Noindex и nofollow: как, зачем и для чего используют в seo
Содержание:
Что такое файл Robots.txt?
Robots.txt – это файл, который указывает поисковым роботам (например, Googlebot и Bingbot), какие страницы сайта не должны сканироваться.
Чем полезен файл Robots.txt?
Файл robots.txt сообщает роботам системам, какие страницы могут быть просканированы. Но не может контролировать их поведение и скорость сканирования сайта. Этот файл, по сути, представляет собой набор инструкций для поисковых роботов о том, к каким частям сайта доступ ограничен.
Но не все поисковые системы выполняют директивы файла robots.txt. Если у вас остались вопросы насчет robots.txt, ознакомьтесь с часто задаваемыми вопросами о роботах.
Как создать файл Robots.txt?
По умолчанию файл robots.txt выглядит следующим образом:
Можно создать свой собственный файл robots.txt в любом редакторе, который поддерживает формат .txt. С его помощью можно заблокировать второстепенные веб-страницы сайта. Файл robots.txt – это способ сэкономить лимиты, которые могут пойти на сканирование других разделов сайта.
Директивы для сканирования поисковыми системами
User-Agent: определяет поискового робота, для которого будут применяться ограничения в сканировании URL-адресов. Например, Googlebot, Bingbot, Ask, Yahoo.
Disallow: определяет адреса страниц, которые запрещены для сканирования.
Allow: только Googlebot придерживается этой директивы. Она разрешает анализировать страницу, несмотря на то, что сканирование родительской веб-страницы запрещено.
Sitemap: указывает путь к файлу sitemap сайта.
Правильное использование универсальных символов
В файле robots.txt символ (*) используется для обозначения любой последовательности символов.
Директива для всех типов поисковых роботов:
User-agent:*
Также символ * можно использовать, чтобы запретить все URL-адреса кроме родительской страницы.
User-agent:*
Disallow: /authors/*
Disallow: /categories/*
Это означает, что все URL-адреса дочерних страниц авторов и страниц категорий заблокированы за исключением главных страниц этих разделов.
Ниже приведен пример правильного файла robots.txt:
User-agent:* Disallow: /testing-page/ Disallow: /account/ Disallow: /checkout/ Disallow: /cart/ Disallow: /products/page/* Disallow: /wp/wp-admin/ Allow: /wp/wp-admin/admin-ajax.php Sitemap: yourdomainhere.com/sitemap.xml
После того, как отредактируете файл robots.txt, разместите его в корневой директории сайта. Благодаря этому поисковый робот увидит файл robots.txt сразу после захода на сайт.
Как использовать noindex и nofollow в meta robots
Посмотрим на возможные значения атрибута content:
- noindex, nofollow – запрещена к индексации вся страница и переходы по ссылкам на ней; кстати, идентичной будет значение при записи: <meta name =”robots” content=”none”/>
- noindex, follow – страница не индексируется, но поисковик может переходить по ссылкам;
- index, nofollow – страница индексируется, но переход по ссылкам запрещен;
- index, follow – разрешены к индексированию как страница, так и ссылки на ней;
- noarchive – работает как в yandex, так и в google – не показывает страницу на сохраненную копию;
- noyaca – работает только в Яндексе, если сайт зарегистрирован в каталоге YACA – запрещает использовать описание в результатах поиска, которое берется из Яндекс.Каталога; выглядит так: <meta name =”robots” content=”noyaca”/>
- noodp – работает и в Яндексе, и в Google – запрещает использовать в результатах описания, которые взяты из Каталога ДМОЗ (разумеется, если сайт там зарегистрирован).
Поговорим чуть больше о noodp
Иногда Гугл может добавлять в сниппет описание из DMOZ. Именно для этого и используется атрибут noodp. Кстати, его можно использовать вместе с тегом nofollow. Выглядит это так:
<meta name=“robots” content=”noodp, nofollow”/>
Чего нужно опасаться при использовании
Из-за невнимательности (особенно у новичков) могут случаться конфликты между тегами: в таком случае главным будет положительное значение (разрешающее индексацию). Например тут:
<meta name =”robots” content=”all”/> <meta name =”robots” content=”noindex, nofollow”/>
Тут выбрано будет первое значение, так как там оно положительно.
Conflicting parameters, and robots.txt files
It’s important to remember that meta robots tags work differently to instructions in your robots.txt file, and that conflicting rules may cause unexpected behaviors. For example, search engines won’t be able to see your tags if the page is blocked via .
You should also take care to avoid setting conflicting values in your meta robots tag (such as using both and parameters) – particularly if you’re setting different rules for different search engines. In cases of conflict, the most restrictive interpretation is usually chosen (i.e., “don’t show” usually beats “show”).
Adding a or to a post or page is a breeze if you’re on WordPress. Read how to use Yoast SEO to keep a post out of the search results.
How to Set Up Robots Meta Tags and X‑Robots-Tag
Setting up robots meta tags is, generally, easier than the x-robots-tag, but the implementation of both methods of controlling how search engines crawl and index your site can differ depending on your CMS and/or server type.
Here’s how yo use meta robots tags and the x-robots-tag on common setups:
Using Robots Meta Tags in HTML Code
If you can edit your page’s HTML code, simply add your robots meta tags straight into the <head> section of the page.
If you want search engines not to index the page but want links to be followed, as an example, use:
Using Robots Meta Tags on WordPress
If you’re using Yoast SEO, open up the ‘advanced’ tab in the block below the page editor.
You can set the «noindex» directive by setting the «Allow search engines to show this page in search results?» dropdown to no or prevent links from being followed by setting the «Should search engines follow links on this page?» to no.
For any other directives, you will need to implement these in the «Meta robots advanced» field.
If you’re using RankMath, you can select the robots directives that you wish apply straight from the Advanced tag of the meta box:
Image courtesy of RankMath
Using Robots Meta Tags on Shopify
If you need to implement robots meta tags on Shopify, you’ll need to do this by editing the <head> section of your theme.liquid layout file.
To set the directives for a specific page, add the below code to this file:
This code will instruct search engines, not to index /page-name/ but to follow all of the links on the page.
You will need to make separate entries to set the directives across different pages.
Using X-Robots-Tag on an Apache Server
To use the x-robots-tag on an Apache web server, add the following to your site’s .htaccess file or httpd.config file.
The example above sets the file type of .pdf and instructs search engines not to index the file but to follow any links on it.
Using X-Robots-Tag on an Nginx Server
If you’re running an Nginx server, add the below to your site’s .conf file:
This will apply a noindex attribute and follow any links on a .pdf file.
Indexation-controlling parameters:
-
Noindex: Tells a search engine not to index a page.
-
Index: Tells a search engine to index a page. Note that you don’t need to add this meta tag; it’s the default.
-
Follow: Even if the page isn’t indexed, the crawler should follow all the links on a page and pass equity to the linked pages.
-
Nofollow: Tells a crawler not to follow any links on a page or pass along any link equity.
-
Noimageindex: Tells a crawler not to index any images on a page.
-
None: Equivalent to using both the noindex and nofollow tags simultaneously.
-
Noarchive: Search engines should not show a cached link to this page on a SERP.
-
Nocache: Same as noarchive, but only used by Internet Explorer and Firefox.
-
Nosnippet: Tells a search engine not to show a snippet of this page (i.e. meta description) of this page on a SERP.
-
Noodyp/noydir : Prevents search engines from using a page’s DMOZ description as the SERP snippet for this page. However, DMOZ was retired in early 2017, making this tag obsolete.
-
Unavailable_after: Search engines should no longer index this page after a particular date.
Зачем нужен ?
Тег <noindex> очень важен, если вы хотите, чтобы часть текста, со всеми анкорами ссылок и т.д., не индексировалась и не попала в поисковую базу Yandex.
Например, у вас на странице может быть служебная информация, или блок текста с сайта, который используется как негативный пример. Вы не хотите, чтобы поисковик связал ваш сайт с данным текстом или индексировал служебную информацию и сохранил у себя в базе. Для этого данный блок обрамляется тегом <noindex>.
К сожалению, такого инструмента для Google не существует
Вполне возможно, что Google или консорциум W3C в будущем обратят внимание на данный тег или придумают свой, и веб-мастера получат в свой инструментарий еще один полезный инструмент
Что такое noindex
«Ноиндекс» – тег и атрибут HTML-страницы. Можно пометить им страницу целиком, придав ей определенные свойства, либо выбрать отдельный участок кода и применить атрибут к нему.
Функция noindex заключается в «сокрытии» контента от поисковых роботов, машин, анализирующих и индексирующих веб-сайты. Они собирают базу данных для поисковых служб и предоставляют пользователям релевантные результаты поиска.
Если какая-то часть контента на странице помечена тегом noindex, то робот ее проигнорирует и в поиске она учтена не будет, что прямо повлияет на SEO-продвижение ресурса, на котором были произведены соответствующие изменения.
На самом деле, робот, конечно же, посмотрит все, что есть на сайте. Просто не будет заносить это в индексную базу.
Какой контент помечается этим тегом?
Любой. В зависимости от помеченной информации и поискового робота тег будет восприниматься по-разному.
Обычно в noindex заворачивают четыре типа текстового контента:
- Информацию с низкой уникальностью, чтобы избежать проблем с антиплагиатом.
- Коды счетчиков (типа метрики и других аналитических систем), ненужные поисковику.
- Контактные данные, номера и ссылки, которые не стоило бы показывать в поисковой выдаче.
- Постоянно меняющийся текст, индексация которого не принесет никакой пользы.
Как использовать тег?
Тег можно вставить в <head> страницы как мету (атрибутом), увеличив область его действия на всю страницу.
С таким кодом индексация страницы разрешается:
<meta name="robots" content="index"/>
А с таким индексация запрещается:
<meta name="robots" content="noindex"/>
Такое правило можно указать для конкретного робота. Например, поискового бота Google:
<meta name="googlebot" content="noindex"/>
Еще один способ — встраивание тегов в текст и оборачивание в него ссылок.
<noindex>кусок текста, который хотелось бы скрыть от индексации поисковиками</noindex>
Правда, такая разметка может нагородить ошибок из-за того, что многие поисковики не понимают тег <noindex> и считают его наличие в тексте ошибкой. Поэтому приходится исползать его вариацию <!–noindex–>. В таком виде роботы, понимающие тег, считывают его без проблем и задают нужные свойства, а непонимающие попросту игнорируют.
Независимо от типа скрываемого контента, принцип остается тем же. Поэтому, если нужно скрыть от индексации код счетчика, ничего специфичного делать не придется. Так же оборачиваем его в <noindex> и все.
NOODP — запрет использования DMOZ поисковиками
Для создания фрагментов часто применяется такой источник, как Open Directory Project. Чтобы поисковики не применяли его, для описания содержимого сайта, добавляется тег:
<meta name=»robots» content=»noodp»>
Или такой:
<meta name=»имя_робота» content=»noodp»>
Параметры атрибута content можно объединять, таким образом:
<meta name=»robots» content=»noodp, nofollow»>
Запреты поисковым системами
Каким образом можно дать понять поисковому роботу, что какую-то часть страницы не нужно проверять или по какой-то одной ссылке не стоит переходить?
Разные поисковые системы предлагают сделать это по разному. Яндекс советует вставлять такой текст между тегами <!—noindex—><!—/noindex—>, тогда как Google предлагает добавлять к ссылкам атрибут rel=»nofollow».
Метатеги для поисковых систем
Robots
Метатег указывает роботам поисковых систем, как сканировать и индексировать страницу.
Для конкретного бота можно задать свою инструкцию. Например, заменить robots на Googlebot для Гугла или на YandexBot для Яндекса.
Возможные указания:
- all – означает, что разрешена индексация и переход по ссылкам, аналогично index, follow;
- noindex – запрет индексации;
- index – разрешена индексация;
- nofollow – нельзя переходить по ссылкам;
- follow – можно переходить по ссылкам;
- noarchive – запрещено показывать ссылку на сохраненную копию в выдаче;
- noyaca – (для Яндекса) не использовать для сниппета описание из Яндекс.Каталога;
- nosnippet – (в Google) нельзя использовать для сниппета фрагмент текста и показывать видео;
- noimageindex – (в Google) запрет указания страницы как источника изображения;
- unavailable_after: – (в Google) после указанной даты будет прекращено сканирование и индексирование страницы;
- none – запрет индексации и перехода по ссылкам, аналогичен noindex, nofollow.
Description
Метатег name=«description» может использоваться поисковыми системами при формировании сниппета, поэтому он должен:
- точно описывать содержание страницы;
- вызывать желание кликнуть;
- включать продвигаемое ключевое слово.
В разных поисковых системах выводятся 160–240 символов.
Description для каждой продвигаемой страницы должен быть уникальным.
Keywords
Метатег name=«keywords» раньше использовался поисковыми системами при ранжировании, но из-за многочисленных манипуляций его значимость постоянно уменьшалась. Теперь большинство поисковиков его игнорируют. Google не поддерживает вообще, а Яндекс пишет, что может учитывать. Но на практике keywords давно не оказывает влияния, а его некорректное заполнение может привести к переспаму.
Существуют три подхода:
- оставлять пустым;
- писать конкретные фразы или отдельные слова через запятую;
- указать через пробел бессвязный набор слов, из которых могут быть составлены ключевые фразы.
Если принято решение прописать ключевые слова, важно не допускать спама. Ключевые слова должны характеризовать конкретную страницу и упоминаться в контенте
Ключевые слова должны характеризовать конкретную страницу и упоминаться в контенте.
Title
Title технически не является метатегом, но его часто относят к этой группе, потому что он содержит информацию, которая используется поисковыми системами и браузерами.
Данный HTML-тег важен для SEO: влияет на ранжирование и кликабельность по сниппету.
Классические рекомендации по заполнению метатега:
- использовать главное продвигаемое ключевое слово на странице;
- разместить ключ вначале;
- обеспечить уникальность внутри сайта;
- сделать привлекательным для пользователя;
- подобрать такую длину, чтобы заголовок не обрезался в сниппете.
Рекомендуема длина – 70–80 символов.
Атрибут rel=»nofollow» в ссылках
Этот атрибут можно прописать к любой ссылке html в теге <a>.
Синтаксис rel=»nofollow»
По такой ссылке поисковые роботы не будут переходить. Причем как Яндекс, так и Google.
Какие преимущества дает атрибут rel=»nofollow»
- Не будет передаваться статичный вес для внешних ссылок
- Поисковая машина при обходе большого сайта не будет переходить по этим ссылкам. Тем самым быстрее переиндексируя другие более ценные страницы. Не секрет, что для каждого ресурса в интернете отводиться на один обход лишь ограниченное число обращений робота.
Примечание
Для внутренних страниц сайта нет смысла задавать атрибут ссылкам rel=»nofollow». Используйте его только для внешних ссылок.
Как выглядит мета-тег и где его посмотреть
Вообще мета-тег — это обычный тег html, который используется при создании веб-страниц для хранения информации, предназначенной для браузеров и поисковых систем. Теоретически в мета-теге может содержаться абсолютно любая информация, но в контексте публикаций в Дзене обычно имеются в виду мета-теги <meta name=»robots» content=»noindex» /> или <meta property=»robots» content=»none» />.
Чтобы посмотреть, есть ли мета-тег на обычной странице, нужно кликнуть правой кнопкой мыши в любом месте страницы, и в меню выбрать пункт «Просмотр кода страницы».
Откроется окно с исходным кодом страницы, где среди множества понятных и не очень строчек можно найти нужные нам мета-теги.
 Здесь немного другой мета-тег — видите «all»? Об этом поговорим чуть ниже.
Здесь немного другой мета-тег — видите «all»? Об этом поговорим чуть ниже.
Мета-тега на странице может и не быть или он может быть немного другим, и это может менять его значение.
Влияние внутренних ссылок на индексацию сайта
Внутренние ссылки являются основной и практически единственной причиной того, что нам приходится закрывать ненужные и попавшие в индекс страницы разными метатегами и директивами robots.txt. Однако реальность такова, что ненужные роботам страницы очень даже нужны пользователям сайта, а следовательно должны быть и ссылки на эти самые страницы.
А что же делать? При любом варианте запрета индексации ссылок (rel=”nofollow”) и страниц (robots.txt, meta robots), вес сайта просто теряется, утекает на закрытые страницы.
Вариант №1. Большинство распространенных CMS имеют возможность использования специальных тегов (в DLE точно это есть, я сам этим очень активно пользуюсь) при создании шаблонов оформления, которые позволяют регулировать вывод определенной информации. Например, показывать какой-либо текст только гостям или группе пользователей с определенным id и т.д. Если таких тегов вдруг нет, то наверняка на помощь придут логические конструкции (такие конструкции есть в WordPress, а так же форумных движках IPB и vbulletin, опять же, я сам пользуюсь этими возможностями), представляющие из себя простейшие условные алгоритмы на php.
Так вот, логично было бы скрывать неважные и ненужные ссылки от гостей (обычно эту роль играют и роботы при посещении любого сайта), а так же скрывать ссылки на страницы, которые выдают сообщение о том, что вы не зарегистрированы, не имеете прав доступа и все такое. При необходимости можно специально для гостей выводить блок с информацией о том, что после регистрации у них появится больше прав и возможностей, а значит и соответствующие ссылки появятся 😉
Но бывают такие моменты, что ссылку нельзя скрыть или удалить, потому что она нужна, и нужна сразу всем – гостям, пользователям… А вот роботам не нужна. Что делать?
Вариант №2. В редких случаях (хотя последнее время все чаще и чаще) бывает необходимо, чтобы ссылки или даже целые блоки сайта были недоступны и невидны роботам, а вот людям отображались и работали в полной мере, вне зависимости от групп и привилегий. Вы уже, наверное, догадались, что я говорю про сокрытие контента при помощи JavaScript или AJAX. Как это делается технически, я не буду расписывать, это очень долго. Но есть замечательный пост Димы Dimox’а о том, как загрузить часть контента с помощью AJAX на примере WordPress (линк). В примере рассказывается про подгрузку целого сайдбара, но таким же методом можно подгрузить одну только ссылку, например. В общем, немного покопаетесь и разберетесь.
Так вот, если хочется какую-то часть контента роботам не показывать, то лучший выбор – JavaScript. А после того как провернете всю техническую часть, проверить это на работоспособность поможет замечательный плагин для FireFox под названием QuickJava. Просто с помощью плагина отключите для браузера обработку яваскрипта и перезагрузите страницу, весь динамически подгружаемый контент должен пропасть 😉 Но помните, что тут тоже надо знать меру!
И, кстати, еще парочка интересных моментов, которые необходимо знать:
Яндексу в индексации сайтов помогает Яндекс.Метрика, которая автоматически пингует в индекс все посещенные страницы, на которых установлен код Метрики. Но эту функцию можно отключить при получении кода счетчика, установив соответсвующую галочку.
Возможно как то в индексации замешаны Яндекс.Бар и сборка браузера Хром от Яндекса, но в этом я не уверен.
Но вот для Гугла есть информация, что роль поискового робота выполняет сам браузер Google Chrome. Такие уж они хитрецы.
Так что, как видим, скрыть информацию от роботов почти невозможно, если не предпринимать специальные меры.
Что изменилось с вводом поддержки rel=nofollow?
- Для тех, кто ведет ресурсы для людей и не использует спам-продвижения, почти ничего не изменится. Возможно некоторое уменьшение числа внешних ссылок, закрытых с rel=»nofollow».
- Для тех, кто использовал в продвижении ссылочный спам (спам в комментариях, спам в форумах, соц. сетях, Википедии и т.д), и у кого основная ссылочная масса, дающая ТИЦ, состояла из таких ссылок, будет существенное снижение ТИЦ и как правило, проседание в поисковой выдаче Yandex.
Кратко, о новинках апреля 2010 года в Яндекс:
- У страницы поисковой выдачи Яндекс теперь фиксированная ширина.
- Появились в выдаче навигационные цепочки, у некоторых сниппетов и даты публикации.
- Появился колдунщик видео.
- В панели веб-мастера появилась возможность просмотра статистики по собственным ключевым словам.
P.S. Теперь осталось дождаться включения поддержки Яндексом канонического атрибута rel=»canonical», о котором я писал в статье о дублированном контенте, и многие блогеры вздохнут с облегчением.
Хорошая новость, в конце мая 2011г. Яндекс стал учитывать атрибут rel=»canonical». Принесет это облегчение или нет, покажет время.
Which search engine supports which robots meta tag values?
This table shows which search engines support which values. Note that the documentation provided by some search engines is sparse, so there are many unknowns.
| Robots value | Yahoo | Bing | Ask | Baidu | Yandex | |
|---|---|---|---|---|---|---|
| Indexing controls | ||||||
| index | Y* | Y* | Y* | ? | Y | Y |
| noindex | Y | Y | Y | ? | Y | Y |
| noimageindex | Y | N | N | ? | N | N |
| Whether links should be followed | ||||||
| follow | Y* | Y* | Y* | ? | Y | Y |
| nofollow | Y | Y | Y | ? | Y | Y |
| none | Y | ? | ? | ? | N | Y |
| all | Y | ? | ? | ? | N | Y |
| Snippet/preview controls | ||||||
| noarchive | Y | Y | Y | ? | Y | Y |
| nocache | N | N | Y | ? | N | N |
| nosnippet | Y | N | Y | ? | N | N |
| nositelinkssearchbox | Y | N | N | N | N | N |
| nopagereadaloud | Y | N | N | N | N | N |
| notranslate | Y | N | N | ? | N | N |
| max-snippet: | Y | Y | N | N | N | N |
| max-video-preview: | Y | Y | N | N | N | N |
| max-image-preview: | Y | Y | N | N | N | N |
| Miscellaneous | ||||||
| rating | Y | N | N | N | N | N |
| unavailable_after | Y | N | N | ? | N | N |
| noodp | N | Y** | Y** | ? | N | N |
| noydir | N | Y** | N | ? | N | N |
| noyaca | N | N | N | N | N | Y |
* Most search engines have no specific documentation for this, but we’re assuming that support for excluding parameters (e.g., ) implies support for the positive equivalent (e.g., ).** Whilst the noodp and noydir attributes may still be ‘supported’, these directories no longer exist, and it’s likely that these values do nothing.
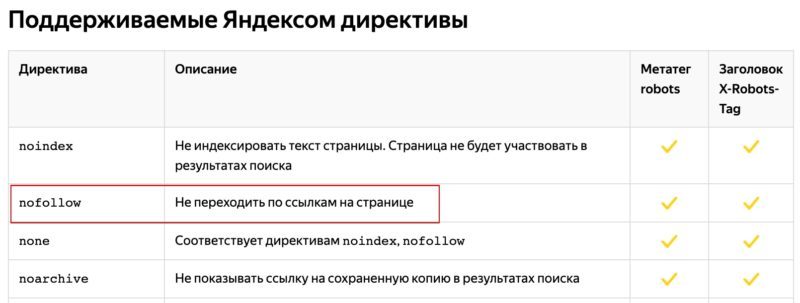
Утекает ли вес ссылки через nofollow?
А вот с Яндексом вопрос не явный. Он четко пишет в своей документации, что данный атрибут запрещает индексацию таких ссылок.

А если мы перейдем в описание атрибута robots nofollow, то здесь уже видим запрет на переход, и не слово про индексацию.
Но, раньше можно было это проверить, если применить в поиске такую конструкцию url: ваш урл << inlink:(“анкор ссылки”), и Яндекс нам отображал только те страницы, где содержится наш искомый анкор ссылки. Сейчас же этот метод не работает, поисковая система Яндекс запретила использовать такую конструкцию в поиске. Поэтому можно с большей долью вероятностью сказать, что Яндекс может учитывать такие ссылки, потому что они появляются в Яндекс Вебмастер.
Видно, например, что Яндекс учитывает ссылки с Твиттера, даже если они отдаются через редирект и закрыты nofollow.
В целом можно сказать, что применение данного атрибута для поисковых роботов не всегда является запретом, если особенно сайт авторитетный.
Как общаться с технической поддержкой о мета-тегах
Чтобы не тратить зря время, не упоминайте расширение ПРОДЗЕН и термины «красная рожица», «грустная мордочка», «значок робота» и т.п.
Сотрудники ТП не могут комментировать то, как работает расширение, не знают и не должны знать, что оно показывает и т.п. Поэтому упомянув расширение, вы гарантированно получите отказ его обсуждать, иногда даже с советом его не использовать.
Не ссылайтесь только лишь на наличие самого мета-тега.
Если статья новая и не получает показов — так и напишите.
Если публикация опубликована больше суток назад, успешно набирала просмотры, а потом внезапно получила мета-тег, посмотрите график конкретной статьи в метрике — там будет видно, что в какой-то момент резко прекратились просмотры. Приведите скриншот этого графика.
Т.е. основным в вашем письме должно быть то, что возникли проблемы с публикацией. Про мета-тег можно вообще не упоминать, или упоминать в качестве дополнения.
К сожалению, это может не помочь. Если менеджеры, помогающие участникам программы Нирвана, ещё готовы разбираться с проблемами, то сотрудники обычной поддержки очень часто начинают писать стандартные отписки, не сильно вникая в их смысл.
Иногда можно подождать, пока ваше обращение будет отмечено как завершённое и написать ещё раз — если повезёт, вам ответит сотрудник, настроенный как-то помочь вам.
Так же можно обратиться за помощью в официальные группы Дзена в ВК или в телеграме.
Если ничего добиться не удастся, то остаётся только грустить вместе с грустным роботом.
Meta Robots Tag Code Examples
If you’re looking for meta robots tag examples that you can use to control how the search engines crawl and index your web pages, you can use the below that looks at the most common use scenarios:
Do not index the page but follow the links to other pages:
Do not index the page and do not follow the links to other pages:
Index the page but do not follow the links to other pages:
Do not show a copy of the page cache on the SERPs:
Do not index the images on a page:
Do not show the page on the SERPs after a specified date/time:
If needed, you can combine directives into a single tag, separating these with commas.
As an example, let’s say you don’t want any of the links on a page to be followed and also want to prevent the images from being indexed. Use:
Пошаговый алгоритм работы с сервисом:
Создание задачи.
1. Чтобы создать задачу, необходимо перейти во вкладку Мета сканер и нажать кнопку «Создать новую задачу»:
2. Шаг первый: Название задачи.
Здесь необходимо ввести название задачи (обязательное поле) и добавить домен сайта, страницы которого вы хотите отслеживать.
Затем выберите тип оповещений. Активировав данную опцию, вы будете получать письма с уведомлениями об изменениях на сайте на указанную в вашем аккаунте почту
Обратите внимание, что для получения этого письма, вы должны быть подписаны на получение рассылки “уведомлений”. Это можно проверить в настройках на странице “Мой аккаунт”
Выберите «Все», если хотите чтобы на почту пришло уведомление об изменениях во всех зонах
Если Вам важно отслеживать изменения только в одной или нескольких зонах, а остальные не интересны — отметьте их галочкой
Далее выберите интервал проверки.
Интервалы:
- Ежедневно — задача будет обновляться ежедневно
- Еженедельно — задача будет обновляться раз в неделю
- Раз в месяц — задача будет обновляться раз в месяц
- В ручном режиме — задача будет обновляться только при ручном запуске
3. Шаг второй: Настройки сканирования
На этом шаге можно выбрать через какой USER AGENT хотите сканировать ваш сайт.
Вторая настройка на этом шаге — это игнорирование числовых значений.
Если на вашем сайте в мета-теги автоматически подставляются числовые параметры (например, цена или количество товаров) и вы не считаете это важными изменениями — включите эту опцию и наши роботы будут игнорировать такие изменения.
Пример: если цена в теге Title изменится с 999 на 1000, то вы не получите уведомление об этом изменении в Title
4.Шаг третий: URL и цена. Загружаем URL.
Можно загрузить списком, с помощью sitemap либо через файл. Поддерживаемые форматы файла: xls, xlsx. Необходимо указать столбец, из которого должны браться данные, а также учитывать или нет первую строку:
К каждому из добавленных URL можно добавить текст со страницы, который будет отслеживаться Мета сканером (максимальная длина текста составляет 256 символов).
Затем нажимаем «Запустить задачу»:
Для чего нужны теги, запрещающие индексацию
Как я писал выше, тег Noindex вообще ни для чего не нужен. Он себя давно изжил. А вот метатег роботс — довольно нужная вещь. Вот примеры ситуаций, когда он бывает полезен:
- На сайте есть какая-то страница, которую бы вы не хотели видеть в индексе. Например, страница с информацией для рекламодателей. А прописывать в роботсе по каким-то причинам не хотите (например, хотите скрыть её от оптимизаторов, которые лазят по чужим роботсам). Тогда вы просто парой щелчков через плагин ставите ноиндекс для этой страницы;
- Поскольку мета тег роботс имеет приоритет перед robots.txt, можно запретить индексирование какой-либо страницы, которая находится в директории, разрешенной для индексации.
Robots.txt & Meta Robots Tags Work Together
One of the biggest mistakes I see when working on my client’s websites is when the robots.txt file doesn’t match what you’ve stated in the meta robots tags.
For example, the robots.txt file hides the page from indexing, but the meta robots tags do the opposite.
Remember the example from Leadfeeder I showed above?
So, you’ll notice that this thank you page is disallowed in the robots.txt file and using the meta robots tags of noindex, nofollow.
In my experience, Google has given priority to what is prohibited by the robots.txt file.
But, you can eliminate non-compliance between meta robots tags and robots.txt by clearly telling search engines which pages should be indexed, and which should not.
Правила для конкретных поисковых систем
Иногда вам может потребоваться предоставить конкретные инструкции для конкретной поисковой системы, исключая других роботов. Или вы можете составить совершенно разные инструкции для разных поисковых систем.
В этих случаях вы можете изменить значение content атрибута для конкретной поисковой системы (например, googlebot для Google или yandex для Яндекс).
Примечание. Учитывая, что поисковые системы будут просто игнорировать инструкции, которые они не поддерживают или не понимают, очень редко нужно использовать несколько тегов мета-роботов для установки инструкций для определенных сканеров.
Тег и как его применять
Тег — это структурная единица HTML разметки, а все что внутри, называют содержанием элемента.
Что такое тег <noindex>?
<noindex> — тег, который используется для закрытия определенных участков текста. Контент внутри будет недоступен для индексации поисковыми системами, такими как Yandex и Rambler. То есть, с его помощью, мы запрещаем боту сканировать часть контента. Эту конструкцию правильно использовать внутри <body></body> в таком виде:
<noindex>нас не увидят</noindex>
Важно помнить: не стандартизирован компанией Google и не относится к официальной разметке HTML. Поэтому, будет вызывать ошибки в коде
Так как Google этот тег не знает, то и скрыть контент от индексации не сможет.
Валидность HTML сохраняется с использованием специальной конструкции:
<!--noindex-->Мы спрятались 0_0<!--/noindex-->
Когда использовать?
На тот случай, когда мы не хотим затрагивать основной контент страницы, а только скрыть определенные служебные участки текста. Тогда на помощь приходить тег который не разрешит поисковикам добавить выбранный участок в индексную базу.
“А смысл нам что-то скрывать?” — спросите вы.
А поисковый робот ответит: “Берегите уникальность своего контента и это вернется вам высокими позициями в выдаче”.
Поисковые системы любят сайты с уникальным наполнением и за это благодарят их высокими позициями в выдаче. На ранжирование влияет ряд негативных факторов:
- выдержки из законодательства;
- цитирование чужих авторов;
- служебный контент на вашем ресурсе;
- периодически дублирующий текст;
- сохранить контент от переспама ключевыми словами для Yandex и Rambler.
Распространенные ошибки
Мы рассмотрели разные способы закрытия от индексации, но сложности встречаются у каждого пути. Давайте рассмотрим самые популярные из них.
Неправильные способы закрытия от индексации:
- пользоваться тегом <noindex> и забыть, что только Yandex его распознает, а для Google контент будет полностью проиндексирован.
- пытаться удалить сайт из index с помощью Disallow в robots.txt. Да, к вам поисковый робот больше не зайдет, но и из поиска никуда не денется. Для полного удаления из index, воспользуйтесь Google Search Console.
- пытаться удалить страницу сайта из index с помощью robots.txt + мета-тега robots. Мы закрыли страницу от сканирования роботами, но она уже находится в index. При следующем сканировании они не смогут зайти на ресурс и увидеть мета-тег, чтобы убрать его из index. По итогу она так и останется видимой для поисковой системы.
Как этого избежать?
После прочтения данной статьи:
Определите что именно вам нужно скрыть
Это может быть директория, документ или часть контента.
Четко под свои задачи, выберите нужный способ решения.
Перечитайте о нем более детально в этой статье и возьмите во внимание нюансы использования и внедрения.
Итоги — или что сделать, чтобы стало все круто?
Наконец-то я могу подвести итог сегодняшнего огромного поста, и он будет кратким.
Чтобы улучшить качество индексации сайта, необходимо:
- Скрыть от гостей (к ним относятся и роботы) ссылки, которые им не нужны или не предназначены.
- Ссылки, которые нельзя удалить или спрятать от живых посетителей, стоит скрыть и выводить через JavaScript.
- Если ничего из перечисленного невозможно или не получается, то хотя бы необходимо закрыть ссылки на ненужные страницы атрибутом rel=”nofollow”. Хоть польза от этого и сомнительная, но все же…
- Страницы, которые не должны быть проиндексированы и не должны попасть в индекс поисковых систем, стоит запрещать при помощи метатега robots и параметра noindex:
- Страницы, содержащие тег robots не должны быть запрещены к индексации через robots.txt
Что даст нам весь этот «улучшайзинг»:
- Во-первых, чистота индекса сайта, что в наше время очень редко и почти не встречается.
- Во-вторых, быстрота индексации/переиндексации сайта увеличится за счет того, что робот не будет загружать страницы, которые закрыты для него.
- В-третьих, сохранится какая-то часть статического веса сайта, которая раньше утекала по ссылкам на закрытые страницы, а это может положительно отразится на ранжировании сайта.
- В-четвертых, это просто круто и говорит об уровне профессионализма вебмастера.
Фуф, два дня (а точнее — две ночи) писал этот пост и никак не мог дописать, но я это сделал! Потому жду ваших отзывов и комментариев.
Если у кого-то есть практический опыт по теме, обязательно поделитесь им со мной и другими читателями, это будет очень интересно и полезно.
Всем спасибо за внимание и до скорой встречи!