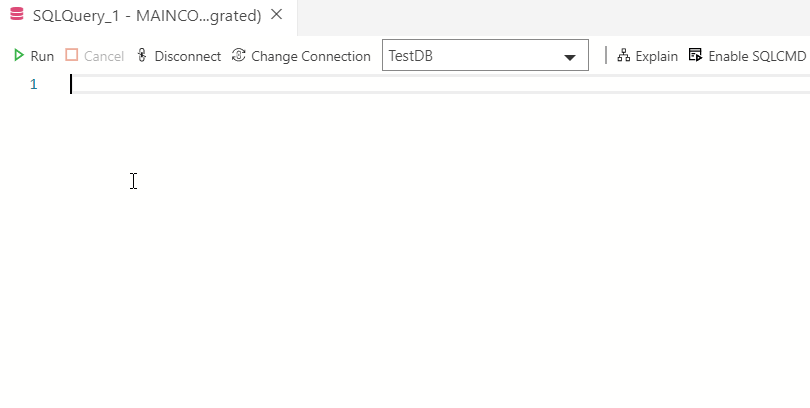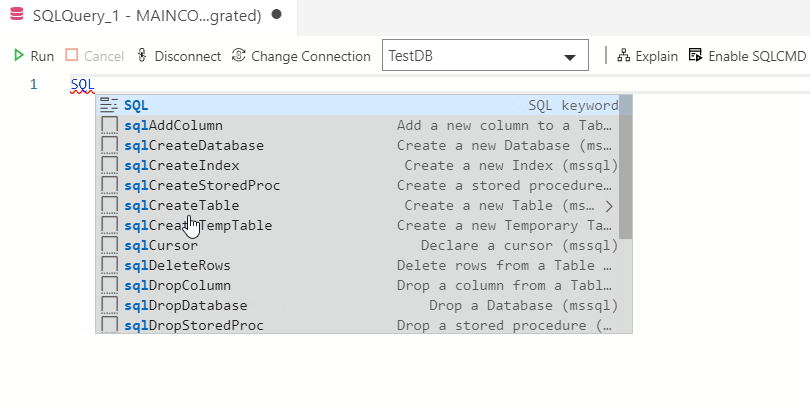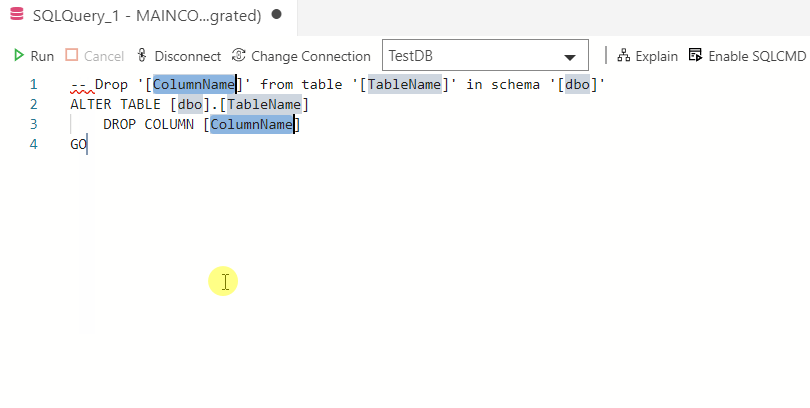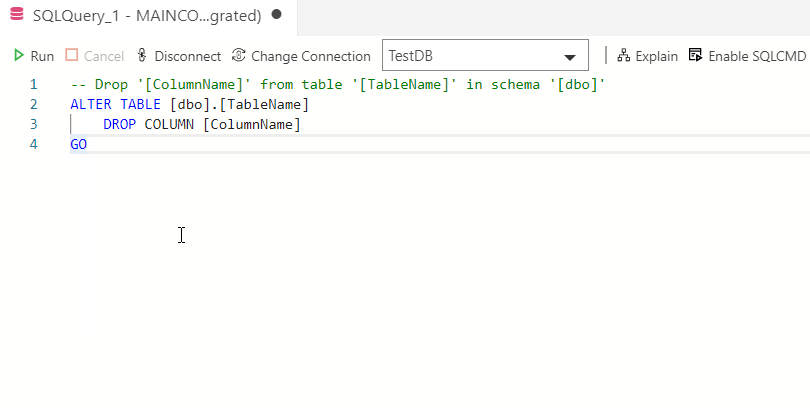
Типы баз данных
Содержание:
Рейтинг
Итак, рейтинг 10 наиболее популярных баз данных, согласно ресурсу DB-Engines, выглядит следующим образом:
- Oracle;
- MySQL;
- Microsoft SQL Server;
- PostgreSQL;
- MongoDB;
- DB2;
- Cassandra;
- Microsoft Access;
- Redis;
- SQLite.
Итого, 7 из 10 представителей рейтинга – реляционные базы данных, а также по одному экземпляру документоориентированной БД (MongoDB), с распределёнными значениями (Cassandra) и использующей подход «ключ-значение» (Redis). Таким образом, на сегодняшний день доминирование реляционных баз данных неоспоримо, но что будет завтра?
Для ответа на этот вопрос обратимся на этом же ресурсе к разделу тренды. Если брать отметки времени в более чем в 2 или 4 года, то наибольший рост демонстрирует подход с использованием теории графов. В то же время за последний год максимальный рост популярности продемонстрировали БД на основе временных данных. Это относительно новый подход, он также считается NoSQL, преимущество сводится к созданию структуры на основе дат или временных диапазонов. На данный момент наиболее популярным представителем Time Series БД является InfluxDB.
А какие базы данных используете вы? И какая на ваш взгляд наиболее перспективная NoSQL БД?
Как хранится информация в БД
В основе всей структуры хранения лежат три понятия:
- База данных;
- Таблица;
- Запись.
База данных
База данных — это высокоуровневное понятие, которое означает объединение совокупности данных, хранимых для выполнения одной цели.
Если мы делаем современный сайт, то все его данные будут храниться внутри одной базы данных. Для сайта онлайн-дневника наблюдений за погодой тоже понадобится создать отдельную базу данных.
Таблица
По отношению к базе данных таблица является вложенным объеком. То есть одна БД может содержать в себе множество таблиц.
Аналогией из реального мира может быть шкаф (база данных) внутри которого лежит множество коробок (таблиц).
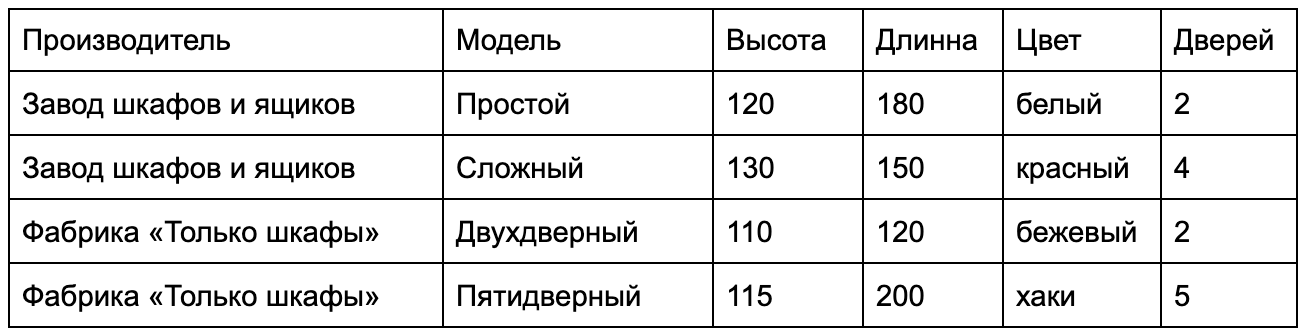
Таблицы нужны для хранения данных одного типа, например, списка городов, пользователей сайта, или библиотечного каталога.
Таблицу можно представить как обычный лист в Excel-таблице, то есть совокупность строк и столбцов.
Наверняка каждый хоть раз имел дело с электронными таблицами (MS Excel).
Заполняя такую таблицу, пользователь определяет столбцы, у каждого из которых есть заголовок. В строках хранится информация.
В БД точно также: создавая новую таблицу, необходимо описать, из каких столбцов она состоит, и дать им имена.
Запись
Запись — это строка электронной таблицы.
Это неделимая сущность, которая хранится в таблице. Когда мы сохраняем данные веб-формы с сайта, то на самом деле добавляем новую запись в какую-то из таблиц базы данных. Запись состоит из полей (столбцов) и их значений. Но значения не могут быть какими угодно.
Определяя столбец, программист должен указать тип данных, который будет храниться в этом столбце: текстовый, числовой, логический, файловый и т.д. Это нужно для того, чтобы в будущем в базу не были записаны данные неверного типа.
Соберем всё вместе, чтобы понять, как будет выглядеть ведение дневника погоды при участии базы данных.
- Создадим для сайта новую БД и дадим ей название «weather_diary».
- Создадим в БД новую таблицу с именем «weather_log» и определим там следующие столбцы:
- Город (тип: текст);
- День (тип: дата);
- Температура (тип: число);
- Облачность (тип: число; от 0 (нет облачности) до 4 (полная облачность));
- Были ли осадки (тип: истина или ложь);
- Комментарий (тип: текст).
- При сохранении формы будем добавлять в таблицу weather_log новую запись, и заполнять в ней все поля информацией из полей формы.
Теперь можно быть уверенными, что наблюдения наших пользователей не пропадут, и к ним всегда можно будет получить доступ.
Реляционная база данных
Английское слово „relation“ можно перевести как связь, отношение.
А определение «реляционные базы данных» означает, что таблицы в этой БД могут вступать в отношения и находиться в связи между собой.
Что это за связи?
Например, одна таблица может ссылаться на другую таблицу. Это часто требуется, чтобы сократить объём и избежать дублирования информации.
В сценарии с дневником погоды пользователь вводит название своего города. Это название сохраняется вместе с погодными данными.
Но можно поступить иначе:
- Создать новую таблицу с именем „cities“.
- Все города в России известны, поэтому их все можно добавить в одну таблицу.
- Переделать форму, изменив поле ввода города с текстового на поле типа «select», чтобы пользователь не вписывал город, а выбирал его из списка.
- При сохранении погодной записи, в поле для города поставить ссылку на соответствующую запись из таблицы городов.
Так мы решим сразу две задачи:
- Сократим объём хранимой информации, так как погодные записи больше не будут содержать название города;
- Избежим дублирования: все пользователи будут выбирать один из заранее определённых городов, что исключит опечатки.
Связи между таблицами в БД бывают разных видов.
В примере выше использовалась связь типа «один-ко-многим», так как одному городу может соответствовать множество погодных записей, но не наоборот!
Бывают связи и других типов: «один-к-одному» и «многие-ко-многим», но они используются значительно реже.
Избирательное и обязательное управление доступом
Система управления БД позволяет разграничить права доступа пользователей или, наоборот, объединить их в группы по признаку разрешенных однотипных действий.
Избирательное управление доступом включает:
1. Распределение доступа к данным – с БД можно работать группой или дать разрешение определенным сотрудникам на использование конкретных сведений.
2. Дополнительный учет данных при входе в систему (информация о том? кто, под какой учеткой, в какое время обращался к базе данных), аудите и изоляции отдельных сведений.
Свою «подлинность» сотрудник подтверждает при входе в БД логином и паролем. При аутентификации могут запрашиваться дополнительные сведения, например, ответ на секретный вопрос. После входа в систему пользователь может реализовать только права, предоставленные ему администратором (или владельцем БД) в зависимости от уровня доступа. Минимальные полномочия (уровень доступа) определяется должностными обязанностями сотрудника.
При обязательном управлении доступом данные классифицируются, например, «секретно», «совершенно секретно», «для общего пользования». Каждый пользователь имеет свой уровень доступа. Чаще всего подобная структура БД присуща правительственным или военным предприятиям. Получить необходимые сведения может только человек с уровнем допуска равным грифу данных или выше.
Таблица
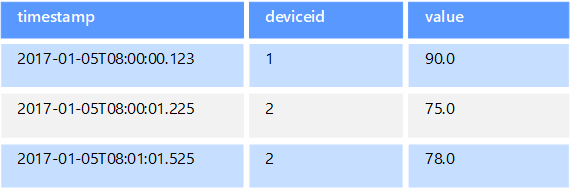
Таблица представляет собой структуру данных, которая организует информацию в строки и столбцы. Может использоваться как для хранения, так и для отображения значений в структурированном формате. Базы хранят контент в таблицах, чтобы можно было быстро получить доступ к информации из определенных строк. Сайты часто используют их для отображения нескольких строк на странице.
Основные тип баз данных часто содержат несколько таблиц, каждая из которых предназначена для определенной цели. Например, информационная база компании может содержать отдельные таблицы для сотрудников, клиентов и поставщиков. Каждая из них может включать в себя собственный набор полей, основываясь на данных, которые должны в ней храниться. В таблицах информационной базы каждое поле считается столбцом, а каждая запись — строкой. Конкретное значение можно получить, запросив информацию из отдельного столбца и строки.
Локальный кэш распределенной информации
В системе слежения за почтовыми отправлениями никогда не требуется доступ ко всей информации сразу. Это обычное явление во всех областях применения: есть вся накопленная и доступная информация, а есть та ее маленькая часть, которая актуальна на конкретный момент времени.
Ничто не мешает веб-ресурсу создать локальный образ распределенной базы данных. Например, пришел посетитель. Еще до того, как он сформулирует запрос, можно подгрузить варианты ответа.
Если есть опыт работы с посетителями из конкретной страны, то может быть известно, из каких стран ожидаются данные.

В некоторых странах система слежения загружена, в основном, локальными запросами (внутри страны), ничто не мешает оптимизировать этот момент, а внешние отправления отдать на откуп другим веб-ресурсам. В некоторых случаях необходимо не только предоставить посетителю внешнюю информацию, но и сопоставить сведения по ответу на один и тот же запрос от разных систем слежения.
Сказать, что в таком случае получится объектно-реляционная модель информации и доступа к ней в определенном смысле возможно, но для реализации этой модели потребуется представить инструмент моделирования действий компаний, работающих в области слежения, то есть развивающих свой функционал.
В чём преимущества
Базы данных и их системы управления заточены на работу с большим объёмом данных и от лица большого числа пользователей. Сейчас вы поймёте.
Скорость — ещё одно преимущество базы данных. База данных устроена так, что она легко и быстро находит, записывает, переписывает и снова находит данные. Всё потому, что СУБД всегда знает, что где лежит и по какому критерию искать. Там не будет случайных данных в случайном месте.
Скорость важна ещё и потому, что СУБД обычно обслуживает сразу много потоков: одновременно ей могут пользоваться десятки и сотни тысяч человек, поэтому ей некогда копаться. В хорошо сделанных БД всё молниеносно.
Сложность. Базы данных нужны в числе прочего для хранения сложно структурированных данных. Мы привыкли думать, что база данных — это такая таблица, где есть строки и столбцы. Но база данных при правильной организации может намного больше:
- Связывать одну единицу данных с множеством других. Например, если один человек совершил много заказов со множеством товаров внутри каждого, база данных способна хранить и обрабатывать такие связи.
- База может хранить дерево данных — вроде того, о котором мы писали недавно. Попробуй в реальной жизни похранить дерево!
- В базах могут жить ссылки на другие фрагменты и отделы базы.
Базу можно представить как таблицу, но лишь в самом упрощённом виде. Для более сложных задач базу можно представить как очень сложное дерево, или огромный склад упорядоченных коробок, или даже как огромный завод по фасовке данных.
Настоящее и будущее
Если упрощённо, то реляционный подход описывает данные в формате таблиц, то есть вся информация неразрывно связана отношениями и структурой (вспомните Excel со столбцами и строками, где каждый новый объект записывается по тому же шаблону). Это неизбежно приводит к ограничениям по производительности и масштабированию, но с точки зрения создания и управления – это просто и удобно.
NoSQL подход позволяет избежать этих проблем за счёт отсутствия строгих информационных связей. Но тут возникает другая проблема – организация доступа. Решается она 4 основными способами: с помощью документной ориентации, расширяемых записей (разреженных матриц), ключей доступа и теории графов. Естественно, что подход NoSQL требует от разработчика больше знаний и умений, но результаты куда эффективнее. Именно поэтому считается, что SQL уже сейчас уходит в историю, а NoSQL – будущее всех БД.
Впрочем, данное предсказание упирается в тот факт, что использование реляционного подхода для небольших баз куда эффективнее. Поэтому вместо бессмысленного спора поговорим о более практических вещах, а именно непосредственно о наиболее популярных БД.
Разные базы — разные правила
Внутри каждой базы данных и её управляющей системы свои строгие правила:
- какие данные могут храниться: текст, цифры, фото, видео или всё вместе;
- какие свойства есть у этих данных: дата записи, кто записал, кто может прочитать;
- что делать, если с базой хотят работать одновременно несколько человек: разрешать только одному или пусть все вместе работают.
Рабочая ситуация: допустим, вы работаете в банке и открыли карточку клиента, чтобы поменять ему кредитный лимит. В этот же момент другой сотрудник из соседнего офиса тоже хочет поменять лимит этому же клиенту, но уже на другую сумму. Как база отреагирует на такое? Должна ли она разрешать второму сотруднику открывать карточку или её нужно заблокировать, пока первый не закончит? А если она разрешит открыть карточку, то что будет, если двое сотрудников напишут там разный лимит — какой из них сохранять в итоге? СУБД задаёт эти правила и следит за их выполнением.
Виды баз данных и их структура, примеры
Выделяют несколько видов баз данных. Основными из них являются:
- Фактографическая, с краткой информацией об объектах какой-то системы, формат которой строго фиксирован.
- Документальная, включает документы разного вида, в том числе текстовые, графические, звуковые, мультимедийные.
- Распределенная, является базой данных с разными частями, которые хранятся на различных компьютерах, объединенных в сеть.
- Централизованная, представляет собой базу данных, местом хранения которой является один компьютер.
- Реляционная, имеет табличную организацию данных.
- Неструктурированная (NoSQL), является базой данных, в которой делается попытка решить проблемы масштабируемости и доступности с помощью атомарности и согласованности данных без четкой структуры.
Базы данных разных систем обладают неодинаковой структурой. Для ПЭВМ характерно использование реляционных баз данных с файлами в виде таблиц, в которых столбцы являются полями, а строки – записями. В базе данных находятся данные определенного множества объектов. Для каждой записи характерна информация по одному объекту. Такую базу определяют:
- имя файла;
- список полей;
- ширина полей.
В качестве примера можно привести школьную базу с данными «Ученик», «Класс», «Адрес». Также базой данных является расписание движения поездов или автобусов. В этом случае каждой строке соответствует запись с данными конкретного объекта. Возможные поля: номер рейса, маршрут, время отправления и прибытия. Классической базой данных является телефонный справочник.
Определение
Запрос к базе данных – предписание с указанием на данные, которые необходимы пользователю.
Примечание
В случае некоторых запросов требуется составление сложной программы. К примеру, для выполнения запроса к базе в виде автобусного расписания необходимо вычислить разницу в среднем интервале отправления транспорта из одного города во второй и из второго пункта в третий.
Существует три звена для создания приложения, с помощью которого можно просматривать и редактировать базы данных:
- набор данных;
- источник информации;
- визуальные компоненты управления.
В случае Access роль таких звеньев выполняют:
- Table.
- DataSource.
- DBGrid.
Приложения базы данных является нитью, которая связывает базу и пользователя:
БД => набор данных –=> источник данных => визуальные компоненты => пользователь
Набор данных:
- Table, в виде таблицы, навигационного доступа;
- Query, включая запрос, реляционный доступ.
Визуальными компонентами являются:
- Сетки DBGrid, DBCtrlGrid.
- Навигатор DBNavigator.
- Разные аналоги Lable, Edit.
- Компоненты подстановки.
Access характеризуется наличием следующих типов полей:
- текстовый, в виде текстовой строки с максимальной длиной до 255, заданной параметром «размер»;
- поле МЕМО, является текстом длиной до 65535 символов;
- числовой, в параметре «Размер поля» можно задать поле: байт, целое, действительное и другие;
- дата/время, необходимо для записи данных о времени;
- денежный, является специальным форматом для решения финансовых задач;
- счетчик, в виде автоинкрементного поля, который предназначен для ключевого поля, увеличивается на единицу после добавления новой записи и сохраняется в данное поле новой записи, что гарантирует разные значения для неодинаковых записей;
- логический, в виде «да или нет», «правда или ложь», «включен или выключен»;
- объект OLE, предназначен для хранения документов, картинок, звуков и другой информации, представляет собой частный случай BLOB, то есть полей (Binary Large Object), которые можно встретить в разных базах данных;
- гиперссылка, необходима для хранения ссылок на ресурсы в Интернете, характерна не для всех форматов баз данных, например, отсутствует в dBase и Paradox;
- подстановка.
Благодаря связи с обеспечением целостности таблиц осуществляется контроль удаления и модификации данных. С помощью монопольного доступа к базам данных в них производят фундаментальные изменения.
Иерархическая модель

Различия между наиболее распространенными моделями БД являются результатом технической эволюции электронной передачи данных, которая не только преследовала цели эффективности и управляемости, но также расширяла возможности наиболее известных производителей. Это самая старая модель, которая сегодня значительно превосходит реляционную, хотя в последнее время наблюдается рост ее популярности.
XML использует эту систему для хранения информации. Некоторые страховые компании и банки обращаются к иерархическим базам данных в самых старых приложениях. Наиболее известная — это база IBM IMS/DB.
В иерархической модели классификации данных БД существуют строгие и однозначные зависимости. Каждая запись имеет только один прецедент (Parent-Child Relationships, PCR), за исключением корня (root), составляющего древовидную схему. Хотя каждый дочерний узел может иметь только один родительский, «родители» могут иметь столько дочерних узлов, сколько они хотят.
Учитывая строгое иерархическое упорядочение, уровни, не имеющие прямой связи, не взаимодействуют друг с другом, поэтому соединить два разных дерева непросто. При этом иерархические структуры баз данных чрезвычайно гибки и понятны. Записи с «детьми» называются записями, а те, которые без, — листьями, и обычно являются документами в записи для листьев в классификации БД. Запросы к иерархической базе данных достигают листьев, начиная с корня и проходя через различные записи.
Популярные системы управления реляционными базами данных
Синтаксис SQL может немного отличаться в зависимости от того, какую СУБД вы используете.
MySQL
Основными преимуществами MySQL являются то, что он прост в использовании, недорого, надежен (существует с 1995 года) и имеет большое сообщество разработчиков, которые могут помочь ответить на вопросы.
Разработка с открытым исходным кодом задерживается с тех пор, как Oracle взяла под свой контроль MySQL, и он не включает некоторые дополнительные функции, к которым могут быть привыкли разработчики.
PostgreSQL
PostgreSQL имеет многие из преимуществ MySQL.
Он прост в использовании, недорог, надежен и имеет большое сообщество разработчиков. Он также предоставляет некоторые дополнительные функции, такие как поддержка внешнего ключа, не требуя сложной настройки.
БД Oracle
Большинство ведущих банков мира используют приложения Oracle, потому что Oracle предлагает мощное сочетание технологий и комплексных, предварительно интегрированных бизнес-приложений, включая основные функции, созданные специально для банков.
SQL Server
Microsoft владеет SQL Server. Как и в Oracle DB, исходный код кода очень близок.
Крупные корпоративные приложения в основном используют SQL Server.
Microsoft предлагает бесплатную версию начального уровня под названием Express, но она может стать очень дорогой при масштабировании приложения.
SQLite
Одним из наиболее значительных преимуществ этого является то, что все данные могут храниться локально без необходимости подключения вашей базы данных к серверу.
SQLite – популярный выбор для баз данных в мобильных телефонах, КПК, MP3-плеерах, телевизионных приставках и других электронных устройствах. Курсы SQL на Codecademy используют SQLite.
Понятие базы данных
Построение статической модели важно. Это этап формирования представлений о том, что актуально в области применения и понимания, что может в ней развиваться дальше
На современном уровне знаний динамика — это дискретная последовательность статических моделей, а точнее — серии воплощений представлений в форме доступной для понимания не только автором, то есть вне его сознания, в модели, в графике, в связях, в программных описаниях.
По общему мнению, «база данных — это информационная модель, позволяющая упорядоченно хранить данные о группе объектов, обладающих одинаковым набором свойств. Информация в базах хранится в упорядоченном виде».

Энциклопедическое «знание» обычно гласит: «База данных — представленная в объективной форме совокупность самостоятельных материалов (статей, расчетов, нормативных актов, судебных решений и иных подобных материалов), систематизированных таким образом, чтобы эти материалы могли быть найдены и обработаны с помощью электронной вычислительной машины».
Некоторые авторы по старинке (до того, как компьютеры стали персональными, переносными и карманными) выделяют особую когорту: настольные базы данных к которым относят все, что меньше одного терабайта, а также не имеет отношения к Oracle.
Слово, которое вовсе не имеет значения
Главная проблема в области информации — стремительно растущая динамика, к которой пользователь не только привык, он сам ее формирует и заинтересован в адекватности используемых им инструментов.
Базы данных — не самый мобильный и динамичный инструмент. Хочет того разработчик или нет, но он всегда в плену технологий. Он не может создать базу данных, которая не поддерживается существующими СУБД, а создавать собственный вариант в 99 % случаев нет возможности и реальной необходимости.

Между тем, есть и отчасти реализуется иной подход к созданию современных информационных систем. Абстракция, которую принесло с собой объектно-ориентированное программирование и облачные технологии, позволяет определить слово, которое поначалу вовсе не имеет значения, но приобретает его с течением времени.
Каждый занимается своим делом. Базы данных работают в штатном режиме, появляются новые, модернизируются старые. Веб-ресурсы берут на себя функции систем управления базами данных на пользовательском уровне. Поисковые системы ассоциируют ключевые слова и запросы с пространством доступной информации, собранной по их уникальным критериям.
В этих двух примерах и веб-ресурсы — окошки в базы данных и поисковики, в собранную по критериям информацию, представляют собой реально работающую идею динамического использования информации.
Реляционная база данных
Под данным типом баз данных понимается их представление в рамках двумерной таблицы. Она имеет несколько столбцов, в которых устанавливаются такие параметры, как, например, тип вводимых данных (текст, число, дата и др.).
Таблица здесь является способом хранения введённых в неё данных и способна реагировать на любые обращения со стороны СУБД. Главная проблема в работе с реляционными базами данных состоит в их правильном проектировании.
Во время проектирования базы данных следует учесть следующие два фактора:
- база данных должна быть компактной и не содержать избыточных компонентов;
- обработка базы данных должны происходить просто.
Проблема в том, что эти факторы друг другу противоречат. А ведь проектирование — важнейший момент при составлении базы данных и дальнейшей работе с ней. Заниматься им рекомендуется администратору сервера, обладающему определённым опытом.
В крупных проектах задействовано множество таблиц, которых может быть более сотни. При этом обойтись без них невозможно, если человек имеет дело с важным и сложным проектом.
Перед составлением таблицы следует составить диаграмму или схему, в которой содержится информация о видах хранимой информации, а также о типе данных, который лучше всего подойдёт для таких целей.
Что такое нормализация
Чтобы уменьшить размер реляционной базы (не хранить избыточные данные) и избежать противоречивости (аномалий) при работе с ними, отношения в базе нормализуют. Проще говоря — разбивают их на взаимосвязанные таблицы. Это называется декомпозицией.
Избыточность данных — это когда одни и те же данные хранятся в базе сразу в нескольких местах.
Проверим наш пример на избыточность
Каждая строка таблицы Messages содержит имя клиента и никнейм оператора, а также их телефоны. Причём в 1-й и 3-й строках мы видим звонки от одного и того же клиента, а в 1-й и во 2-й — ответы одного и того же менеджера. То есть в 1-й и 3-й строках дублируются имя и телефон клиента — Васи, а в 1-й и 2-й — никнейм менеджера «Оператор1».
Чтобы избавиться от дублирования информации, выделим сущности Клиент и Оператор. И вынесем специфичные для каждой атрибуты в отдельные таблицы.
В первой (Clients) будут храниться имена и телефоны клиентов, а во второй (Operators) — операторов. Кроме того, каждой записи в этих таблицах мы присвоим атрибут id — так называемый первичный ключ (его значение уникально, то есть не может повторяться в пределах таблицы). С его помощью мы установим связь с записями таблицы Messages.
Для этого к каждой записи в Messages (напомним, она всё ещё представляет сущность «звонок») добавим два новых атрибута (внешних ключа): id_client и id_oper. Они будут ссылаться на первичные ключи из таблиц Clients и Operators соответственно. Столбцы с именами и телефонами из таблицы Messages уберём.
И вот что получим:
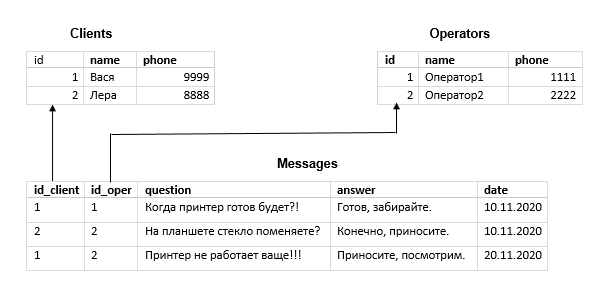
В такой базе, чтобы поменять телефон клиента сразу для всех записей, достаточно изменить всего одно поле в таблице Clients.
Всего существует шесть форм нормализации реляционных баз данных — в порядке уменьшения избыточности отношений. Все они описаны формальными правилами. Наше отношение мы привели ко второй нормальной форме.
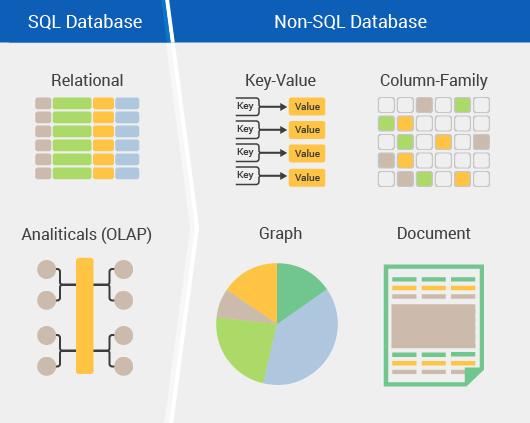
Типы баз данных
Есть много разных типов баз данных. Лучшая база данных для конкретной организации зависит от того, как организация намеревается использовать данные.
- Реляционные базы данных. Реляционные базы данных стали доминирующими в 1980-х годах. Элементы в реляционной базе данных организованы как набор таблиц со столбцами и строками. Технология реляционных баз данных обеспечивает наиболее эффективный и гибкий способ доступа к структурированной информации.
- Объектно-ориентированные базы данных. Информация в объектно-ориентированной базе данных представлена в виде объектов, как в объектно-ориентированном программировании.
- Распределенные базы данных. Распределенная база данных состоит из двух или более файлов, расположенных на разных сайтах. База данных может храниться на нескольких компьютерах, находиться в одном физическом месте или разбросана по разным сетям.
- Хранилища данных. Централизованное хранилище данных, хранилище данных — это тип базы данных, специально разработанный для быстрого запроса и анализа.
- Базы данных NoSQL. NoSQL, или нереляционная база данных, позволяет хранить и обрабатывать неструктурированные и полуструктурированные данные (в отличие от реляционной базы данных, которая определяет, как должны быть составлены все данные, вставленные в базу данных). Базы данных NoSQL становились популярными по мере того, как веб-приложения становились все более распространенными и сложными.
- Графовые базы данных. База данных графов хранит данные в терминах сущностей и отношений между сущностями.
- Базы данных OLTP. База данных OLTP — это быстрая аналитическая база данных, предназначенная для большого количества транзакций, выполняемых несколькими пользователями.
Это лишь некоторые из нескольких десятков типов баз данных, используемых сегодня. Другие, менее распространенные базы данных предназначены для очень конкретных научных, финансовых или других функций. Помимо различных типов баз данных, изменения в подходах к разработке технологий и значительные достижения, такие как облачные технологии и автоматизация, продвигают базы данных в совершенно новых направлениях. Некоторые из последних баз данных включают:
- Базы данных с открытым исходным кодом (OpenSource). Система баз данных с открытым исходным кодом — это система с открытым исходным кодом; такие базы данных могут быть базами данных SQL или NoSQL.
- Облачные базы данных (Cloud Database). Облачная база данных — это набор структурированных или неструктурированных данных, который хранится на частной, общедоступной или гибридной платформе облачных вычислений. Существует два типа моделей облачных баз данных: традиционные и база данных как услуга (DBaaS). В случае DBaaS административные задачи и обслуживание выполняются поставщиком услуг.
- Многомодельная база данных. Мультимодельные базы данных объединяют различные типы моделей баз данных в единую интегрированную серверную часть. Это означает, что они могут поддерживать различные типы данных.
- База данных Документов / JSON. Базы данных документов, разработанные для хранения, извлечения и управления документально-ориентированной информацией, представляют собой современный способ хранения данных в формате JSON, а не в строках и столбцах.
- Автономные базы данных. Новейший и самый революционный тип базы данных, автономные базы данных (также известные как автономные базы данных) являются облачными и используют машинное обучение для автоматизации настройки базы данных, обеспечения безопасности, резервного копирования, обновления и других рутинных задач управления, традиционно выполняемых администраторами баз данных.
Для чего нужны
Вот основные задачи БД на примере гардеробной:
- Сохранить наши данные по запросу — чтобы вы могли открыть дверь, повесить куртку, закрыть дверь и больше не думать ни о куртке, ни о гардеробной.
- Изменить наши данные по запросу — чтобы можно было легко извлечь из гардеробной все дырявые носки и положить на их место целые.
- Найти эти данные по запросу — чтобы быстро найти приличный пиджак или парный носок.
- Не дать прочитать эти данные тем, кому не следует, а кому надо — дать. Например, младший брат может смотреть на ваши кроссовки, но не может их брать. А девушка (или парень) может положить свои вещи, но только на определённую полку.
- Поддерживать порядок и не дать захламиться — если вам было лень и вы просто кинули толстовку куда попало, чтобы гардеробная либо сама нашла, куда эту толстовку правильно положить, либо сказала: «Э БРАТ ЗАЧЕМ ЗАХЛАМЛЯЕШЬ ПОЛОЖИ НОРМАЛЬНО ДАВАЙ»
- Масштабироваться — чтобы вы могли просто вешать в гардеробную вещи и не думать об объёме полок.
- Не потерять данные — если квартира будет гореть, приличная гардеробная не должна даже нагреться. Или, если она всё-таки горит, чтобы где-то в защищённом подземном гараже была точная копия этой гардеробной со всеми актуальными вещами.
Мир объектов, систем и решений
Реальные объекты и действующие системы объединяются в области применения человеком, принимающим решения. Сам факт посещения ресурса, обращения к объекту, использование системы имеет цель и полученный результат.
Нет необходимости фантазировать об искусственном интеллекте, когда вполне достаточно накапливать практику принятия решений человеком и использовать ее. Совершенно не обязательно привязывать решения, принятые сотрудниками одной компании к работе этой структуры.

Сфера антивирусной защиты уже давно собирает вирусные угрозы со всех возможных направлений и обобщает их для использования в каждом конкретном случае. Чем выше объем захвата растущих угроз, тем эффективнее борьба с ними на конкретных рабочих местах.
Когда информационная система способна накапливать опыт принятия решений, это хорошее начало и свидетельство компетентности разработчиков, гарантия стабильности развития потребителей и общего успеха.
Типы баз данных, их преимущества и недостатки на News4Auto.ru.
Наша жизнь состоит из будничных мелочей, которые так или иначе влияют на наше самочувствие, настроение и продуктивность. Не выспался — болит голова; выпил кофе, чтобы поправить ситуацию и взбодриться — стал раздражительным. Предусмотреть всё очень хочется, но никак не получается. Да ещё и вокруг все, как заведённые, дают советы: глютен в хлебе — не подходи, убьёт; шоколадка в кармане — прямой путь к выпадению зубов. Мы собираем самые популярные вопросов о здоровье, питании, заболеваниях и даем на них ответы, которые позволят чуть лучше понимать, что полезно для здоровья.
Системы распределенной обработки информации
Есть только два варианта, когда типы базы данных могут существенно отличаться. Разработчик сам строит модель распределенной обработки, моделирует процессы, формулирует алгоритмы диалога и выполняет все смежные действия.
Второй вариант: множество разработчиков выполняет свою работу, накапливает и предоставляет информацию, что обуславливает появление возможности использования распределенной обработки информации. Совсем не обязательно для этого создавать собственный ресурс. Любая поисковая система — это пример управления через ключевые слова доступом к распределенным данным.
Если формулировать правильные запросы, можно получать адекватные ответы. Не имеет значение мнение всех тех ресурсов Сети, разработчиков и владельцев баз данных, которые предоставляют информацию
Важно, что на ключевое слово работает поисковый движок, в компетенции которого находится уже собранная информация или собираемая вновь
Какие реляционные БД популярны в веб-разработке
MySQL
Это открытая СУБД, купленная Oracle в придачу к Sun Microsystems. С ней работают более половины (55,6%) всех разработчиков (по опроса, который в 2020 году провёл сайт StackOverflow.com среди 65 тысяч респондентов).
Главные её преимущества — бесплатность и высокая скорость работы с данными. MySQL создавалась для обработки огромных массивов информации в промышленных масштабах, но благодаря доступности и быстродействию оккупировала Всемирную паутину, заслужив звание «СУБД всея интернета». И сегодня MySQL всё ещё самая удобная СУБД для работы с интернет-страницами и веб-приложениями.
MySQL пользуется мощной поддержкой у создателей языков программирования: практически во всех популярных языках есть интерфейс для работы с ней.
SQLite
Эта СУБД использует большую часть стандартного языка SQL.
Главное преимущество SQlight — встраиваемость. Это объясняется тем, что SQlight не приложение типа «клиент-сервер» (в отличие от других реляционных СУБД), а библиотека, которую подключают непосредственно к программе.
И она тоже весьма популярна: достаточно сказать, что SQLite есть в каждом смартфоне. Например, в смартфонах на Android там хранятся контакты и медиа, а в iOS её используют многие приложения.
PostgreSQL
Её можно назвать самой продвинутой. Это не просто реляционная, а объектно-реляционная свободная СУБД.
PostgreSQL поддерживает не только типы данных, которые есть в других реляционных СУБД. Помимо числовых, текстовых, булевых и других стандартных типов, в ней можно хранить и обрабатывать геометрические и денежные данные, сетевые адреса, JSON, XML, массивы, а также создавать собственные типы данных.