Sql и nosql: инь и ян в мире баз данных
Содержание:
«Введение в базы данных» от Stepik

- Длительность: 12 академических часов
- Сертификат: да
- Формат обучения: видео и презентации
Описание курса
Материал подходит для изучения студентами 1-3 курсов, обучающихся по программам, связанным с компьютерными науками. Если вы хотите пройти данный курс, то вам понадобится знание командной строки, а также формулы Бэкуса-Наура. Кроме того, преподаватели рекомендуют знать английский язык на среднем уровне.
Курс предназначен для получения базовых знаний о работе баз данных. Во время изучения материала будут рассмотрены ключевые этапы создания реляционных БД, а также случаи неправильного использования информации. Также программа включает в себя ознакомление с SQL-базами.
Плюсы:
- Профессиональный преподавательский состав;
- Обширная программа курса;
- Предоставление сертификата.
Минусы:
SQL Server Data Tools
SQL Server Data Tools (SSDT) – это отдельный компонент (рабочая нагрузка) Visual Studio, который предназначен для разработки реляционных баз данных SQL Server.

SSDT создан для проектной разработки баз данных с применением всех возможностей и преимуществ Visual Studio, а также с использованием привычного для разработчиков приложений интерфейса и функционала.
Таким образом, SQL Server Data Tools предназначен для разработчиков, создающих приложения в среде Visual Studio.
Основные особенности
Интегрирован в Visual Studio
Знакомый интерфейс и функционал Visual Studio
Ориентация на разработку баз данных
Охват всех этапов разработки базы данных
Можно работать как с проектом базы данных, так и с подключенным экземпляром базы данных
Конструктор таблиц с графическим интерфейсом
Навигация по коду
Технология IntelliSense
Сборка и отладка
Рефакторинг баз данных
Декларативное внесение изменений в редакторе Transact-SQL
Недостатки
Инструмент реализован только под Windows
Инструмент нельзя использовать без Visual Studio
Не подходит для простого написания, редактирования и выполнения SQL запросов
Не подходит для администрирования SQL Server
Мне нравится3Не нравится
PosgreSQL
Масштабируемая объектно-реляционная база данных, работающая на Linux, Windows, OSX и некоторых других системах. В PostgreSQL 10 есть такие функции, как логическая репликация, декларативное разбиение таблиц, улучшенные параллельные запросы, более безопасная аутентификация по паролю на основе SCRAM-SHA-256.
- Разработчик: PostgreSQL Global Development Group
- Написана на C
- Используется в компаниях: Apple, Cisco, Fujitsu, Skype, and IMDb
- Последняя версия: 11.2
- Блог: PostgreSQL
- Скачать: PostgreSQL
Особенности
- Поддержка табличных пространств, а также хранимых процедур, объединений, представлений и триггеров.
- Восстановление на момент времени (PITR).
- Асинхронная репликация.
Как хранится информация в БД
В основе всей структуры хранения лежат три понятия:
- База данных;
- Таблица;
- Запись.
База данных
База данных — это высокоуровневное понятие, которое означает объединение совокупности данных, хранимых для выполнения одной цели.
Если мы делаем современный сайт, то все его данные будут храниться внутри одной базы данных. Для сайта онлайн-дневника наблюдений за погодой тоже понадобится создать отдельную базу данных.
Таблица
По отношению к базе данных таблица является вложенным объеком. То есть одна БД может содержать в себе множество таблиц.
Аналогией из реального мира может быть шкаф (база данных) внутри которого лежит множество коробок (таблиц).
Таблицы нужны для хранения данных одного типа, например, списка городов, пользователей сайта, или библиотечного каталога.
Таблицу можно представить как обычный лист в Excel-таблице, то есть совокупность строк и столбцов.
Наверняка каждый хоть раз имел дело с электронными таблицами (MS Excel).
Заполняя такую таблицу, пользователь определяет столбцы, у каждого из которых есть заголовок. В строках хранится информация.
В БД точно также: создавая новую таблицу, необходимо описать, из каких столбцов она состоит, и дать им имена.
Запись
Запись — это строка электронной таблицы.
Это неделимая сущность, которая хранится в таблице. Когда мы сохраняем данные веб-формы с сайта, то на самом деле добавляем новую запись в какую-то из таблиц базы данных. Запись состоит из полей (столбцов) и их значений. Но значения не могут быть какими угодно.
Определяя столбец, программист должен указать тип данных, который будет храниться в этом столбце: текстовый, числовой, логический, файловый и т.д. Это нужно для того, чтобы в будущем в базу не были записаны данные неверного типа.
Соберем всё вместе, чтобы понять, как будет выглядеть ведение дневника погоды при участии базы данных.
- Создадим для сайта новую БД и дадим ей название «weather_diary».
- Создадим в БД новую таблицу с именем «weather_log» и определим там следующие столбцы:
- Город (тип: текст);
- День (тип: дата);
- Температура (тип: число);
- Облачность (тип: число; от 0 (нет облачности) до 4 (полная облачность));
- Были ли осадки (тип: истина или ложь);
- Комментарий (тип: текст).
- При сохранении формы будем добавлять в таблицу weather_log новую запись, и заполнять в ней все поля информацией из полей формы.
Теперь можно быть уверенными, что наблюдения наших пользователей не пропадут, и к ним всегда можно будет получить доступ.
Реляционная база данных
Английское слово „relation“ можно перевести как связь, отношение.
А определение «реляционные базы данных» означает, что таблицы в этой БД могут вступать в отношения и находиться в связи между собой.
Что это за связи?
Например, одна таблица может ссылаться на другую таблицу. Это часто требуется, чтобы сократить объём и избежать дублирования информации.
В сценарии с дневником погоды пользователь вводит название своего города. Это название сохраняется вместе с погодными данными.
Но можно поступить иначе:
- Создать новую таблицу с именем „cities“.
- Все города в России известны, поэтому их все можно добавить в одну таблицу.
- Переделать форму, изменив поле ввода города с текстового на поле типа «select», чтобы пользователь не вписывал город, а выбирал его из списка.
- При сохранении погодной записи, в поле для города поставить ссылку на соответствующую запись из таблицы городов.
Так мы решим сразу две задачи:
- Сократим объём хранимой информации, так как погодные записи больше не будут содержать название города;
- Избежим дублирования: все пользователи будут выбирать один из заранее определённых городов, что исключит опечатки.
Связи между таблицами в БД бывают разных видов.
В примере выше использовалась связь типа «один-ко-многим», так как одному городу может соответствовать множество погодных записей, но не наоборот!
Бывают связи и других типов: «один-к-одному» и «многие-ко-многим», но они используются значительно реже.
СУБД в СКУД
В таблице ниже приведены данные из открытых источников относительно типа применяемой СУБД в популярных в России системах контроля и управления доступом.
| Производитель | СКУД | СУБД |
| Parsec | ParsecNET 3 | Microsoft SQL Server (в поставке 2012 Express, заявлена поддержка версий 2008 R2 и выше) — центральная БД; SQLite — локальные базы рабочих станций. |
| Elsys | Бастион 2 | Oracle (в поставке 11g Express), заявлена поддержка версий Oracle 12с, Oracle SE2, также может использоваться СУБД PostgreSQL 10 или Postgres Pro |
| Perco | S20 | Firebird 2.0 |
| НВП Болид | Орион ПРО | Microsoft SQL Server (в поставке 2012 Express), заявлена поддержка версий 2008/2012/2014 |
| РусГард | RusGuard | Microsoft SQL Server (в поставке 2014 Express), заявлена поддержка версий 2014/2016 |
| Равелин ЛТД | Gate | Microsoft Access |
| ПромАвтоматика Сервис | Сфинкс | MySQL |
| Кодос | ИКБ Кодос | Firebird |
| TSS | Семь Печатей | Firebird |
| Bosсh | Access PE | Microsoft SQL Server (рекомендуется версия 2014 Express Edition) |
| Honeywell | Pro-Watch | Microsoft SQL Server 2012/2014/2016 |
| Siemens | SiPass | Microsoft SQL Server 2000 |
| ААМ Системз | Apacs 3000 | Firebird 2.5 (входит в комплект поставки), поддерживается также Microsoft SQL Server 2017 |
| Lyrix | Borland Interbase 2007 (в комплекте поставки), поддержка Oracle 10g и Microsoft SQL Server 2005 |
Как видно, большинство производителей СКУД поставляют бесплатную версию промышленной клиент-серверной СУБД Microsoft SQL Server Express Edition и свободную (бесплатную) кроссплатформенную СУБД Firefird (примерно 50 на 50).
Конкретный выбор той или иной СУБД — дело вкуса и предпочтений каждого производителя, благо — выбор есть. При выборе разработчики учитывают также вопросы удобства и простоты администрирования, наличие встроенных бесплатных инструментов для администрирования и разработки.
СУБД для СКУД помимо высокой надёжности и производительности должна быть удобной и недорогой в поддержке. Разработчики СКУД прекрасно понимают, что даже на крупных объектах зачастую нет выделенных специалистов для обслуживания СКУД, обладающих навыками администрирования СУБД, поэтому стараются включать в свои продукты функции, облегчающие и автоматизирующие процессы обслуживания базы данных.
Прежде всего — резервное копирование БД
, основа основ, которая позволяет администратору системы спокойно спать. Все СУБД имеют собственные средства для создания резервных копий, но хорошим тоном считается, когда функция резервного копирования интегрирована в продукт и администратору необходимо лишь включить/настроить её и периодически проверять функционирование.
Вторая частая проблема — восстановление данных после сбоя
. Здесь опять же на выручку приходит свежая резервная копия, но если её нет, или критично восстановление всех возможных данных, то потребуются дополнительные усилия. К счастью, в промышленных СУБД (чего не скажешь о старых файловых СУБД типа Paradox) такие явления происходят нечасто, их может вызвать разве что «умирающий» жёсткий диск или сбой электропитания. В этом случае потребуются услуги специалиста-администратора СУБД, который сможет с помощью встроенных в любую серьёзную СУБД инструментов восстановить максимум из возможного. Также следует учесть, что некоторые производители СКУД в рамках технической поддержки оказывают услуги по восстановлению баз.
Объектно-ориентированные субд
Появление объектно-ориентированных СУБД вызвано потребностями программистов на ОО-языках, которым были необходимы средства для хранения объектов, не помещавшихся в оперативной памяти компьютера. Также важна была задача сохранения состояния объектов между повторными запусками прикладной программы. Поэтому, большинство ООСУБД представляют собой библиотеку, процедуры управления данными которой включаются в прикладную программу. Примеры реализации ООСУБД как выделеного сервера базы данных крайне редки.
Сразу же необходимо заметить, что общепринятого определения «объектно-ориентированной модели данных» не существует. Сейчас можно говорить лишь о неком «объектном» подходе к логическому представлению данных и о различных объектно-ориентированных способах его реализации.
Структура
Структура объектной модели описываются с помощью трех ключевых понятий:
инкапсуляция — каждый объект обладает некоторым внутренним состоянием (хранит внутри себя запись данных), а также набором методов — процедур, с помощью которых (и только таким образом) можно получить доступ к данным, определяющим внутреннее состояние объекта, или изменить их. Таким образом, объекты можно рассматривать как самостоятельные сущности, отделенные от внешнего мира;
наследование — подразумевает возможность создавать из классов объектов новые классы объекты, которые наследуют структуру и методы своих предков, добавляя к ним черты, отражающие их собственную индивидуальность. Наследование может быть простым (один предок) и множественным (несколько предков);
полиморфизм — различные объекты могут по разному реагировать на одинаковые внешние события в зависимости от того, как реализованы их методы.
Целостность данных
Для поддержания целостности объектно-ориентированный подход предлагает использовать следующие средства:
автоматическое поддержание отношений наследования возможность объявить некоторые поля данных и методы объекта как «скрытые», не видимые для других объектов; такие поля и методы используются только методами самого объекта создание процедур контроля целостности внутри объекта
Средства манипулирования данными
К сожалению, в объектно-ориентированном программировании отсутствуют общие средства манипулирования данными, такие как реляционная алгебра или реляционное счисление. Работа с данными ведется с помощью одного из объектно-ориентированных языков программирования общего назначения, обычно это SmallTalk, C++ или Java.
В объектно-ориентированных базах данных, в отличие от реляционных, хранятся не записи, а объекты. ОО-подход представляет более совершенные средства для отображения реального мира, чем реляционная модель, естественное представление данных. В реляционной модели все отношения принадлежат одному уровню, именно это осложняет преобразование иерархических связей модели «сущность-связь» в реляционную модель. ОО-модель можно рассматривать послойно, на разных уровнях абстракции. Имеется возможность определения новых типов данных и операций с ними.
В то же время, ОО-модели присущ и ряд недостатков:
осутствуют мощные непроцедурные средства извлечения объектов из базы. Все запросы приходится писать на процедурных языках, проблема их оптимизации возлагается на программиста;
вместо чисто декларативных ограничений целостности (типа явного объявления первичных и внешних ключей реляционных таблиц с помощью ключевых слов PRIMARY KEY и REFERENCES) или полудекларативных триггеров для обеспечения внутренней целостности приходится писать процедурный код.
Очевидно, что оба эти недостатка связаны с отсутствием развитых средств манипулирования данными. Эта задача решается двумя способами — расширение ОО-языков в сторону управления данными (стандарт ODMG), либо добавление объектных свойств в реляционные СУБД (SQL-3, а также так называемые объектно-реляционных СУБД).
Запросы
Это основной рабочий инструмент для каждой системы управления базами данных. С помощью запросов выполняются многочисленные функции. Наиболее распространенной является возможность извлечения конкретных сведений из таблиц. Запросы дают возможность предоставить нужные данные в отдельной структурированной форме, чтобы не просматривать все, включая ненужные сведения. Это своеобразный фильтр для каждой базы данных.
Запросы работают по принципу выборки и изменения. В последних предусматривается возможность редактирования предоставленной информации. При внесении изменений нужно понимать, что они будут сохранены в основной базе данных. Запрос на выборку дает возможность обычного просмотра или копирования информации.
Azure Data Studio
Azure Data Studio – это бесплатный, кроссплатформенный инструмент с открытым исходным кодом для работы с базами данных Microsoft SQL Server.
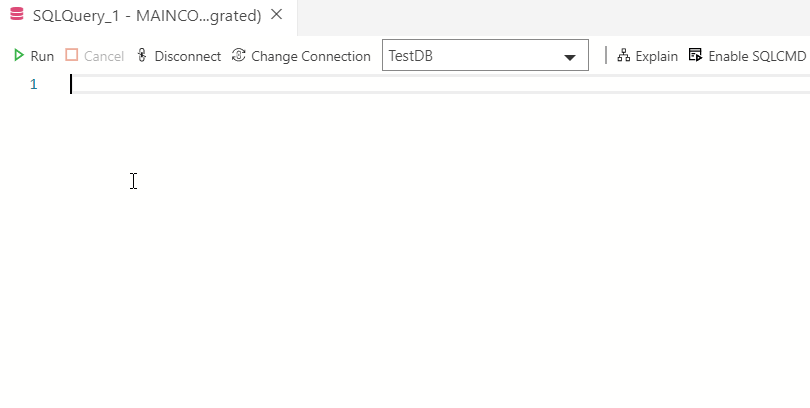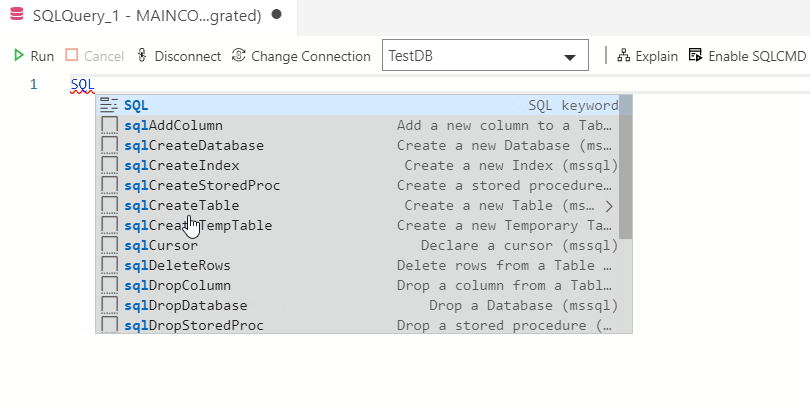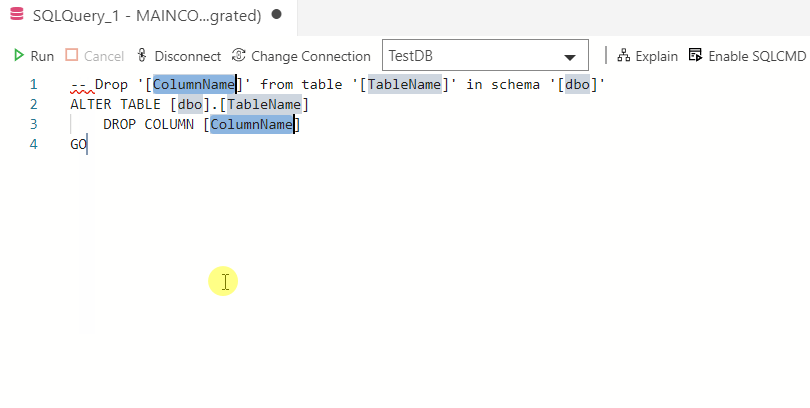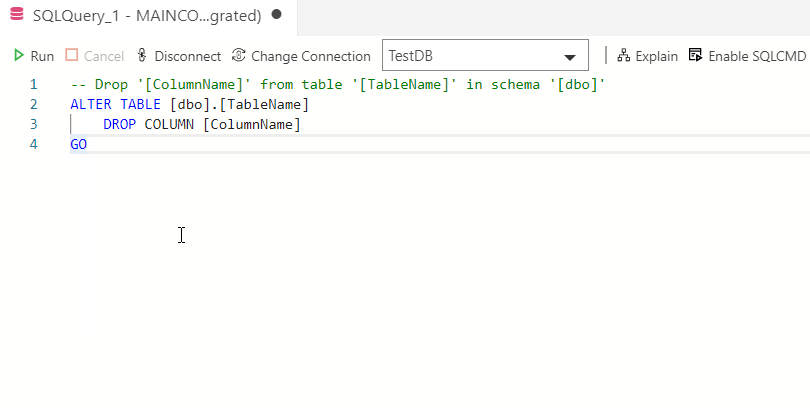

Azure Data Studio основана на Visual Studio Code и ориентирована на SQL разработчиков, так как основное назначение Azure Data Studio – это написание, редактирование и выполнение SQL запросов, иными словами, это редактор SQL кода.
Azure Data Studio позволяет работать с базами данных Microsoft SQL Server, SQL Azure, а также с другими СУБД, например, с PostgreSQL
Основные особенности
Инструмент бесплатный
Кроссплатформенность (поддержка Windows, Linux, macOS)
Ориентация на SQL разработчиков
Продвинутый SQL редактор (технология IntelliSense, фрагменты SQL кода)
Расширяемость (встроенная поддержка расширений)
Работа с другими СУБД
Встроенная возможность выгрузки данных в формат Excel, XML, JSON, CSV
Группировка подключений к серверам
Визуализация данных с помощью диаграмм и графиков
Поддержка нескольких цветовых тем
Встроенный терминал (Bash, PowerShell, sqlcmd)
Записные книжки
Недостатки
Отсутствует конструктор таблиц
Нет функционала для работы со свойствами объектов
Отсутствует возможность управления безопасностью
Отсутствует возможность импорта и экспорта DACPAC
Отсутствует функционал для большинства задач администрирования
Мне нравится4Не нравится
Создаем базу данных
Управление базами данных как объектами
Будем считать, что наша небольшая экскурсия по запросам и командам SQL со стороны «торгового зала» завершена. Заглянем теперь в его «служебные помещения» и познакомимся с тем, как создается сама база данных. Эта часть языка SQL не столь стандартизирована и сильно отличается в различных реализациях. Поэтому в дальнейших примерах я буду придерживаться синтаксиса, принятого в самой популярной на веб-серверах системе — MySQL.
MySQL — продукт шведской компании MySQL AB. Ее основатели — Дэвид Аксмарк, Аллан Ларсон и Майкл Видениус (последний больше известен по прозвищу — Монти). По одной из версий, первая часть названия продукта (My) — не что иное, как англизированная запись имени дочери М. Видениуса. Однако точно за происхождение названия сегодня не могут поручиться даже отцы-создатели. Существует версия, по которой «my» — это префикс, с которого начинались названия рабочих каталогов на их компьютерах.
Из всех команд чаще всего нам будут нужны три: CREATE (создать), ALTER (изменить) и DROP (уничтожить).
Чтобы создать новую базу данных с названием, ну скажем, OUR_SHOP, следует выполнить команду:
Еще лучше сразу при ее создании установить нужную кодировку (ведь по умолчанию в MySQL используется latin1). В итоге команда будет выглядеть так.
Если вы забыли сделать это сразу, не беда. Для того и существуют команды по изменению:
Когда, наигравшись вдоволь с пробной базой данных, вы захотите ее уничтожить, воспользуйтесь командой:
Управление таблицами
Чтобы создать таблицу GOODS, на которой мы отрабатывали манипуляции с данными, потребуется составить команду примерно такого вида:
Разберем эту команду подробнее. Тип INT устанавливается для столбцов с целочисленными данными, тип VARCHAR(100) обеспечивает хранение строк с длиной не более 100 символов, DECIMAL(10,2) соответствует действительным числам с не более чем десятью знаками и точностью в два знака после запятой.
Столбец ID объявлен первичным ключом (PRIMARY KEY).
Ключевое слово AUTO_INCREMENT означает, что при добавлении новых строк с неуказанным значением ID оно будет автоматически заполняться следующим значением. Это удобно, поскольку обычно нет нужды вручную указывать значения первичных ключей, а за тем, чтобы они были уникальными, пусть лучше следит база данных.
NOT NULL означает запрет на пустые значения в столбце, иными словами, гарантирует обязательность заполнения.
Команда DEFAULT задает значение по умолчанию — то, которое будет записываться в базу при добавлении новой строки, если не указано иное. В нашем случае она обеспечивает автоматическое объявление товара штучным (код = 1) в случае, если при добавлении новых строк не будет указан другой код.
Признак UNIQUE обеспечивает уникальность значений в колонке (в нашем случае — уникальность названий товаров).
Если в будущем вы захотите перенастроить объявленные командой CREATE столбцы таблицы, сделать это можно командой ALTER. Например, таблицу GOODS можно нарастить строчной колонкой REMARK (подкоманда ADD):
Поработав с ней немного и убедившись, что 50 символов для примечания явно недостаточно, увеличиваем максимальный размер строки до 250 (блок CHANGE):
Так как имя столбца мы не изменяли (новое совпадает со старым), то его просто повторяем в этой команде (как бы меняем само на себя).
И наконец, убедившись через какое-то время, что без примечания в товарном справочнике вполне можно обойтись, мы удаляем ставшую ненужной колонку (блок DROP):
Удалить таблицу целиком можно командой DROP:
Стоит ли говорить о том, что пользоваться командами с этим ключевым словом следует с особой осторожностью?
PhpMyAdmin
Access, конечно, программа хорошая, но если нужна база данных для сайта, она не справится. Тогда на помощь приходит PhpMyAdmin. Это очень полезная программа для создания баз данных. Установка на компьютер занимает некоторое время, да и при инсталляции легко что-то сделать не так, и не будет работать. Поэтому при установке этой программы для создания баз данных нужно четко следовать инструкции. Но плюсом еще PhpMyAdmin является то, что к ней можно получить доступ и через интернет в виде сайта! Например, у вас есть сайт, который работает на WordPress. У него будет база данных. И если у вас сайт на каком-нибудь хорошем хостинге, то, вероятнее всего, работа с базами данных будет осуществляться через PhpMyAdmin, и к нему можно будет получить доступ через панель управления хостинга.
«Отсечение строк и сортировка в SQL» от LearnDB
- Длительность: 2 часа
- Сертификат: нет
- Формат обучения: текстовый курс
Описание курса
Более углубленная программа, которая охватывает средства SQL, предназначенные для осуществления выборки данных и сортировки строк. Ее прохождение займет всего 2 часа, однако после этого вы сможете выполнять простейшие действия с базами данных, что пригодится в работе. Также платформа предоставляет простые практические задания, которые позволяют познакомиться с SQL на реальных примерах.

Плюсы:
- Удобный интерфейс платформы;
- Отсутствие необходимости регистрации;
- Наличие практических заданий.
Минусы:
Типы баз данных
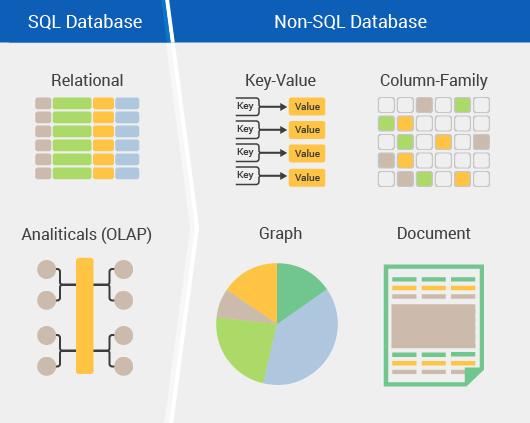
Есть много разных типов баз данных. Лучшая база данных для конкретной организации зависит от того, как организация намеревается использовать данные.
- Реляционные базы данных. Реляционные базы данных стали доминирующими в 1980-х годах. Элементы в реляционной базе данных организованы как набор таблиц со столбцами и строками. Технология реляционных баз данных обеспечивает наиболее эффективный и гибкий способ доступа к структурированной информации.
- Объектно-ориентированные базы данных. Информация в объектно-ориентированной базе данных представлена в виде объектов, как в объектно-ориентированном программировании.
- Распределенные базы данных. Распределенная база данных состоит из двух или более файлов, расположенных на разных сайтах. База данных может храниться на нескольких компьютерах, находиться в одном физическом месте или разбросана по разным сетям.
- Хранилища данных. Централизованное хранилище данных, хранилище данных — это тип базы данных, специально разработанный для быстрого запроса и анализа.
- Базы данных NoSQL. NoSQL, или нереляционная база данных, позволяет хранить и обрабатывать неструктурированные и полуструктурированные данные (в отличие от реляционной базы данных, которая определяет, как должны быть составлены все данные, вставленные в базу данных). Базы данных NoSQL становились популярными по мере того, как веб-приложения становились все более распространенными и сложными.
- Графовые базы данных. База данных графов хранит данные в терминах сущностей и отношений между сущностями.
- Базы данных OLTP. База данных OLTP — это быстрая аналитическая база данных, предназначенная для большого количества транзакций, выполняемых несколькими пользователями.
Это лишь некоторые из нескольких десятков типов баз данных, используемых сегодня. Другие, менее распространенные базы данных предназначены для очень конкретных научных, финансовых или других функций. Помимо различных типов баз данных, изменения в подходах к разработке технологий и значительные достижения, такие как облачные технологии и автоматизация, продвигают базы данных в совершенно новых направлениях. Некоторые из последних баз данных включают:
- Базы данных с открытым исходным кодом (OpenSource). Система баз данных с открытым исходным кодом — это система с открытым исходным кодом; такие базы данных могут быть базами данных SQL или NoSQL.
- Облачные базы данных (Cloud Database). Облачная база данных — это набор структурированных или неструктурированных данных, который хранится на частной, общедоступной или гибридной платформе облачных вычислений. Существует два типа моделей облачных баз данных: традиционные и база данных как услуга (DBaaS). В случае DBaaS административные задачи и обслуживание выполняются поставщиком услуг.
- Многомодельная база данных. Мультимодельные базы данных объединяют различные типы моделей баз данных в единую интегрированную серверную часть. Это означает, что они могут поддерживать различные типы данных.
- База данных Документов / JSON. Базы данных документов, разработанные для хранения, извлечения и управления документально-ориентированной информацией, представляют собой современный способ хранения данных в формате JSON, а не в строках и столбцах.
- Автономные базы данных. Новейший и самый революционный тип базы данных, автономные базы данных (также известные как автономные базы данных) являются облачными и используют машинное обучение для автоматизации настройки базы данных, обеспечения безопасности, резервного копирования, обновления и других рутинных задач управления, традиционно выполняемых администраторами баз данных.
SQLite Administrator
Сайт производителя: http://sqliteadmin.orbmu2k.de/
Цена:
| Критерий | Оценка (от 0 до 2) | |
| Функциональность | 2 | |
| Цена | 2 | |
| Работа с UTF-8 | ||
| Русский интерфейс | 1 | |
| Удобство | 2 | |
| Итог | 7 |
Достаточно удобная в использовании и функциональная программа. Вся структура базы данных представлена в виде дерева объектов, которое можно настраивать в зависимости от своих предпочтений. Судя по всему SQLite Administrator написан с использованием Delphi, т.к. среди дополнительных функций программы есть генерация кода Delphi по выделенному фрагменту SQL. Для создания таблиц, триггеров и т.д. используются удобные мастера. При использовании этой программы очень сильно огорчило отсутствие возможности нормальной работы с UTF-8 и, незначительно, но всё же несколько подпортил впечатление русский интерфейс – некоторые надписи не помещаются в отведенное им место. ак что при тестировании использовал дефолтный English.
Если для вас не принципиально использование UTF-8, то качайте SQLite Administrator – не пожалеете.