve that content up to users. The REP also includes directives like meta robots, as well as page-, subdirectory-, or site-wide instructions for how search engines should treat links (such as “follow” or “nofollow”).
In practice, robots.txt files indicate whether certain user agents (web-crawling software) can or cannot crawl parts of a website. These crawl instructions are specified by “disallowing” or “allowing” the behavior of certain (or all) user agents.
Basic format:
User-agent: Disallow:
Together, these two lines are considered a complete robots.txt file — though one robots file can contain multiple lines of user agents and directives (i.e., disallows, allows, crawl-delays, etc.).
Within a robots.txt file, each set of user-agent directives appear as a discrete set, separated by a line break:
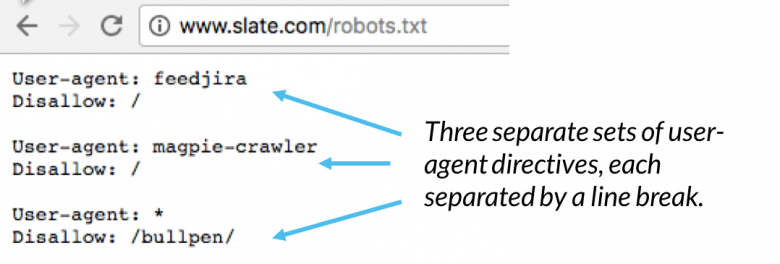
In a robots.txt file with multiple user-agent directives, each disallow or allow rule only applies to the useragent(s) specified in that particular line break-separated set. If the file contains a rule that applies to more than one user-agent, a crawler will only pay attention to (and follow the directives in) the most specific group of instructions.
Here’s an example:
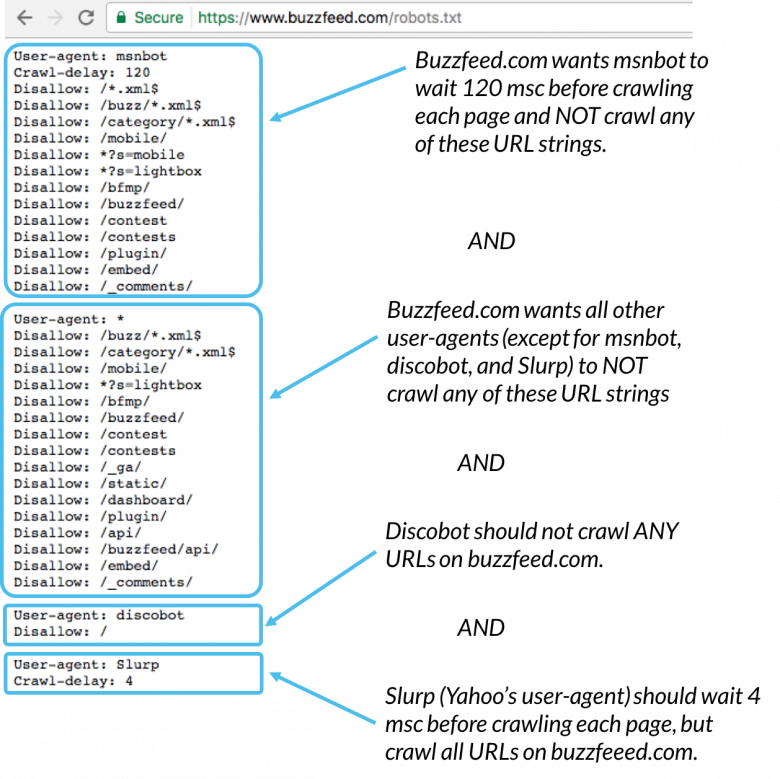
Msnbot, discobot, and Slurp are all called out specifically, so those user-agents will only pay attention to the directives in their sections of the robots.txt file. All other user-agents will follow the directives in the user-agent: * group.
Example robots.txt:
Here are a few examples of robots.txt in action for a www.example.com site:
Blocking all web crawlers from all content
User-agent: * Disallow: /
Using this syntax in a robots.txt file would tell all web crawlers not to crawl any pages on www.example.com, including the homepage.
Allowing all web crawlers access to all content
User-agent: * Disallow:
Using this syntax in a robots.txt file tells web crawlers to crawl all pages on www.example.com, including the homepage.
Blocking a specific web crawler from a specific folder
User-agent: Googlebot Disallow: /example-subfolder/
This syntax tells only Google’s crawler (user-agent name Googlebot) not to crawl any pages that contain the URL string www.example.com/example-subfolder/.
Blocking a specific web crawler from a specific web page
User-agent: Bingbot Disallow: /example-subfolder/blocked-page.html
This syntax tells only Bing’s crawler (user-agent name Bing) to avoid crawling the specific page at www.example.com/example-subfolder/blocked-page.html.
How does robots.txt work?
Search engines have two main jobs:
- Crawling the web to discover content;
- Indexing that content so that it can be served up to searchers who are looking for information.
To crawl sites, search engines follow links to get from one site to another — ultimately, crawling across many billions of links and websites. This crawling behavior is sometimes known as “spidering.”
After arriving at a website but before spidering it, the search crawler will look for a robots.txt file. If it finds one, the crawler will read that file first before continuing through the page. Because the robots.txt file contains information about how the search engine should crawl, the information found there will instruct further crawler action on this particular site. If the robots.txt file does not contain any directives that disallow a user-agent’s activity (or if the site doesn’t have a robots.txt file), it will proceed to crawl other information on the site.
Other quick robots.txt must-knows:
(discussed in more detail below)
-
In order to be found, a robots.txt file must be placed in a website’s top-level directory.
-
Robots.txt is case sensitive: the file must be named “robots.txt” (not Robots.txt, robots.TXT, or otherwise).
-
The /robots.txt file is a publicly available: just add /robots.txt to the end of any root domain to see that website’s directives (if that site has a robots.txt file!). This means that anyone can see what pages you do or don’t want to be crawled, so don’t use them to hide private user information.
-
Each subdomain on a root domain uses separate robots.txt files. This means that both blog.example.com and example.com should have their own robots.txt files (at blog.example.com/robots.txt and example.com/robots.txt).
-
It’s generally a best practice to indicate the location of any sitemaps associated with this domain at the bottom of the robots.txt file. Here’s an example:

Описание robots.txt
Чтобы правильно написать robots.txt, предлагаем вам изучить разделы этого сайта. Здесь собрана самая полезная информация о синтаксисе robots.txt, о формате robots.txt, примеры использования, а также описание основных поисковых роботов Рунета.
- Как работать с robots.txt — узнайте, что вы можете сделать, чтобы управлять роботами, которые посещают ваш веб-сайт.
- Роботы Рунета — разделы по роботам поисковых систем, популярных на просторах Рунета.
- Частые ошибки в robots.txt — список наиболее частых ошибок, допускаемых при написании файла robots.txt.
- ЧаВо по веб-роботам — часто задаваемые вопросы о роботах от пользователей, авторов и разработчиков.
- Ссылки по теме — аналог оригинального раздела «WWW Robots Related Sites», но дополненый и расширенный, в основном по русскоязычной тематике.
Где размещать файл robots.txt
Робот просто запрашивает на вашем сайте URL «/robots.txt», сайт в данном случае – это определенный хост на определенном порту.
| URL Сайта | URL файла robots.txt |
| http://www.w3.org/ | http://www.w3.org/robots.txt |
| http://www.w3.org:80/ | http://www.w3.org:80/robots.txt |
| http://www.w3.org:1234/ | http://www.w3.org:1234/robots.txt |
| http://w3.org/ | http://w3.org/robots.txt |
На сайте может быть только один файл «/robots.txt». Например, не следует помещать файл robots.txt в пользовательские поддиректории – все равно роботы не будут их там искать. Если вы хотите иметь возможность создавать файлы robots.txt в поддиректориях, то вам нужен способ программно собирать их в один файл robots.txt, расположенный в корне сайта. Вместо этого можно использовать Мета-тег Robots.
Не забывайте, что URL-ы чувствительны к регистру, и название файла «/robots.txt» должно быть написано полностью в нижнем регистре.
| Неправильное расположение robots.txt | |
| http://www.w3.org/admin/robots.txt | Файл находится не в корне сайта |
| http://www.w3.org/~timbl/robots.txt | Файл находится не в корне сайта |
| ftp://ftp.w3.com/robots.txt | Роботы не индексируют ftp |
| http://www.w3.org/Robots.txt | Название файла не в нижнем регистре |
Как видите, файл robots.txt нужно класть исключительно в корень сайта.
Что писать в файл robots.txt
В файл robots.txt обычно пишут нечто вроде:
В этом примере запрещена индексация трех директорий.
Затметьте, что каждая директория указана на отдельной строке – нельзя написать «Disallow: /cgi-bin/ /tmp/». Нельзя также разбивать одну инструкцию Disallow или User-agent на несколько строк, т.к. перенос строки используется для отделения инструкций друг от друга.
Регулярные выражения и символы подстановки так же нельзя использовать. «Звездочка» (*) в инструкции User-agent означает «любой робот». Инструкции вида «Disallow: *.gif» или «User-agent: Ya*» не поддерживаются.
Конкретные инструкции в robots.txt зависят от вашего сайта и того, что вы захотите закрыть от индексации. Вот несколько примеров:
Запретить к индексации все файлы кроме одного
Это довольно непросто, т.к. не существует инструкции “Allow”. Вместо этого можно переместить все файлы кроме того, который вы хотите разрешить к индексации в поддиректорию и запретить ее индексацию:
Либо вы можете запретить все запрещенные к индексации файлы:
Используемые технологии
Искусственный интеллект
Свойство механизмов самостоятельно выбирать путь решения для каждой поставленной перед ним задачи, опираясь на информацию базы данных. Важнейший аспект при этом – самообучение, в ходе которого робот разрабатывает программы действий.
ИИ использовались при создании: Deep Blue – анализатора-шахматиста, который сумел обыграть чемпиона мира Каспарова; MYCIN, способного ставить точный диагноз пациенту после оценки состояния его здоровья, а также ViaVoice служащие в качестве консультантов, умеющие поддерживать конструктивный диалог с потребителями.
Навигация
Навигационная бортовая система выполняет несколько функций одновременно:
Наибольший вклад в совершенствование систем навигации внесли компании, разрабатывающие видеоигры. Они инвестировали огромные средства в исследования и разработку соответствующих проектов.
Компьютерное зрение
Технология, наделяющая робота способностью определять, классифицировать объёмные предметы и изображения, распознавать образы. Благодаря этому были созданы устройства, собирающие пазлы и конструкторы Lego, системы видеонаблюдения, 3D-моделирования, виртуальной реальности, индексированные базы изображений.
Робот-курьер от «Яндекса» тестируется на улицах
«Яндекс» начал тестировать беспилотную доставку из кафе и ресторанов в Москве и Иннополисе. Заказы блюд, оформленные клиентом через приложение «Яндекс.еда», привозит робот-доставщик «Яндекс.ровер». Об этом представители «Яндекса» сообщили CNews.
«Яндекс» полагает, что в будущем робот возьмет на себя часть заказов, которые сейчас развозят курьеры.
«Яндекс.ровер» — полуметровый робот-курьер для перевозки небольших грузов. Робот вмещает в себя до 20 кг. Компания начала его разработку летом 2019 г., а затем тестировала робота в своей штаб-квартире. Робот полностью автономен: сам планирует свой маршрут, оценивает ситуацию вокруг, объезжает препятствия и пропускает пешеходов и животных. Он способен ездить по городским тротуарам со скоростью около 5 км/ч, может работать и летом, и зимой, выполняя заказы в разных погодных условиях.
На местности дрон ориентируется при помощи комплекта камер и датчиков и размещенного на его «крыше» лидара. За счет его «ровер» может обходить препятствия, притом даже в темноте.
Как сообщили CNews в пресс-службе «Яндекса», во время движения робот определяет свое местоположение, идентифицирует и классифицирует объекты вокруг, прогнозирует, как будут действовать эти объекты в следующие несколько секунд, и планирует свои действия: «Робот может преодолевать невысокие бордюры и искусственные неровности дороги. Мы также тестируем сейчас новые конструкции шасси, которые позволят ему справляться с более сложным рельефом».
Для того чтобы выбрать доставку роботом, нужно оформить заказ в приложении «Яндекс.еда», причем дополнительно доплачивать за вызов именно робота не нужно. «Ровер» заберет заказ из ресторана и привезёт к указанному подъезду. В приложении можно посмотреть статус заказа и местоположение «ровера». Для получения заказа получателю достаточно с помощью своего смартфона открыть крышку грузового отсека робота. Пока число роботов ограничено, если свободного робота не окажется, заказ привезёт курьер — они продолжат доставлять еду в этом районе.
Робот-доставщик «Яндекс.Ровер»
В Москве компания тестирует необычного курьера в районе делового квартала «Белая площадь» у метро «Белорусская». Там расположены крупные офисы российских и иностранных компаний, а также кафе и рестораны. «Ровер» возит заказы из ресторанов и кафе «Марукамэ», Steak it Easy, Boston Seafood & Bar, Prime, Paul и Cheese Connection. С подключением новых точек общественного питания зона беспилотной доставки будет расширяться.
Еще одно место обитания роботов-доставщиков — Иннополис под Казанью. Жители могут сделать заказ в ресторане и выбрать беспилотную доставку в приложении «Яндекс.еда» или в городском Telegram-боте. В дальнейшем, как планируют разработчики, они будут подключаться к другим задачам и помогать жителям с повседневными делами.
В ответ на вопрос CNews, как компания уберегает роботов от вандалов, представители «Яндекса» ответили, что местоположение каждого из роботов известно в компании, плюс, сам «ровер» может подать сигнал оператору, «если поймет, что что-то идет не так».
В Москве количество роботов может варьироваться в зависимости от динамики заказов в районе. В Иннополисе сейчас работает пять роботов, и в ближайшее время к ним присоединятся еще роботы для новых сценариев доставки, уточнили в пресс-службе.
Для чего нужна проверка robots.txt
Иногда в результаты поиска система включает ненужные страницы вашего Интернет-ресурса, в чем нет необходимости. Может показаться, что ничего плохого в большом количестве страниц в индексе поисковой системы нет, но это не так:
- На лишних страницах пользователь не найдет никакой полезной информации для себя. С большей долей вероятности он и вовсе не посетит эти страницы либо задержится на них недолго;
- В выдаче поисковика присутствуют одни и те же страницы, адреса которых различны (то есть контент дублируется);
- Поисковым роботам приходится тратить много времени, чтобы проиндексировать совершенно ненужные страницы. Вместо индексации полезного контента они будут бесполезно блуждать по сайту. Поскольку индексировать полностью весь ресурс робот не может и делает это постранично (так как сайтов очень много), то нужная информация, которую вы бы хотели получить после ведения запроса, возможно, будет найдена не очень быстро;
- Очень сильно нагружается сервер.
В связи с этим является целесообразным закрытие доступа поисковым роботам к некоторым страницам веб-ресурсов.
Какие же файлы и папки можно запретить индексировать:
- Страницы поиска. Это спорный пункт. Иногда использование внутреннего поиска на сайте необходимо, для того чтобы создать релевантные страницы. Но делается это не всегда. Зачастую результатом поиска становится появление большого количества дублированных страниц. Поэтому рекомендуется закрыть страницы поиска для индексации.
- Корзина и страница, на которой оформляют/подтверждают заказ. Их закрытие рекомендовано для сайтов онлайн-торговли и других коммерческих ресурсов, использующих форму заказа. Попадание этих страниц в индекс поисковых систем крайне нежелательно.
- Страницы пагинации. Как правило, для них характерно автоматическое прописывание одинаковых мета-тегов. Кроме того, их используют для размещения динамического контента, поэтому в результатах выдачи появляются дубли. В связи с этим пагинация должна быть закрыта для индексации.
- Фильтры и сравнение товаров. Закрывать их нужно онлайн-магазинам и сайтам-каталогам.
- Страницы регистрации и авторизации. Закрывать их нужно в связи с конфиденциальностью вводимых пользователями при регистрации или авторизации данных. Недоступность этих страниц для индексации будет оценена Гуглом.
- Системные каталоги и файлы. Каждый ресурс в Интернете состоит из множества данных (скриптов, таблиц CSS, административной части), которые не должны просматриваться роботами.
Закрыть файлы и страницы для индексации поможет файл robots.txt.
Рекомендуемые статьи по данной теме:
- Проверка тИЦ сайта: 3 способа
- Внутренняя оптимизация сайта: пошаговый разбор
- Файл htaccess: применение, включение, настройка
robots.txt – это обычный текстовый файл, содержащий инструкции для поисковых роботов. Когда поисковый робот оказывается на сайте, то в первую очередь занимается поиском файла robots.txt. Если же он отсутствует (или пустой), то робот будет заходить на все страницы и каталоги ресурса (в том числе и системные), находящиеся в свободном доступе, и пытаться провести их индексацию. При этом нет гарантии, что будет проиндексирована нужная вам страница, поскольку он может и не попасть на нее.
robots.txt позволяет направлять поисковые роботы на нужные страницы и не пускать на те, которые индексировать не следует. Файл может инструктировать как всех роботов сразу, так и каждого в отдельности. Если страницу сайта закрыть от индексации, то она никогда не появится в выдаче поисковой системы. Создание файла robots.txt является крайне необходимым.
Местом нахождения файла robots.txt должен быть сервер, корень вашего ресурса. Файл robots.txt любого сайта доступен для просмотра в Сети. Чтобы увидеть его, нужно после адреса ресурса добавить /robots.txt.
Как правило, файлы robots.txt различных ресурсов отличаются друг от друга. Если бездумно скопировать файл чужого сайта, то при индексации вашего поисковыми роботами возникнут проблемы. Поэтому так необходимо знать, для чего нужен файл robots.txt и инструкции (директивы), используемые при его создании.
Оставить заявку
Вас также может заинтересовать: Что делать, если упала посещаемость сайта
Что такое robots.txt и для чего он нужен
Robots.txt — это обычный текстовый файл с расширением .txt, который содержит директивы и инструкции индексирования сайта, его отдельных страниц или разделов для роботов поисковых систем.
Давайте рассмотрим самый простой пример содержимого robots.txt, которое разрешает поисковым системам индексировать все разделы сайта:
User-agent: * Allow: /
Данная инструкция дословно говорит: всем роботам, читающим данную инструкцию (User-agent: *) разрешаю индексировать весь сайт (Allow: /).
 Зачем все эти сложности с инструкциями для роботов, и почему нельзя открывать сайт для индексации полностью?
Зачем все эти сложности с инструкциями для роботов, и почему нельзя открывать сайт для индексации полностью?
Представьте, что вы поисковый робот, которому нужно просмотреть миллиарды страниц по всем интернету, потом определить для каждой страницы запросы, которым они могут соответствовать и в конце проранжировать эту массу в поисковой выдаче. Согласитесь, задача не из легких. Для работы поисковых алгоритмов используются колоссальные ресурсы, которые, разумеется, ограничены.
Если помимо страниц, которые содержат полезный контент, и которые по задумке владельца сайта должны участвовать в выдаче, роботу придется просматривать еще кучу технических страниц, которые не представляют никакой ценности для пользователей, его ресурсы будут тратиться впустую. Вы только представьте, что только один единственный сайт может генерировать тысячи страниц результатов поиска по сайту, дублирующихся страниц или страниц, не содержащих контента вообще. А если этот объем масштабировать на всю сеть, то получатся гигантские цифры и соответствующие ресурсы, которые необходимо тратить поисковикам.
Наличие огромного количества бесполезного контента на вашем сайте может негативно сказаться на его представлении в поиске. Как бы вы отнеслись к человеку, который дал вам мешок орехов, но внутри оказалась только скорлупа и всего 2-3 орешка? Не трудно представить и позицию поисковиков при аналогии данной ситуации с вашим сайтом.
Кроме того, существует такое понятие, как краулинговый бюджет. Условно, это объем страниц, который может участвовать в поисковой выдаче от одного сайта. Этот объем, естественно, ограничен, но по мере роста проекта и повышения его качества, краулинговый бюджет может увеличиваться, но сейчас не об этом. Главное идея в том, в выдаче должны участвовать только страницы, которые содержат полезный контент, а весь технический «мусор» не должен засорять выдачу поисковым спамом.
Со временем функциональность роботов расширят
Еще во время тестирования «Яндекс» рассказывал, что «Яндекс.роверы», помимо прочего, могут развозить документы от дверей штаб-квартиры «Яндекса» до места остановки автобуса, который доставляет их в другие столичные офисы техногиганта. Также специалисты «Яндекса» тестировали разные конструкции шасси, которые позволят справляться с рельефом различной сложности и обеспечат безопасность груза.
Дмитрий Полищук говорит, что в последние годы наблюдается постоянный рост спроса на услуги доставки, и события, связанные с пандемией в 2020 г., его еще больше ускорили. «Роверы могут привозить еду из ресторанов, продукты из супермаркетов, заказы из онлайн-магазинов и постепенно будут становиться привычной частью городской жизни», — пояснил он.
Помимо этого, «Яндекс.ровер» может использоваться в складской логистике. Также, как один из вариантов развития проекта «ровер», «Яндекс» видит использование своих роботов другими компаниями.
Что за роботс ти экс ти?
Файл robots.txt или индексный файл — обычный текстовый документ в кодировке UTF-8, действует для протоколов http, https, а также FTP. Файл дает поисковым роботам рекомендации: какие страницы/файлы стоит сканировать. Если файл будет содержать символы не в UTF-8, а в другой кодировке, поисковые роботы могут неправильно их обработать. Правила, перечисленные в файле robots.txt, действительны только в отношении того хоста, протокола и номера порта, где размещен файл.
Файл должен располагаться в корневом каталоге в виде обычного текстового документа и быть доступен по адресу: https://site.com.ua/robots.txt.
В других файлах принято ставить отметку ВОМ (Byte Order Mark). Это Юникод-символ, который используется для определения последовательности в байтах при считывании информации. Его кодовый символ — U+FEFF. В начале файла robots.txt отметка последовательности байтов игнорируется.
Google установил ограничение по размеру файла robots.txt — он не должен весить больше 500 Кб.
Ладно, если вам интересны сугубо технические подробности, файл robots.txt представляет собой описание в форме Бэкуса-Наура (BNF). При этом используются правила RFC 822.
При обработке правил в файле robots.txt поисковые роботы получают одну из трех инструкций:
- частичный доступ: доступно сканирование отдельных элементов сайта;
- полный доступ: сканировать можно все;
- полный запрет: робот ничего не может сканировать.
При сканировании файла robots.txt роботы получают такие ответы:
- 2xx — сканирование прошло удачно;
- 3xx — поисковый робот следует по переадресации до тех пор, пока не получит другой ответ. Чаще всего есть пять попыток, чтобы робот получил ответ, отличный от ответа 3xx, затем регистрируется ошибка 404;
- 4xx — поисковый робот считает, что можно сканировать все содержимое сайта;
- 5xx — оцениваются как временные ошибки сервера, сканирование полностью запрещается. Робот будет обращаться к файлу до тех пор, пока не получит другой ответ.Поисковый робот Google может определить, корректно или некорректно настроена отдача ответов отсутствующих страниц сайта, то есть, если вместо 404 ошибки страница отдает ответ 5xx, в этом случае страница будет обрабатываться с кодом ответа 404.
Пока что неизвестно, как обрабатывается файл robots.txt, который недоступен из-за проблем сервера с выходом в интернет.
Структура robots.txt
Строение файла выглядит просто. Он включает ряд блоков, адресованных конкретным ботам-поисковикам. В этих блоках прописываются директивы (команды) для управления ходом индексации.
Дополнительно можно проставлять комментарии. Чтобы они игнорировались поисковиком, нужно использовать знак #. Каждый комментарий начинается и заканчивается этим символом. Кроме того, не рекомендуется вставлять символ комментария внутри директивы.
Robots.txt создаётся одним из удобных для вас методов:
- вручную с использованием текстового редактора, после чего он сохраняется с расширением *. txt.
- автоматически с применением онлайн-программ.
Большинство специалистов работают с файлом вручную — процесс достаточно прост, занимает немного времени, но при этом вы будете уверены в правильности его написания.
В любом случае, автоматически сформированные файлы обязательно подлежат проверке, ведь от этого зависит, насколько хорошо будет функционировать ваш сайт.
Пара слов и картиночек для знакомства с Robot Framework
Прежде чем разбирать плюсы и минусы, давайте очень коротко поговорим о том, что же такое Robot Framework. Возможно, кто-то впервые видит это название.
Robot Framework – это keyword-driven фреймворк, разработанный специально для автоматизации тестирования. Он написан на Python, но для написания тестов обычно достаточно использовать готовые ключевые слова (кейворды), заложенные в этом фреймворке, не прибегая к программированию на Python. Нужно лишь загрузить необходимые библиотеки, например, SeleniumLibrary, и можно писать тест. В этой статье я дам общее представление о Robot Framework, но если после прочтения вы захотите углубиться в тему, то советую обратиться к официальной документации. В конце статьи также приведены ссылки на популярные библиотеки.
Что ж, перейдем к «картиночкам». Вот так может выглядеть простой проект в IDE (на примере всеми любимой Википедии):
-
Синий и зеленый – папки с файлами для описания страниц и тестов соответственно. Так можно реализовать page object паттерн.
-
Коричневый – драйвера для различных браузеров.
-
Красный – тело теста.
-
Желтый – консоль, из которой можно запускать тесты и видеть консольные сообщения (полноценные логи не тут, но об этом позже).
Как видно, в тесте сплошные «обертки» в стиле BDD (можно не применять такой синтаксис, но лично мне он тут кажется удобным). Имплементация находится в объектах страниц, например:
В стандартной секции Settings мы видим подгрузку библиотеки для работы с Selenium, а в другой стандартной секции Keywords находятся имплементации наших самописных ключевых слов.
Думаю, для получения общего представления этого достаточно. Детальное описание работы с Robot Framework лежит за рамками моего поста
Что такое robots.txt
Robots.txt — файл, который говорит поисковой системе, какие разделы и страницы вашего сайта нужно включать в поиск, а какие — нельзя. Ну то есть он говорит не поисковой системе напрямую, а её роботу, который обходит все сайты интернета. Вот что такое роботс. Этот файл всегда создается в универсальном формате .txt, который сможет открыть даже компьютер вашего деда.
Вот видос от Яндекса:
Основное назначение – контроль за доступом к публикуемой информации. При необходимости определенную информацию можно закрыть для роботов. Стандарт robots был принят в начале 1994 года, но спустя десятилетие продолжает жить.
Использование стандарта осуществляется на добровольной основе владельцами сайтов. Файл должен включать в себя специальные инструкции, на основе которых проводится проверка сайта поисковыми роботами.
Самый простой пример robots:
User-agent: * Allow: /
Данный код открывает весь сайт, структура которого должна быть безупречной.
Зачем закрывают какие-то страницы? Не проще ли открыть всё?
Смотрите — у каждого сайта есть свой лимит, который называется краулинговый бюджет. Это максимальное количество страниц одного конкретного сайта, которое может попасть в индекс. То есть, допустим, у какого-нибудь М-Видео краулинговый бюджет может составлять десять миллионов страниц, а у сайта дяди Вани, который вчера решил продавать огурцы через интернет — всего сотню страниц. Если вы откроете для индексации всё, то в индекс, скорее всего, попадет куча мусора, и с большой вероятностью этот мусор займет в индексе место некоторых нужных страниц. Вот чтобы такой хрени не случилось, и нужен запрет индексации.
Где находится Robots
Robots традиционно загружают в корневой каталог сайта.
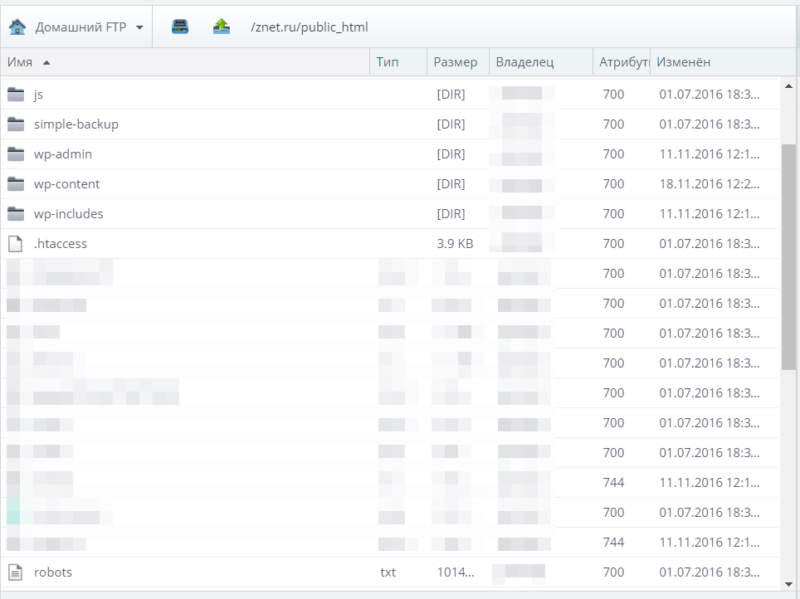
Это корневой каталог, и в нем лежит роботс.
Для загрузки текстового файла обычно используется FTP доступ. Некоторые CMS, например WordPress или Joomla, позволяют создавать robots из админпанели.