Иерархическая база данных и реляционная база данных 2021
Содержание:
Ограничения типа данных hierarchyid
Тип данных hierarchyid имеет следующие ограничения.
-
Столбец типа hierarchyid не принимает древовидную структуру автоматически. Приложение должно создать и назначить значения hierarchyid таким образом, чтобы они отражали требуемые связи между строками. Некоторые приложения могут содержать столбец типа hierarchyid , указывающий местоположение в иерархии, определенной в другой таблице.
-
Параллельными процессами создания и присвоения значений hierarchyid управляет само приложение. Нет никакой гарантии, что значения hierarchyid уникальны, если приложение не использует ограничение уникального ключа или не обеспечивает уникальность своей логикой.
-
Иерархические связи, представленные значениями типа hierarchyid , не обеспечиваются и не проверяются, как связи по внешнему ключу. Можно, а иногда и удобно иметь иерархическую связь, в которой у A есть потомок B и когда A удаляется, у B остается связь с несуществующей записью. Если это неприемлемо, приложение должно запросить потомков, прежде чем удалять родителей.
Иерархические
Иерархия — это когда есть вышестоящий, а есть его подчинённые, кто ниже. У них могут быть свои подчинённые и так далее. Мы уже касались такой модели, когда говорили про деревья и бустинг.
В такой базе данных сразу видно, к чему относятся записи, где они лежат и как до них добраться. Самый простой пример такой базы данных — хранение файлов и папок на компьютере:

Видно, что на диске C: есть много папок: Dropbox, eSupport, GDrive и все те, которые не поместились на экране.
Внутри папки GDrive есть ###_Inbox и #_Альбатрос, а внутри #_Альбатроса — десятки других папок. Если мы посмотрим на скриншот, то увидим, то должностная инструкция бухгалтера лежит с остальными файлами внутри папки Должностные и охрана труда, которая лежит внутри папки Инструкции.
Иерархическая база данных знает, кто кому подчиняется, и поэтому может быстро находить нужную информацию. Но такие базы можно организовать только в том случае, когда у вас есть чёткое разделение в данных, что главнее, а что ему подчиняется.
Классификации СУБД
Существует несколько признаков, по которым можно классифицировать СУБД.
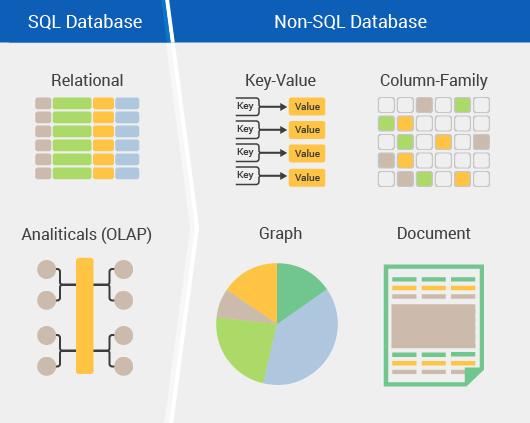
СУБД по модели данных бывают:
- Иерархические СУБД
- Сетевые СУБД
- Реляционные СУБД
- Объектно-ориентированные СУБД
- Объектно-реляционные СУБД
В настоящее время в серьезных проекта используются 2 последних типа.
СУБД по степени распределённости
- Локальные (СУБД размещается только на одном компьютере)
- Распределённые (части СУБД могут размещаться на 2-х и более компьютерах).
По способу доступа к БД
Файл-серверные СУБД
В них файлы с данными расположены централизованно на специальном файл-сервере. СУБД же должны быть расположены на каждом клиенте (рабочей станции). Доступ СУБД к данным производится посредством локальной сети. Поддержка синхронизации чтений и обновлений осуществляется за счет временных блокировок затребованных файлов.
Плюсом этой архитектуры можно назвать низкую нагрузку на файловый сервер.
К минусам же: высокая загрузка трафиком локальной сети; сложность или невозможность централизованного управления; нельзя обеспечить такие важные характеристики как надёжность, доступность и безопасность. Файл-серверные СУБД используют в локальных приложениях; в системах с малой интенсивностью обработки данных и небольшими пиковыми нагрузками на базу данных.
Сейчас её при создании крупной информационной системы не используют.
Примеры файл-серверных СУБД:
- dBase,
- FoxPro,
- Microsoft Access,
- Paradox,
- Visual FoxPro.
Клиент-серверные СУБД
Клиент-серверная СУБД расположена на сервере вместе с базой данных и осуществляет доступ к БД исключительно в монопольном режиме. Все запросы на обработку данных клиентских приложений и станций обрабатываются централизованно.
Недостатком такого типа СУБД можно назвать повышенные требования к серверу.
Достоинствами: более низкую загрузку локальной сети; преимущества централизованного управления; поддержку высокой надёжности, доступности и безопасности.
Примеры клиент-серверных СУБД:
- Caché,
- Firebird,
- IBM DB2,
- Informix,
- Interbase,
- MS SQL Server,
- MySQL, Oracle,
- PostgreSQL,
- Sybase Adaptive Server Enterprise,
- ЛИНТЕР.
Встраиваемые СУБД
Это вид СУБД, который может выступать лишь в качестве составной части определенного программного комплекса, без необходимости процедуры отдельной установки. Такой вид СУБД может быть использован для локального хранения данных своего приложения и не рассчитан на коллективное использование в компьютерной сети. Физически же это зачастую реализуется в виде подключаемой библиотеки. Со стороны приложения доступ к данным происходит посредством SQL-запросов либо через специальный программный интерфейс.
Примеры встраиваемых СУБД:
- Firebird Embedded,
- BerkeleyDB,
- Microsoft SQL Server Compact,
- OpenEdge,
- SQLite,
- ЛИНТЕР.
Для рассмотрения лишь части основных возможностей и внутреннего устройства любой СУБД требуется один или несколько отдельных учебных курсов.
Операции над данными
- ДОБАВИТЬ в базу данных новую запись. Для корневой записи обязательно формирование значения ключа.
- ИЗМЕНИТЬ значение данных предварительно извлеченной записи. Ключевые данные не должны подвергаться изменениям.
- УДАЛИТЬ некоторую запись и все подчиненные ей записи.
- ИЗВЛЕЧЬ:
— извлечь корневую запись по ключевому значению, допускается также последовательный просмотр корневых записей
— извлечь следующую запись (следующая запись извлекается в порядке левостороннего обхода дерева)
В операции ИЗВЛЕЧЬ допускается задание условий выборки (например, извлечь сотрудников с окладом более 1 тысячи руб.)
Как видим, все операции изменения применяются только к одной «текущей» записи (которая предварительно извлечена из базы данных). Такой подход к манипулированию данных получил название «навигационного».
Структурная часть иерархической модели
Основными информационными единицами в иерархической модели данных являются сегмент и поле. Поле данных определяется как наименьшая неделимая единица данных, доступная пользователю. Для сегмента определяются тип сегмента и экземпляр сегмента. Экземпляр сегмента образуется из конкретных значений полей данных. Тип сегмента — это поименованная совокупность входящих в него типов полей данных.
Как и сетевая, иерархическая модель данных базируется на графовой форме построения данных, и на концептуальном уровне она является просто частным случаем сетевой модели данных. В иерархической модели данных вершине графа соответствует тип сегмента или просто сегмент, а дугам — типы связей предок — потомок. В иерархических структуpax сегмент — потомок должен иметь в точности одного предка.
Иерархическая модель представляет собой связный неориентированный граф древовидной структуры, объединяющий сегменты. Иерархическая БД состоит из упорядоченного набора деревьев.
Сравниваем три модели баз данных
Первая, иерархическая модель данных, имеет древовидную структуру («родитель-потомок»), и поддерживает только отношения типа «один к одному» или «один ко многим». Эта модель позволяет быстро получать данные, но не отличается гибкостью. Иногда роль элемента (родителя или потомка) неясна и не подходит для иерархической модели.
Вторая, сетевая модель данных, имеет более гибкую структуру, чем иерархическая модель данных, и поддерживает отношения «многие ко многим». Но быстро становится слишком сложной и неудобной для управления.
Третья модель — реляционная — более гибкая, чем иерархическая и проще для управления, чем сетевая. Реляционная модель сегодня используется чаще всего.
Объект в реляционной модели баз данных определяется как позиция информации, хранимой в базе данных. Объект может быть осязаемым или неосязаемым. Примером осязаемого объекта может быть сотрудник организации, а примером неосязаемой сущности — учётная запись покупателя. Объекты определяются атрибутами — информационным отображением свойств объекта. Эти атрибуты также известны как столбцы, а группа столбцов — как ряд. Ряд также можно определить как экземпляр объекта.
Объекты связываются отношениями, основные типы которых можно определить следующим образом:
«Один к одному»
В этом виде отношений один объект связан с другим. Например, Менеджер -> Отдел.
У каждого менеджера может быть только один отдел, и наоборот.
«Один ко многим»
В моделях данных отношение одного объекта с несколькими. Например, Сотрудник -> Отдел.
Каждый сотрудник может быть только в одном отделе, но в самом отделе может быть больше одного сотрудника.
«Многие ко многим»
В заданный момент времени объект может быть связан с любым другим. Например, Сотрудник -> Проект.
Сотрудник может участвовать в нескольких проектах, и каждый проект может объединять несколько сотрудников.
В реляционной модели объекты и их отношения представлены двухмерным массивом или таблицей.
Каждая таблица представляет объект.
Каждая таблица состоит из рядов и столбцов.
Отношения между объектами представлены столбцами.
Каждый столбец представляет атрибут объекта.
Значения столбцов выбираются из области или набора всех возможных значений.
Столбцы, которые используются для связи объектов, называются ключевыми. Есть два типа ключей — первичные и внешние.
Первичные служат для однозначного определения объекта. Внешний ключ — это первичный ключ одного объекта, существующий как атрибут в другой таблице.
Преимущества реляционной модели данных:
- Простота использования.
- Гибкость.
- Независимость данных.
- Безопасность.
- Простота практического применения.
- Слияние данных.
- Целостность данных.
Недостатки:
- Избыточность данных.
- Низкая производительность.
Примеры
Простой пример
Следующий пример намеренно упрощен, чтобы легче было приступить к работе. Сначала создайте таблицу для хранения определенных географических данных.
Теперь введите данные для некоторых континентов, стран, штатов и городов.
Выберите данные, добавляя столбец, который преобразовывает данные уровня в текстовое значение, удобное для восприятия. Этот запрос также отсортирует результат по типу данных hierarchyid .
Результирующий набор:
Обратите внимание, что иерархия имеет допустимую структуру, несмотря на отсутствие внутреннего согласования. Байя — единственный штат
Он отображается в иерархии как одноранговый по отношению к городу Бразилиа. Аналогично полярная станция Макмердо не имеет родительской страны. Необходимо решить, подходит ли этот тип иерархии для использования.
Добавьте еще одну строку и выберите результаты.
Это демонстрирует наличие других возможных проблем. Киото можно ввести в качестве уровня даже при отсутствии родительского уровня . И Лондон и Киото имеют одинаковое значение свойства hierarchyid. Опять-таки пользователи должны решить, подходит ли этот тип иерархии для использования, и заблокировать значения, недопустимые для использования.
Кроме того, в этой таблице не используется верхняя часть иерархии . Она была опущена, потому что общий родительский объект для всех континентов отсутствует. Его можно добавить путем добавления всей планеты.
Объектно-ориентированные субд
Появление объектно-ориентированных СУБД вызвано потребностями программистов на ОО-языках, которым были необходимы средства для хранения объектов, не помещавшихся в оперативной памяти компьютера. Также важна была задача сохранения состояния объектов между повторными запусками прикладной программы. Поэтому, большинство ООСУБД представляют собой библиотеку, процедуры управления данными которой включаются в прикладную программу. Примеры реализации ООСУБД как выделеного сервера базы данных крайне редки.
Сразу же необходимо заметить, что общепринятого определения «объектно-ориентированной модели данных» не существует. Сейчас можно говорить лишь о неком «объектном» подходе к логическому представлению данных и о различных объектно-ориентированных способах его реализации.
Структура
Структура объектной модели описываются с помощью трех ключевых понятий:
инкапсуляция — каждый объект обладает некоторым внутренним состоянием (хранит внутри себя запись данных), а также набором методов — процедур, с помощью которых (и только таким образом) можно получить доступ к данным, определяющим внутреннее состояние объекта, или изменить их. Таким образом, объекты можно рассматривать как самостоятельные сущности, отделенные от внешнего мира;
наследование — подразумевает возможность создавать из классов объектов новые классы объекты, которые наследуют структуру и методы своих предков, добавляя к ним черты, отражающие их собственную индивидуальность. Наследование может быть простым (один предок) и множественным (несколько предков);
полиморфизм — различные объекты могут по разному реагировать на одинаковые внешние события в зависимости от того, как реализованы их методы.
Целостность данных
Для поддержания целостности объектно-ориентированный подход предлагает использовать следующие средства:
автоматическое поддержание отношений наследования возможность объявить некоторые поля данных и методы объекта как «скрытые», не видимые для других объектов; такие поля и методы используются только методами самого объекта создание процедур контроля целостности внутри объекта
Средства манипулирования данными
К сожалению, в объектно-ориентированном программировании отсутствуют общие средства манипулирования данными, такие как реляционная алгебра или реляционное счисление. Работа с данными ведется с помощью одного из объектно-ориентированных языков программирования общего назначения, обычно это SmallTalk, C++ или Java.
В объектно-ориентированных базах данных, в отличие от реляционных, хранятся не записи, а объекты. ОО-подход представляет более совершенные средства для отображения реального мира, чем реляционная модель, естественное представление данных. В реляционной модели все отношения принадлежат одному уровню, именно это осложняет преобразование иерархических связей модели «сущность-связь» в реляционную модель. ОО-модель можно рассматривать послойно, на разных уровнях абстракции. Имеется возможность определения новых типов данных и операций с ними.
В то же время, ОО-модели присущ и ряд недостатков:
осутствуют мощные непроцедурные средства извлечения объектов из базы. Все запросы приходится писать на процедурных языках, проблема их оптимизации возлагается на программиста;
вместо чисто декларативных ограничений целостности (типа явного объявления первичных и внешних ключей реляционных таблиц с помощью ключевых слов PRIMARY KEY и REFERENCES) или полудекларативных триггеров для обеспечения внутренней целостности приходится писать процедурный код.
Очевидно, что оба эти недостатка связаны с отсутствием развитых средств манипулирования данными. Эта задача решается двумя способами — расширение ОО-языков в сторону управления данными (стандарт ODMG), либо добавление объектных свойств в реляционные СУБД (SQL-3, а также так называемые объектно-реляционных СУБД).
Управляющая часть иерархической модели
В рамках иерархической модели выделяют языковые средства описания данных (ЯОД) и средства манипулирования данными (ЯМД). Каждая физическая база описывается набором операторов, обусловливающих как её логическую структуру, так и структуру хранения БД. При этом способ доступа устанавливает способ организации взаимосвязи физических записей.
Определены следующие способы доступа:
- иерархически последовательный;
- иерархически индексно-последовательный;
- иерархически прямой;
- иерархически индексно-прямой;
- индексный.
Помимо задания имени БД и способа доступа описания должны содержать определения типов сегментов, составляющих БД, в соответствии с иерархией, начиная с корневого сегмента. Каждая физическая БД содержит только один корневой сегмент, но в системе может быть несколько физических БД.
Среди операторов манипулирования данными можно выделить операторы поиска данных, операторы поиска данных с возможностью модификации, операторы модификации данных. Набор операций манипулирования данными в иерархической БД невелик, но вполне достаточен.
История
Одна из первых новаторских работ по моделированию информационных систем была сделана Янгом и Кентом (1958), которые отстаивали «точный и абстрактный способ определения информационных и временных характеристик проблемы обработки данных ». Они хотели создать «нотацию, которая позволит аналитику организовать проблему вокруг любого устройства ». Их работа была первой попыткой создать абстрактную спецификацию и инвариантную основу для разработки различных альтернативных реализаций с использованием различных аппаратных компонентов. Следующий шаг в моделировании ИБ был сделан CODASYL , консорциумом ИТ-индустрии, образованным в 1959 году, который, по сути, стремился к тому же, что и Янг и Кент: разработка «надлежащей структуры для машинно-независимого языка определения проблем на системном уровне. обработки данных ». Это привело к развитию специальной информационной алгебры ИБ .
В 1960-х годах моделирование данных приобрело большее значение с появлением концепции информационной системы управления (MIS). По словам Леондеса (2002), «в это время информационная система предоставляла данные и информацию для целей управления. Система баз данных первого поколения , получившая название Integrated Data Store (IDS), была разработана Чарльзом Бахманом из General Electric. Две известные базы данных модели, сетевая модель данных и иерархическая модель данных , были предложены в течение этого периода времени «. К концу 1960-х Эдгар Ф. Кодд разработал свои теории организации данных и предложил реляционную модель для управления базами данных, основанную на логике предикатов первого порядка .
В 1970-х годах моделирование отношений сущностей возникло как новый тип концептуального моделирования данных, первоначально предложенный в 1976 году Питером Ченом . Модели сущностных отношений использовались на первом этапе проектирования информационной системы во время анализа требований для описания информационных потребностей или типа информации, которая должна храниться в базе данных . Этот метод может описывать любую онтологию , т. Е. Обзор и классификацию концепций и их взаимосвязей для определенной области интересов .
В 1970 — е годы GM Nijssen разработала «Natural Language Information Analysis Method» метод (Niam), и разработали это в 1980 — х годах в сотрудничестве с Терри Halpin в объектно-Роль моделирования (ORM). Однако именно докторская диссертация Терри Халпина в 1989 году создала формальную основу, на которой основано объектно-ролевое моделирование.
Билл Кент в своей книге 1978 года « Данные и реальность» сравнил модель данных с картой территории, подчеркнув, что в реальном мире «шоссе не окрашены в красный цвет, у рек нет линий графств, проходящих посередине, и вы не вижу контурных линий на горе ». В отличие от других исследователей, которые пытались создать математически чистые и элегантные модели, Кент подчеркивал существенную беспорядок в реальном мире и задачу разработчика моделей данных — создать порядок из хаоса без чрезмерного искажения истины.
В 1980-х годах, согласно Яну Л. Харрингтону (2000), «развитие объектно-ориентированной парадигмы привело к фундаментальным изменениям в нашем подходе к данным и процедурам, которые работают с ними. Традиционно данные и процедуры были хранятся отдельно: данные и их взаимосвязь в базе данных, процедуры в прикладной программе. Однако объектная ориентация объединила процедуру сущности с ее данными ».
В начале 1990-х годов три голландских математика Гвидо Бакема, Харм ван дер Лек и Ян Питер Цварт продолжили развитие работы Г. М. Нейссена . Они больше сосредоточились на коммуникационной части семантики. В 1997 году они формализовали метод полностью коммуникационно-ориентированного информационного моделирования FCO-IM .
В чём преимущества
Базы данных и их системы управления заточены на работу с большим объёмом данных и от лица большого числа пользователей. Сейчас вы поймёте.
Скорость — ещё одно преимущество базы данных. База данных устроена так, что она легко и быстро находит, записывает, переписывает и снова находит данные. Всё потому, что СУБД всегда знает, что где лежит и по какому критерию искать. Там не будет случайных данных в случайном месте.
Скорость важна ещё и потому, что СУБД обычно обслуживает сразу много потоков: одновременно ей могут пользоваться десятки и сотни тысяч человек, поэтому ей некогда копаться. В хорошо сделанных БД всё молниеносно.
Сложность. Базы данных нужны в числе прочего для хранения сложно структурированных данных. Мы привыкли думать, что база данных — это такая таблица, где есть строки и столбцы. Но база данных при правильной организации может намного больше:
- Связывать одну единицу данных с множеством других. Например, если один человек совершил много заказов со множеством товаров внутри каждого, база данных способна хранить и обрабатывать такие связи.
- База может хранить дерево данных — вроде того, о котором мы писали недавно. Попробуй в реальной жизни похранить дерево!
- В базах могут жить ссылки на другие фрагменты и отделы базы.
Базу можно представить как таблицу, но лишь в самом упрощённом виде. Для более сложных задач базу можно представить как очень сложное дерево, или огромный склад упорядоченных коробок, или даже как огромный завод по фасовке данных.
Примеры типичных операторов поиска данных
- найти указанное дерево БД;
- перейти от одного дерева к другому;
- найти экземпляр сегмента, удовлетворяющий условию поиска;
- перейти от одного сегмента к другому внутри дерева;
- перейти от одного сегмента к другому в порядке обхода иерархии.
Примеры типичных операторов поиска данных с возможностью модификации:
- найти и удержать для дальнейшей модификации единственный экземпляр сегмента, удовлетворяющий условию поиска;
- найти и удержать для дальнейшей модификации следующий экземпляр сегмента с теми же условиями поиска;
- найти и удержать для дальнейшей модификации следующий экземпляр для того же родителя.
Примеры типичных операторов модификации иерархически организованных данных, которые выполняются после выполнения одного из операторов второй группы (поиска данных с возможностью модификации):
- вставить новый экземпляр сегмента в указанную позицию;
- обновить текущий экземпляр сегмента;
- удалить текущий экземпляр сегмента.
В иерархической модели автоматически поддерживается целостность ссылок между предками и потомками. Основное правило: никакой потомок не может существовать без своего родителя.
Реляционная модель базы данных
В реляционной модели, в отличие от иерархической или сетевой, не существует физических отношений. Вся информация хранится в виде таблиц (отношений), состоящих из рядов и столбцов. А данные двух таблиц связаны общими столбцами, а не физическими ссылками или указателями. Для манипуляций с рядами данных существуют специальные операторы.
В отличие от двух других типов СУБД, в реляционных моделях данных нет необходимости просматривать все указатели, что облегчает выполнение запросов на выборку информации по сравнению с сетевыми и иерархическими СУБД. Это одна из основных причин, почему реляционная модель оказалась более удобна. Распространённые реляционные СУБД: Oracle, Sybase, DB2, Ingres, Informix и MS-SQL Server.
«В реляционной модели, как объекты, так и их отношения представлены только таблицами, и ничем более».
РСУБД — реляционная система управления базами данных, основанная на реляционной модели Э. Ф. Кодда. Она позволяет определять структурные аспекты данных, обработки отношений и их целостности. В такой базе информационное наполнение и отношения внутри него представлены в виде таблиц — наборов записей с общими полями.
Реляционные таблицы обладают следующими свойствами:
- Все значения атомарны.
- Каждый ряд уникален.
- Порядок столбцов не важен.
- Порядок рядов не важен.
- У каждого столбца есть своё уникальное имя.
Некоторые поля могут быть определены как ключевые. Это значит, что для ускорения поиска конкретных значений будет использоваться индексация. Когда поля двух различных таблиц получают данные из одного набора, можно использовать оператор JOIN для выбора связанных записей двух таблиц, сопоставив значения полей.
Часто у полей будет одно и то же имя в обеих таблицах. Например, таблица «Заказы» может содержать пары «ID-покупателя» и «код-товара». А в таблице «Товар» могут быть пары «код-товара» и «цена». Поэтому чтобы рассчитать чек для определённого покупателя, необходимо суммировать цену всех купленных им товаров, использовав JOIN в полях «код-товара» этих двух таблиц. Такие действия можно расширить до объединения нескольких полей в нескольких таблицах.
Поскольку отношения здесь определяются только временем поиска, реляционные базы данных классифицируются как динамические системы.
3) реляционная структура базы данных
Все данные представлены в виде простых таблиц, разбитых на строки и столбцы, на пересечении которых расположены данные. Подробно об этом мы будем говорить в следующих уроках, здесь же хочется отметить, что эта структура стала настоящим прорывом в развитии баз данных.
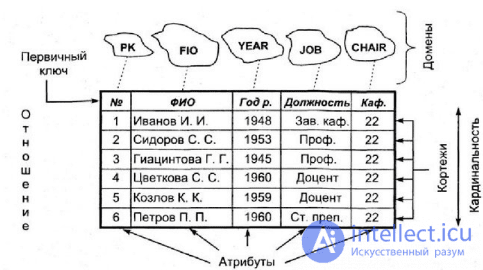
Рис элементы реляционной модели
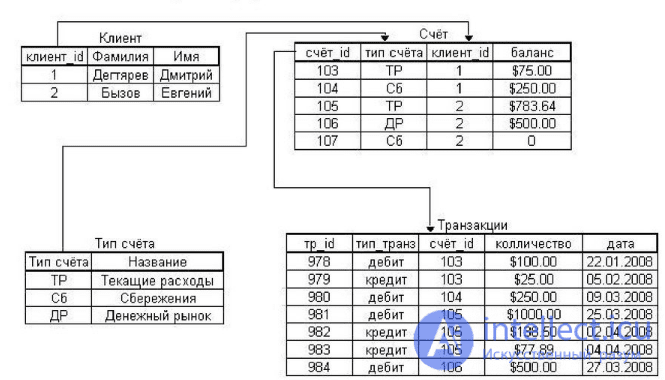
Рис пример реляционной модели
Достоинства реляционной модели данных
- Простота работы и отражение представлений пользователя
- Гибкость (соединение, разделение файлов)
- Простота внедрения плоских файлов
- Отделение от физической реализации (независимость)
- Произвольная структура запросов
- Хорошее теоретическое обоснование
Недостатки реляционной модели данных
- Сложность структуры, вызванная процессом нормализации
- Низкая производительность из-за поиска по ключу (что в 3-5 раз увеличивает количество операций доступа)
- Ограниченный набор типов данных (например, отсутствуют форматы мультимедиа, геоинформации и т.д.)
- Недостаточное естественное представление данных (в виде плоских двумерных таблиц, а не таблиц со сложной структурой, как в сетевой модели данных)
- Невозможность рассмотрения данных послойно, на разных уровнях абстракции
- Невозможность определить набор операторов (методов), связанных с определенным типом данных (приходится задавать операции в конкретном
- приложении)
Сетевые
В отличие от реляционных баз, в сетевых между таблицами и записями может быть несколько разных связей, каждая из который отвечает за что-то своё.
Если мы возьмём базу данных с сайта Кинопоиска, то она может выглядеть так:
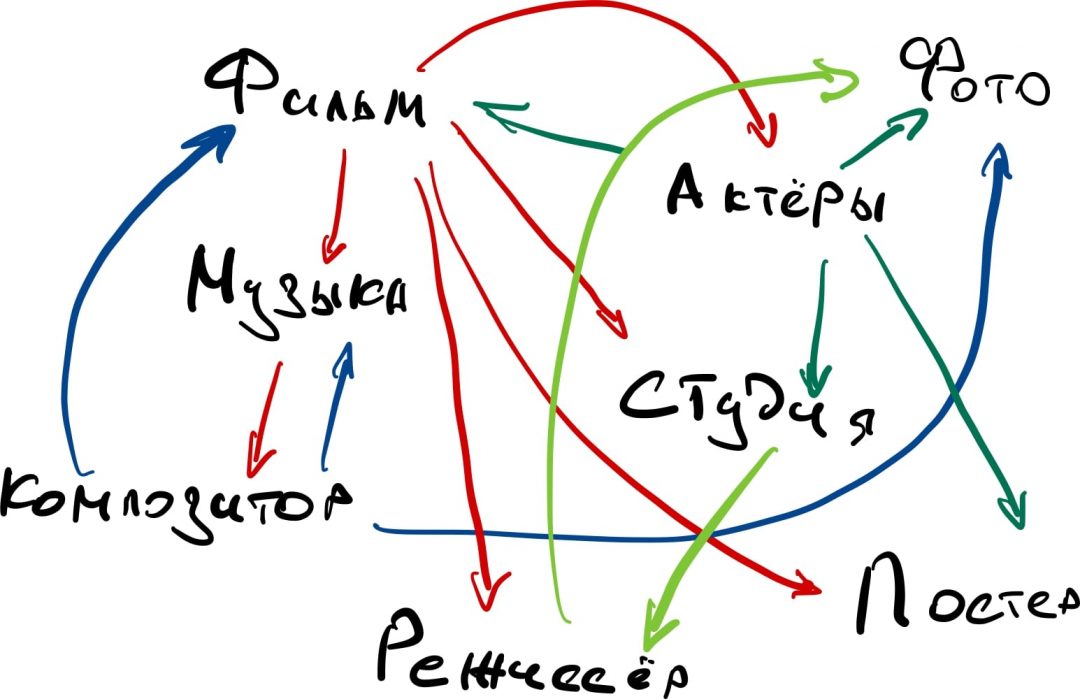
Особенность сетевой базы данных в том, что в ней запоминаются все связи и всё содержимое для каждой связи. Базе не нужно тратить время на поиск нужных данных, потому что вся информация об этом уже есть в специальных индексных файлах. Они показывают, какая запись с какой связана, и быстро выдают результат.
Например, вы посмотрели «Начало» Кристофера Нолана и вам понравился этот фильм. Когда вы перейдёте к списку фильмов, которые он ещё снял, база на сайте сделает так:
- возьмёт имя режиссёра;
- посмотрит, какие связи и с чем у него есть;
- выдаст список фильмов;
- к этим фильмам может сразу подгрузить список актёров, которые там играют;
- и сразу же показать постеры к каждому фильму.
А главное — база сделает это очень быстро, потому что ей не нужно просматривать всю базу в поисках нужных фильмов. Она сразу видит, какие фильмы с чем связаны, и выдаёт ответ.