Postgresql
Содержание:
Postgres на Linux и Postgres на Windows: что лучше
Сами удивились, сами себя похвалили, какие мы молодцы, что 5 лет назад сделали крутой выбор. Но встречаем очень часто вопрос: стоит ли переходить на Postgres.10 на Windows.
Тот самый злополучный баг Postgres, когда система замирала на 15 секунд из-за недоступности файла статистика исправлен в версии Postgres 10.4.1. Говорю об этом отдельно, потому что эта версия на данный момент 1С не поддерживается. Она есть только на сайте Postgres Pro, мы ее поставили и запустили ради этой конференции. Что получили? При 10 потоках все почти одинаково, что на Postgres версии 9, что на Postgres версии 10. При 20 потоках Postgres.10 в 3 раза быстрее. Я бы даже сказал иначе: Postgres.9 на Windows в 3 раза медленнее, потому что возникает та самая блокировка, замирание на 15 секунд. Причем, оно рандомное, то есть вы не угадаете, это будут замирания один раз в минуту или у вас будет секунда работы, 15 секунд замирание и так тысячу раз.

При 50 потоках Postgres.9 медленнее в 11 раз. При 100 потоках мы не дождались завершения операции. Данные я не привожу. Нам надоело: мы неделю ждали.
Второй самый популярный вопрос, стоит ли переходить на Linux? Да, стоит переходить! По нашим данным, а они у нас достаточно релевантные – 15 терабайт и 400 баз, Postgres работает почти в 2 раза быстрее.

Почему? Не потому что Postgres такой плохой на Windows, а потому что файловая система Windows не способна обрабатывать такое большое количество файлов. Тут вся фишка в том, как Postgres и MS хранят файлы. Если MS хранит по умолчанию всю вашу базу данных в двух файлах (это файл данных mdf и файл журнала транзакций lgf), то Postgres хранит каждую таблицу в отдельном файле и каждый индекс в отдельном файле.
Типовая база бухгалтерии содержит 6 тысяч таблиц и 20 тысяч индексов. Значит, одна база будет в Postgres представлена 26 тысячами файлов. На наших серверах мы примерно делаем по 60 баз на один instant Postgres, это в районе 2 миллионов файлов. С таким количеством файлов Linux управляется, как мы видим, почти в 2 раза быстрее, чем Windows.
Поэтому если вы уже всерьез на Postgres, а всерьез – это наличие хотя бы 20 сессий, начинайте подумывать о переходе на Linux. Причем, не обязательно железный, можете на этой же винде, если сильно страшно, то поднимите hyper-v, поднимите виртуалку, на эту виртуалку ставьте Linux, ставьте Postgres, и получите отличный эффект. Проверено!
Типы данных
Один из основных моментов обоих баз данных это поддерживаемые типы данных, которые вы можете использовать. Поскольку оба решения пытаются соответствовать синтаксису SQL, то они имеют похожие наборы, но все же кое-чем отличаются.
MySQL
MySQL поддерживает такие типы данных:
- TINYINT: очень маленькое целое.;
- SMALLINT: маленькое целое;
- MEDIUMINT: целое среднего размера;
- INT: целое нормального размера;
- BIGINT: большое целое;
- FLOAT: знаковое число с плавающей запятой одинарной точности;
- DOUBLE, DOUBLE PRECISION, REAL: знаковое число с плавающей запятой двойной точности
- DECIMAL, NUMERIC: знаковое число с плавающей запятой;
- DATE: дата;DATETIME: комбинация даты и времени;
- TIMESTAMP: отметка времени;
- TIME: время;YEAR: год в формате YY или YYYY;
- CHAR: строка фиксированного размера, дополняемая справа пробелами до максимальной длины;
- VARCHAR: строка переменной длины;
- TINYBLOB, TINYTEXT: двоичные или текстовые данные максимальной длиной 255 символов;
- BLOB, TEXT: двоичные или текстовые данные максимальной длиной 65535 символов;
- MEDIUMBLOB, MEDIUMTEXT: текст или двоичные данные;
- LONGBLOB, LONGTEXT: текст или двоичные максимальной данные длиной 4294967295 символов;
- ENUM: перечисление;
- SET: множества.
Postgresql
Поддерживаемые типы полей в Postgresql достаточно сильно отличаются, но позволяют записывать точно те же данные:
- bigint: знаковое 8-байтовое целое;
- bigserial: автоматически увеличиваемое 8-байтовое целое;
- bit: двоичная строка фиксированной длины;
- bit varying: двоичная строка переменной длины;
- boolean: флаг;
- box: прямоугольник на плоскости;
- byte: бинарные данные;
- character varying: строка символов фиксированной длины;
- character: строка символов переменной длины;
- cidr: сетевой адрес IPv4 или IPv6;
- circle: круг на плоскости;
- date: дата в календаре;
- double precision: число с плавающей запятой двойной точности;
- inet: адрес интернет IPv4 или IPv6;
- integer: знаковое 4-байтное целое число;
- interval: временной промежуток;
- line: бесконечная прямая на плоскости;
- lseg: отрезок на плоскости;
- macaddr: MAC-адрес;
- money: денежная величина;
- path: геометрический путь на плоскости;
- point: геометрическая точка на плоскости;
- polygon: многоугольник на плоскости;
- real: число с плавающей точкой одинарной точности;
- smallint: двухбайтовое целое число;
- serial: автоматически увеличиваемое четырехбитное целое число;
- text: строка символов переменной длины;
- time: время суток;
- timestamp: дата и время;
- tsquery: запрос текстового поиска;
- tsvector: документ текстового поиска;
- uuid: уникальный идентификатор;
- xml: XML-данные.
Как видите, типов данных в Postgresql больше и они более разнообразны, есть свои типы полей для определенных видов данных, которых нет MySQL. Отличие MySQL от Postgresql очевидно.
Разработка
PostgreSQL развивается силами международной группы разработчиков (PGDG), в которую входят как непосредственно программисты, так и те, кто отвечают за продвижение PostgreSQL (Public Relation), за поддержание серверов и сервисов, написание и перевод документации, всего на 2005 год насчитывается около 200 человек. Другими словами, PGDG — это сложившийся коллектив, который полностью самодостаточен и устойчив. Проект развивается по общепринятой среди открытых проектов схеме, когда приоритеты определяются реальными нуждами и возможностями. При этом, практикуется публичное обсуждение всех вопросов в списке рассылке, что практически исключает возможность неправильных и несогласованных решений.
Это относится и к тем предложениям, которые уже имеют или рассчитывают на финансовую поддержку коммерческих компаний.
Цикл работой над новой версией обычно длится 10-12 месяцев (сейчас ведется дискуссия о более коротком цикле 2-3 месяца) и состоит из нескольких этапов.
Архитектура PostgreSQL
Одной из наиболее сильных сторон СУБД PostgreSQL является архитектура. Как и в случаях со многими коммерческими СУБД, PostgreSQL можно применять в среде клиент-сервер — это предоставляет множество преимуществ и пользователям, и разработчикам.
В основе PostgreSQL — серверный процесс базы данных, выполняемый на одном сервере. Также стоит сказать, что в Postgres пока не реализована технология высокой готовности, как это сделано в ряде других коммерческих систем управления базами данных уровня предприятия (они способны распределять нагрузку между некоторым количеством серверов, достигая дополнительной масштабируемости и повышенной устойчивости к внешним воздействиям).
Доступ из приложений к данным базы PostgreSQL производится с помощью специального процесса базы данных. То есть клиентские программы не могут получать самостоятельный доступ к данным даже в том случае, если они функционируют на том же ПК, на котором осуществляется серверный процесс.
Таким образом мы получаем разделение клиентов и сервера, что даёт возможность создавать распределённые системы. К примеру, мы можем отделить клиентов от сервера с помощью сети, разрабатывая клиентские приложения в среде, которая удобна для пользователя. Допустим, появляется возможность реализовать базу данных под UNIX, создав клиентские приложения, которые станут работать в ОС Microsoft Windows.
Давайте посмотрим на типичную модель распределенного приложения СУБД PostgreSQL:
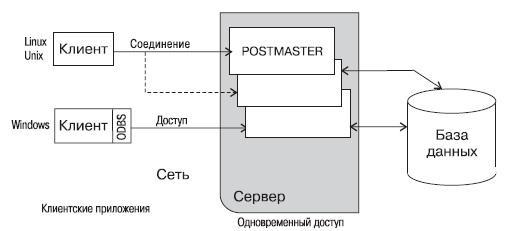
Мы видим, что несколько клиентов подсоединены к серверу по сети. СУБД PostgreSQL ориентирована на протокол TCP/IP (локальная сеть либо Интернет), при этом каждый клиент соединён с главным серверным процессом БД (на схеме этот процесс называют Postmaster). Именно Postmaster создаёт новый серверный процесс специально в целях обслуживания запросов на доступ к данным определённого клиента.
Так как манипулирование с данными сосредотачивается на сервере, СУБД PostgreSQL не приходится контролировать многочисленных клиентов, которые получают доступ в совместно используемый серверный каталог. В результате база данных PostgreSQL способна поддерживать целостность данных даже в случае одновременного доступа большого числа пользователей.
Соединение с базой данных клиентских приложений осуществляется по специальному протоколу СУБД PostgreSQL. В принципе, никто не мешает инсталлировать на стороне клиента ПО, предоставляющее стандартный интерфейс, обеспечивающий работу с нужным приложением, допустим, по стандарту ODBC/JDBC. И это хорошо, ведь доступность ODBC-драйвера даёт возможность использовать СУБД PostgreSQL в качестве базы данных для множества уже существующих приложений, включая продукты Microsoft Office — Excel и Access.
Идём дальше. Клиент-серверная архитектура, реализованная в СУБД PostgreSQL, делает возможным разделение труда. То есть машина-сервер прекрасно подходит для хранения и управления доступом к огромным объёмам данных, то есть её можно использовать в качестве надёжного репозитория. При этом для клиентов возможна разработка сложных графических приложений. Также можно создать внешний онлайн-интерфейс, предоставляющий доступ к данным и возвращающий результат в виде web-страниц в стандартный web-браузер, не требуя при этом никакого дополнительного клиентского ПО.
Compatibility
This command conforms to the SQL standard, except that the FROM and RETURNING
clauses are PostgreSQL
extensions, as is the ability to use WITH with UPDATE.
According to the standard, the column-list syntax should allow
a list of columns to be assigned from a single row-valued
expression, such as a sub-select:
UPDATE accounts SET (contact_last_name, contact_first_name) =
(SELECT last_name, first_name FROM salesmen
WHERE salesmen.id = accounts.sales_id);
This is not currently implemented — the source must be a list
of independent expressions.
Some other database systems offer a FROM option in which the target table is supposed
to be listed again within FROM. That is
not how PostgreSQL interprets
FROM. Be careful when porting
applications that use this extension.
История успеха «Яндекс.Почты» с PostgreSQL
Владимир Бородин (на «Хабре» dev1ant), системный администратор группы эксплуатации систем хранения данных в «Яндекс.Почте», знакомит со сложностями миграции крупного проекта с Oracle Database на PostgreSQL. Это — расшифровка доклада с конференции HighLoad++ 2016.
Всем привет! Меня зовут Вова, сегодня я буду рассказывать про базы данных «Яндекс.Почты».
Сначала несколько фактов, которые будут иметь значение в будущем. «Яндекс.Почта» — сервис достаточно старый: он был запущен в 2000 году, и потому мы накопили много legacy. У нас — как это принято и модно говорить — вполне себе highload-сервис, больше 10 миллионов пользователей в сутки, какие-то сотни миллионов всего. В бэкенд нам прилетает более 200 тысяч запросов в секунду в пике. Мы складываем более 150 миллионов писем в сутки, прошедших проверки на спам и вирусы. Суммарный объём писем за все 16 лет — больше 20 петабайт.
О чем пойдет речь? О том, как мы перевезли метаданные из Oracle в PostgreSQL. Метаданных там не петабайты — их чуть больше трехсот терабайт. В базы влетает более 250 тысяч запросов в секунду. Надо иметь в виду, что это маленькие OLTP-запросы, по большей части чтение (80%).
Это — не первая наша попытка избавиться от Oracle. В начале нулевых была попытка переехать на MySQL, она провалилась. В 2007 или 2008 была попытка написать что-то своё, она тоже провалилась. В обоих случаях был провал не столько по технически причинам, сколько по организационным.
История
PostgreSQL создана на основе некоммерческой СУБД Postgres, разработанной как open-source проект в Калифорнийском университете в Беркли. К разработке Postgres, начавшейся в 1986 году, имел непосредственное отношение Майкл Стоунбрейкер, руководитель более раннего проекта Ingres, на тот момент уже приобретённого компанией Computer Associates. Название расшифровывалось как «Post Ingres», и при создании Postgres были применены многие уже ранее сделанные наработки.
Стоунбрейкер и его студенты разрабатывали новую СУБД в течение восьми лет с 1986 по 1994 год. За этот период в синтаксис были введены процедуры, правила, пользовательские типы и другие компоненты. В 1995 году разработка снова разделилась: Стоунбрейкер использовал полученный опыт в создании коммерческой СУБД Illustra, продвигаемой его собственной одноимённой компанией (приобретённой впоследствии компанией Informix), а его студенты разработали новую версию Postgres — Postgres95, в которой язык запросов POSTQUEL — наследие Ingres — был заменен на SQL.
Разработка Postgres95 была выведена за пределы университета и передана команде энтузиастов. Новая СУБД получила имя, под которым она известна и развивается в текущий момент — PostgreSQL.
Microsoft Access
for TT in $(mdb-tables file.mdb); do
mdb-export -Q -d '\t' -D '%Y-%m-%d %H:%M:%S' file.mdb "$TT" > "${TT}.tsv"
done
for TT in $(mdb-tables file.mdb); do
mdb-export -D '%Y-%m-%d %H:%M:%S' file.mdb "$TT" > "${TT}.csv"
done
If the tablenames have embedded spaces…
mdb-tables -1 file.mdb| while read TT
do
mdb-export -D '%Y-%m-%d %H:%M:%S' file.mdb "$TT" > "${TT}.csv"
done
A shell script that may be useful for converting entire databases:
#!/bin/sh -e
mdbfn=$1
schemafn=$2
fkfn=$3
datafn=$4
schema=$5
tf=$(tempfile)
pre=""
&& pre="\"${schema}\"."
mdb-schema "${mdbfn}" postgres > "${tf}"
# Schema file
echo "BEGIN;\n" > "${schemafn}"
sp=""
&& echo "CREATE SCHEMA \"${schema}\";\n" >> "${schemafn}"
&& sp="SET search_path = \"${schema}\", pg_catalog;\n"
echo ${sp} >> "${schemafn}"
awk '($0 !~ /^ALTER TABLE.*FOREIGN KEY.*REFERENCES/) {print;}' "${tf}" >> "${schemafn}"
echo "\nEND;" >> "${schemafn}"
# Foreign keys file
echo "BEGIN;\n" > "${fkfn}"
echo ${sp} >> "${fkfn}"
awk '($0 ~ /^ALTER TABLE.*FOREIGN KEY.*REFERENCES/) {print;}' "${tf}" >> "${fkfn}"
echo "\nEND;" >> "${fkfn}"
# Data file
echo "BEGIN;\n" > "${datafn}"
echo "SET CONSTRAINTS ALL DEFERRED;\n" >> "${datafn}"
mdb-tables -1 "${mdbfn}" | while read TT
do
mdb-export -Q -d '\t' -D '%Y-%m-%d %H:%M:%S' "${mdbfn}" "$TT" > "${tf}"
awk -v pre="${pre}" -v TT="${TT}" \
'(NR==1) {gsub(/\t/,"\",\""); print "COPY " pre "\"" TT "\"(\"" $0 "\") FROM stdin;";}' "${tf}" >> "${datafn}"
awk '(NR>1) {gsub(/\t\t/,"\t\\N\t"); gsub(/\t$/,"\t\\N"); gsub(/\t\t/,"\t\\N\t"); print;}' "${tf}" >> "${datafn}"
echo "\\.\n" >> "${datafn}"
done
echo "END;" >> "${datafn}"
rm -f "${tf}"
If this script is saved to the file access2psql.sh and made executable, then it would be used as follows:
access2psql.sh file.mdb schema.sql foreignkeys.sql data.sql pg_schema_name psql -f schema.sql pg_db_name psql -f data.sql pg_db_name psql -f foreignkeys.sql pg_db_name
This script won’t work properly if there are tab characters in text columns, though the call to mdb-export could be modified to export INSERT statements to fix this. Also, mdb-schema has trouble representing multi-column foreign keys, so foreignkeys.sql may need some manual editing.
- Microsoft Access to PostgreSQL Conversion by Jon Hutchings (2001-07-20)
Uber — причины перехода с Postgres на MySQL
Перевод
В конце июля 2016 года в корпоративном блоге Uber появилась поистине историческая статья о причинах перехода компании с PostgreSQL на MySQL. С тех пор в жарких обсуждениях этого материала было сломано немало копий, аргументы Uber были тщательно препарированы, компанию обвинили в предвзятости, технической неграмотности, неспособности эффективно взаимодействовать с сообществом и других смертных грехах, при этом по горячим следам в Postgres было внесено несколько изменений, призванных решить некоторые из описанных проблем. Список последствий на этом не заканчивается, и его можно продолжать еще очень долго.
Наверное, не будет преувеличением сказать, что за последние несколько лет это стало одним из самых громких и резонансных событий, связанных с СУБД PostgreSQL, которую мы, к слову сказать, очень любим и широко используем. Эта ситуация наверняка пошла на пользу не только упомянутым системам, но и движению Free and Open Source в целом. При этом, к сожалению, русского перевода статьи так и не появилось. Ввиду значимости события, а также подробного и интересного с технической точки зрения изложения материала, в котором в стиле «Postgres vs MySQL» идет сравнение физической структуры данных на диске, организации первичных и вторичных индексов, репликации, MVCC, обновлений и поддержки большого количества соединений, мы решили восполнить этот пробел и сделать перевод оригинальной статьи. Результат вы можете найти под катом.
Стандарт SQL
Независимо от используемой системы управления базами данных, SQL — это стандартизированный язык выполнения запросов. И он поддерживается всеми решениями, даже MySQL или Postgresql. Стандарт SQL был разработан в 1986 году и за это время уже вышло нескольких версий.
MySQL
MySQL поддерживает далеко не все новые возможности стандарта SQL. Разработчики выбрали именно этот путь развития, чтобы сохранить MySQL простым для использования. Компания пытается соответствовать стандартам, но не в ущерб простоте. Если какая-то возможность может улучшить удобство, то разработчики могут реализовать ее в виде своего расширения не обращая внимания на стандарт.
Postgresql
Postgresql — это проект с открытым исходным кодом, он разрабатывается командой энтузиастов, и разработчики пытаются максимально соответствовать стандарту SQL и реализуют все самые новые стандарты. Но все это приводит к ущербу простоты. Postgresql очень сложный и из-за этого он не настолько популярен как MySQL.
Преимущества и особенности СУБД PostgreSQL
СУБД PostgreSQL использует для своих баз данных реляционную модель, поддерживая стандартный язык запросов SQL. При этом PostgreSQL предоставляет широкий спектр возможностей. Можно сказать, что Postgres обладает почти всеми возможностями, существующими в других базах данных (как коммерческих, так и Open Source), а также рядом дополнительных.
Сегодня СУБД PostgreSQL работает почти на всех UNIX-платформах, в том числе и на UNIX-подобных системах (FreeBSD и Linux). Вы сможете использовать эту базу данных и на Windows NT Server, и на Windows 2000 Server, и для разработки рабочих станций ME.
Рассмотрим краткий перечень преимуществ и функциональных возможностей СУБД PostgreSQL:
1. Надежность. Надёжность СУБД PostgreSQL проверена и доказана. Она обеспечивается соответствием принципам ACID (атомарность, изолированность, непротиворечивость, сохранность данных), многоверсионностью, наличием Write Ahead Logging (WAL) — общепринятого механизма протоколирования всех существующих транзакций. Сюда же стоит отнести и возможность восстановления базы данных Point in Time Recovery (PITR), репликацию, поддержку целостности данных на уровне схемы.
2. Производительность. В СУБД PostgreSQL она основана на применении индексов, наличии гибкой системы блокировок и интеллектуального планировщика запросов, использовании системы управления буферами памяти и кэширования. Не стоит забывать и про отличную масштабируемость при конкурентной работе.
3. Расширяемость. Для СУБД PostgreSQL это означает, что пользователь может настроить систему посредством определения новых функций, типов, языков, агрегатов, индексов и операторов. А объектная ориентированность СУБД PostgreSQL даёт возможность переносить логику приложения на уровень базы данных, а это, в свою очередь, заметно упрощает разработку клиентов, ведь вся бизнес-логика находится в БД. При этом функции в Postgres однозначно определяются названием, типами и числом аргументов.
4. Поддержка SQL. Её уже упоминали, однако кроме главных возможностей, которые присущи любой SQL-базе, PostgreSQL поддерживает схемы, подзапросы, внешние связки, правила, курсоры, наследование таблиц, триггеры и много чего ещё.
5. Поддержка многочисленных типов данных. СУБД PostgreSQL поддерживает численные (целые, денежные, с фиксированной/плавающей точкой), булевые, символьные, составные, сетевые типы данных, а также перечисление, типы «дата/время», геометрические примитивы, массивы, XML- и JSON-данные. Плюс можно создавать свои типы данных.
Конечно, это далеко не всё, но для общего понимания возможностей СУБД PostgreSQL вполне достаточно. Естественно, база данных заслуживает внимания, особенно если учесть, что она имеет открытый исходный код и распространяется свободно. Освоить эту СУБД вы cможете на курсе в OTUS.
Настройки на Master
В данной статье мы будем настраивать серверы с IP-адресами 192.168.1.10 (первичный или master) и 192.168.1.11 (вторичный или slave).
Переходим на сервер, с которого будем реплицировать данные (мастер) и выполняем следующие действия.
Создаем пользователя в PostgreSQL
Входим в систему под пользователем postgres:
su — postgres
Создаем нового пользователя для репликации:
createuser —replication -P repluser
* система запросит пароль — его нужно придумать и ввести дважды. В данном примере мы создаем пользователя repluser.
Выходим из оболочки пользователя postgres:
exit
Настраиваем postgresql
Смотрим расположение конфигурационного файла postgresql.conf командой:
su — postgres -c «psql -c ‘SHOW config_file;'»
В моем случае система вернула строку:
/etc/postgresql/9.6/main/postgresql.conf
* конфигурационный файл находится по пути /etc/postgresql/9.6/main/postgresql.conf.
Открываем конфигурационный файл postgresql.conf.
vi /etc/postgresql/9.6/main/postgresql.conf
* мы открываем файл, который получили sql-командой SHOW config_file;.
Редактируем следующие параметры:
listen_addresses = ‘localhost, 192.168.1.10’
wal_level = replica
max_wal_senders = 2
max_replication_slots = 2
hot_standby = on
hot_standby_feedback = on
* где
- 192.168.1.10 — IP-адрес сервера, на котором он будем слушать запросы Postgre;
- wal_level указывает, сколько информации записывается в WAL (журнал операций, который используется для репликации);
- max_wal_senders — количество планируемых слейвов;
- max_replication_slots — максимальное число слотов репликации (данный параметр не нужен для postgresql 9.2 — с ним сервер не запустится);
- hot_standby — определяет, можно или нет подключаться к postgresql для выполнения запросов в процессе восстановления;
- hot_standby_feedback — определяет, будет или нет сервер slave сообщать мастеру о запросах, которые он выполняет.
Открываем конфигурационный файл pg_hba.conf — он находитсяч в том же каталоге, что и файл postgresql.conf:
vi /etc/postgresql/9.6/main/pg_hba.conf
Добавляем следующие строки:
host replication repluser 127.0.0.1/32 md5
host replication repluser 192.168.1.10/32 md5
host replication repluser 192.168.1.11/32 md5
* данной настройкой мы разрешаем подключение к базе данных replication пользователю repluser с локального сервера (localhost и 192.168.1.10) и сервера 192.168.1.11.
Перезапускаем службу postgresql:
systemctl restart postgresql
* обратите внимание, что название для сервиса в системах Linux может различаться
Тестирование
В какой-то момент задумались, а может, нам страсть к Postgres на Linux застила глаза, и нам только кажется, что все хорошо работает. Решили попробовать подтвердить, что работает как минимум не хуже чем с MS SQL, а может быть, если и хуже-то, то совсем чуть-чуть.
На самом деле, когда приступали к нагрузочному тестированию, вся моя команда, скрестив пальчики думала, ладно, пусть Postgres проиграет, но проиграет не сильно. Все-таки он еще новенький, может быть, нами еще не до конца изученный, но очень активно развивается, и как рассказывал Олег Бартунов, будет очень много крутых фишек в версиях 10 в 11.

На момент организации нашего батла была версия 9. И мы решили, что площадкой для батла будет Windows 2012 R2. Почему Windows? Это для того чтобы соревнование было совсем честным, не учитывая операционные системы, просто проверка двух баз данных.
Итак, в красном углу ринга – заслуженный чемпион, обладатель всех поясов производительности 1С, имеющий любые регалии в мире 1С – Microsoft SQL server версия 2016, последняя поддерживаемая на данный момент.
В синем углу ринга – наш новичок, претендент, PostgreSQL. Он выступает сразу двумя бойцами, каждый бьется по очереди. Это Postgres 9.6 и Postgres 10. Обе версии на данный момент поддерживаются 1С.
Платформа взята последняя релизная на момент тестирования. Все сервера баз данных располагаются на одном и том же железе, это прямо одна и та же коробочка. Все настроено оптимально: и дисковые подсистемы, и процессор, и сервера баз данных (оптимально, согласно требованиям фирмы 1С и нашему опыту). Плюс к этому все настроено на многопользовательскую нагрузку, в том числе параллелизм отключен: и на MS SQL, и на Postgres стоят единички.
Понимание джойнов сломано. Это точно не пересечение кругов, честно
Так получилось, что я провожу довольно много собеседований на должность веб-программиста. Один из обязательных вопросов, который я задаю — это чем отличается INNER JOIN от LEFT JOIN.
Чаще всего ответ примерно такой: «inner join — это как бы пересечение множеств, т.е. остается только то, что есть в обеих таблицах, а left join — это когда левая таблица остается без изменений, а от правой добавляется пересечение множеств. Для всех остальных строк добавляется null». Еще, бывает, рисуют пересекающиеся круги.
Я так устал от этих ответов с пересечениями множеств и кругов, что даже перестал поправлять людей.
Дело в том, что этот ответ в общем случае неверен. Ну или, как минимум, не точен.
MySQL
Scripts, programs
Previously
# To install mysql2psql (under ubuntu 11.10): No need to get from github, just: sudo apt-get install ruby gems libmysqlclient-dev libpq-dev gem install mysql pg mysql2psql # To get info about the mysql socket: netstat -l | grep mysql mysql2psql # creates a .yml templae vi mysql2psql.yml # edit the template mysql2psql # connects to mysql database and write into postgres database
- Things to find out about when moving from MySQL to PostgreSQL by Joel Burton (8th April 2001)
- Why PostgreSQL Instead of MySQL: Comparing Reliability and Speed in 2007 by Greg Smith
- How to make a proper migration from MySQL to PostgreSQL
Архитектура PostgreSQL
Одной из сильных сторон PostgreSQL является ее архитектура. Как и многие коммерческие СУБД, PostgreSQL может применяться в среде клиент-сервер, что дает массу преимуществ как пользователям, так и разработчикам.
Основа PostgreSQL составляет серверный процесс базы данных. Он выполняется на одном сервере. (В этой СУБД еще не реализована технология высокой готовности, как в некоторых других коммерческих системах уровня предприятия, которые могут распределять нагрузку между несколькими серверами, добиваясь таким образом дополнительной масштабируемости и устойчивости к внешним воздействиям.)
Доступ из приложений к данным базы осуществляется посредством процесса базы данных. Клиентские программы не могут получить доступ к данным самостоятельно, даже если они работают на том же компьютере, на котором выполняется серверный процесс.
Такое разделение клиентов и сервера позволяет построить распределенную систему. Можно отделить клиентов от сервера посредством сети и разрабатывать клиентские приложения в среде, удобной для пользователя. Например, можно реализовать базу данных под UNIX и создать клиентские приложения, которые будут работать в системе Microsoft Windows.
Приведенная ниже схема (рис. 1) показывает типичную модель распределенного приложения PostgreSQL:

Рис. 1. Работа типичного приложения PostgreSQL
Несколько клиентов подсоединяются к серверу по сети. PostgreSQL ориентирован на протокол TCP/IP — это может быть локальная сеть или Интернет. Каждый клиент соединяется с основным серверным процессом базы данных (на схеме — Postmaster), который создает новый серверный процесс специально для обслуживания запросов на доступ к данным конкретного клиента.
Благодаря тому, что манипулирование данными сосредоточено на сервере, СУБД не приходится контролировать многочисленных клиентов, получающих доступ в совместно используемый каталог сервера, и PostgreSQL может поддерживать целостность данных даже при одновременном доступе большого количества пользователей.
Клиентские приложения соединяются с базой по специальному протоколу PostgreSQL. Однако можно установить на стороне клиента программное обеспечение, предоставляющее стандартный интерфейс для работы с нужным приложением, например, по стандарту ODBC или JDBC. Доступность ODBC-драйвера позволяет применять PostgreSQL в качестве базы данных для многих существующих приложений, включая такие продукты Microsoft Office, как Excel и Access. Способность взаимодействия PostgreSQL с приложениями будет подробнее рассмотрена в следующих главах.
Архитектура клиент-сервер делает возможным разделение труда. Машина-сервер хорошо подходит для хранения и управления доступом к большим объемам данных, она может использоваться как надежный репозитарий. Для клиентов могут быть разработаны сложные графические приложения. В качестве альтернативы можно создать внешний интерфейс на основе Интернета, который предоставлял бы доступ к данным и возвращал результат в виде веб-страниц в стандартный веб-браузер, при этом не требовалось бы никакого дополнительного клиентского программного обеспечения.
Работа с конфигурацией
Поиск и изменение расположения экземпляра кластера
Возможна ситуация, когда на одной операционной системе настроено несколько экземпляров PostgreSQL, которые «сидят» на различных портах. В этом случае поиск пути к физическому размещению каждого экземпляра — достаточно нервная задача. Для того, чтобы получить эту информацию, выполним следующий запрос для любой базы данных интересующего кластера:
Изменим расположение на другое с помощью команды:
Но для того, чтобы изменения вступили в силу, требуется перезагрузка.
Получим перечень доступных типов данных с помощью команды:
— имя типа данных. — размер типа данных.
Изменение настроек СУБД без перезагрузки
Настройки PostgreSQL находятся в специальных файлах вроде и . После изменения этих файлов нужно, чтобы СУБД снова получила настройки. Для этого производится перезагрузка сервера баз данных. Понятно, что приходится это делать, но на продакшн-версии проекта, которым пользуются тысячи пользователей, это очень нежелательно. Поэтому в PostgreSQL есть функция, с помощью которой можно применить изменения без перезагрузки сервера:
Но, к сожалению, она применима не ко всем параметрам. В некоторых случаях для применения настроек перезагрузка обязательна.
По материалам «10 Most Useful PostgreSQL Commands with Examples» и «15 Advanced PostgreSQL Commands with Examples»
Управление пользователями
В PostgreSQL используется концепция ролей. Одну роль можно рассматривать как отдельного пользователя или как группу пользователей. Роли могут владеть объектами БД и выдавать разрешения другим ролям.
По умолчанию была создана роль postgres. Давайте создадим еще одну роль. Для этого из консоли системы выполняем команду:
createuser -P --interactive
Система запросит имя для новой роли, пароль, а также позволит настроить привилегии — например, нужно ли давать права суперпользователя или разрешать создавать другие роли и базы данных.
Если вы уже зашли в psql, то создать новую роль можно командой:
CREATE ROLE имя_новой_роли WITH LOGIN CREATEDB CREATEROLE; // В конце обязательно ставим ;
Затем задаем пароль:
\password имя_роли
Вывести список всех ролей можно командой /du. Кроме имен отобразятся привилегии каждого роли.
Чтобы закрыть список ролей, выполняем команду q.
Для удаления пользователя выполняем команду:
DROP ROLE имя_роли;
Это можно также сделать из консоли системы с помощью команды:
drop user имя_роли
Чтоб сменить пароль пользователя, подключаемся к psql с правами суперпользователя. Затем выполняем следующую команду:
ALTER USER имя_роли WITH PASSWORD 'новый_пароль';
Эта операция сохраняется в файле .psql_history вместе с паролем, который не будет зашифрован. В качестве дополнительной меры безопасности эту запись рекомендуется удалить. Файл обычно находится в директории /var/lib/postgresql.