Разработка приложений и баз данных: точки соприкосновения
Содержание:
Проблемы использования баз данных
Сегодняшние крупные корпоративные базы данных часто поддерживают очень сложные запросы и, как ожидается, дадут почти мгновенные ответы на эти запросы. В результате администраторы баз данных постоянно вынуждены использовать самые разные методы для повышения производительности. Вот некоторые общие проблемы, с которыми они сталкиваются:
Управление лавинообразно растущими объемами данных. Стремительный рост количества данных, поступающих от датчиков, подключенных компьютеров и десятков других источников, заставляет администраторов баз данных изо всех сил пытаться управлять и организовывать этот сложный массив данных своих компаний.
Обеспечение безопасности данных. В наши дни утечки данных происходят повсеместно, и хакеры становятся все изобретательнее
Как никогда важно, чтобы данные были в безопасности, но при этом были легко доступны для пользователей. Идти в ногу со спросом
В сегодняшней быстро меняющейся деловой среде компаниям необходим доступ в режиме реального времени к своим данным, чтобы поддерживать своевременное принятие решений и использовать новые возможности.
Управление и обслуживание базы данных и инфраструктуры. Администраторы баз данных должны постоянно следить за базой данных на предмет проблем и выполнять профилактическое обслуживание, а также применять обновления программного обеспечения и исправления. По мере того, как базы данных становятся более сложными, а объемы данных растут, компании сталкиваются с расходами на привлечение дополнительных специалистов для отслеживания и настройки своих баз данных.
Снятие ограничений на масштабируемость. Чтобы выжить, бизнесу необходимо расти, и вместе с ним должно расти и управление данными. Но администраторам баз данных очень сложно предсказать, какой объем ресурсов потребуется компании, особенно для локальных баз данных.
Решение всех этих проблем может занять много времени и может помешать администраторам баз данных выполнять более стратегические функции.
Этапы проектирования базы данных
Этап начальной разработки
- анализ деятельности компании;
- анализ структуры компании;
- спецификация требований;
- определение целей;
- сферы применения;
- границы возможностей.
Концептуальное проектирование базы данных
- анализ требований к базе данных, выявление представлений конечных пользователей и требований к обработке транзакций;
- определение сущностей, атрибутов и связей;
- разработка ER-диаграмм (от ER — Entity-Relationship — Сущность-Связь);
- нормализация;
- проверка модели данных, выявление основных процессов (правила ввода, обновления и удаления данных);
- проверка отчётов, запросов, представлений, целостности, совместного использования и безопасности.
Определение ключевых полей
Выше неоднократно упоминалось понятие ключевого поля. Ключевое поле — это одно или несколько полей, комбинация значений которых однозначно определяет каждую запись в таблице. Если для таблицы определены ключевые поля, то Microsoft Access предотвращает дублирование или ввод пустых значений в ключевое поле. Ключевые поля используются для быстрого поиска и связи данных из разных таблиц при помощи запросов, форм и отчетов.
В Microsoft Access можно выделить три типа ключевых полей: счетчик, простой ключ и составной ключ. Рассмотрим каждый из этих типов.
Для создания ключевого поля типа Счетчик необходимо в режиме Конструктора таблиц:
- Включить в таблицу поле счетчика.
- Задать для него автоматическое увеличение на 1.
- Указать это поле в качестве ключевого путем нажатия на кнопку Ключевое поле (Primary Key) на панели инструментов Конструктор таблиц (Table Design).
Если до сохранения созданной таблицы ключевые поля не были определены, то при сохранении будет выдано сообщение о создании ключевого поля. При нажатии кнопки Да (Yes) будет создано ключевое поле счетчика с именем Код (ID) и типом данных Счетчик (AutoNumber).
Для создания простого ключа достаточно иметь поле, которое содержит уникальные значения (например, коды или номера). Если выбранное поле содержит повторяющиеся или пустые значения, его нельзя определить как ключевое. Для определения записей, содержащих повторяющиеся данные, можно выполнить запрос на поиск повторяющихся записей. Если устранить повторы путем изменения значений невозможно, следует либо добавить в таблицу поле счетчика и сделать его ключевым, либо определить составной ключ.
Составной ключ необходим в случае, если невозможно гарантировать уникальность записи с помощью одного поля. Он представляет собой комбинацию нескольких полей. Для определения составного ключа необходимо:
- Открыть таблицу в режиме Конструктора.
- Выделить поля, которые необходимо определить как ключевые.
- Нажать кнопку Ключевое поле (Primary Key) на панели инструментов Конструктор таблиц (Table Design).
Для составного ключа существенным может оказаться порядок образующих ключ полей. Сортировка записей осуществляется в соответствии с порядком ключевых полей в окне Конструктора таблицы. Если необходимо указать другой порядок сортировки без изменения порядка ключевых полей, то сначала нужно определить ключ, а затем нажать кнопку Индексы (Indexes) на панели инструментов Конструктор таблиц (Table Design). Затем в появившемся окне Индексы (Indexes) нужно указать другой порядок полей для индекса с именем Ключевое поле (Primary Key).
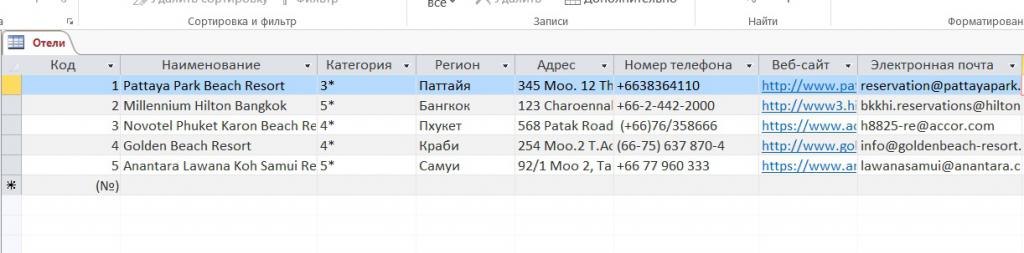
Рассмотрим в качестве примера применения составного ключа таблицу «Заказано» (OrderDetails) базы данных (Northwind) (рис. 2.23).
В данном случае в качестве составного ключа используются поля «Код заказа» (OrderlD) и «КодТовара» (ProductID), т. к. ни одно из этих полей в отдельности не гарантирует уникальность записи. При этом в таблице выводится не код товара, а наименование товара, т. к. поле «КодТовара» (ProductID) данной таблицы содержит подстановку из таблицы «Товары» (Products), а значения полей «КодТовара» (ProductID) этих таблиц связаны отношением «один-ко-многим» (одной записи таблицы «Товары» (Products) может соответствовать несколько записей таблицы «Заказано» (OrderDetails)). Оба поля могут содержать повторяющиеся значения. Так, один заказ может включать в себя несколько товаров, а в разные заказы могут включаться одинаковые товары. В то же время сочетание полей «КодЗаказа» (OrderlD) и «КодТовара» (ProductID) однозначно определяет каждую запись таблицы «Заказы» (OrderDetails).
Чтобы изменить ключ, необходимо:
- Открыть таблицу в режиме Конструктора.
- Выбрать имеющиеся ключевые поля.
- Нажать на кнопку Ключевое поле (Primary Key), при этом кнопка должна принять положение Выкл., а из области выделения должны исчезнуть значки ключевого поля.
- Выбрать поле, которое необходимо сделать ключевым.
- Нажать на кнопку Ключевое поле (Primary Key). При этом в области выделения должен появиться значок ключевого поля.
Чтобы удалить ключ, необходимо:
- Открыть таблицу в режиме Конструктора.
- Выбрать имеющееся ключевое поле (ключевые поля).
- Нажать на кнопку Ключевое поле (Primary Key), при этом кнопка должна принять положение Выкл., а из области выделения должен исчезнуть значок (значки) ключевого поля.
[править] Подходы к проектированию реляционных БД (РБД)
Первый подход (предложен Э. Коддом) основан на понятии «универсального отношения», то есть таблицы, состоящей из всех атрибутов предметной области (ПО). В дальнейшем такая таблица разбивается путем декомпозиции на несколько взаимосвязанных нормализованных таблиц. В результате на этапе концептуального проектирования создается реляционная схема БД.
Второй подход (объектный подход) основан на создании концептуальной модели данных, состоящей из описания объектов ПО и связей между ними. Затем эта модель преобразуется в реляционную модель. Процесс преобразования автоматически гарантирует получение нормализованной реляционной схемы БД.
Правило 1: Какова природа приложения (OLTP или OLAP)?
Когда вы начинаете разработку базы данных, первое, что нужно определить — природа приложения, которое вы разрабатываете: будет оно транзакционное или аналитическое? Многие разработчики находят применение трем нормальным формам не задумываясь о характере приложения, а затем у них возникают вопросы о том, как получить информацию о производительности и настройке. Как уже сказано выше, есть два вида приложений: основанные на транзакциях и аналитические. Давайте разберемся, что это за типы.
Транзакционный: в этом типе приложения ваш конечный пользователь больше интересуется четырьмя функциями CRUD: созданием, чтением, обновлением и удалением записей. Официальное название такой базы данных — OLTP.
Аналитический: в таких приложениях ваш конечный пользователь больше заинтересован в анализе, отчетности, прогнозировании и т. д. Эти типы баз данных имеют меньшее количество вставок и обновлений. Основная цель здесь — собрать и проанализировать данные как можно быстрее. Официальное название такой базы данных — OLAP.
Если вы считаете, что вставки, обновления и удаления будут использоваться чаще, то создайте нормализованный дизайн таблицы, или же создайте плоскую денормализованную структуру базы данных.
Ниже приведена простая диаграмма, показывающая, как имена и адрес в левой части составляют простую нормализованную таблицу. С помощью денормализованной структуры мы создали структуру плоской таблицы.
Правило 4: Относитесь к дублирующим неоднородным данным как к своему главному врагу.
Соберите и обработайте дубликаты данных. Основная проблема относительно повторяющихся данных заключается не в том, что требуется пространство на жестком диске, а в путанице, которую они создают.
Например, на приведенной ниже таблице вы можете заметить, что «5th Standard» и «Fifth standard» означает то же самое.Возможно данные попали в систему из-за плохого ввода данных или плохой проверки. Если вы когда-либо захотите получить отчет, они будут отображаться как разные объекты, что очень сбивает с толку.
Одно из возможных решений — перемещение в другую основную таблицу и их передача через внешние ключи. На рисунке ниже показано, мы создали новую главную таблицу под названием «Standards» и связали ее с помощью простого внешнего ключа.
Таблица как важная часть реляционной БД
Всем известно, что реляционная база данных состоит из таблиц. При этом каждая таблица включает в себя столбцы (поля либо атрибуты) и строки (записи либо кортежи).
Таблицы в таких БД обладают следующими свойствами:
— столбцы размещаются в определённом порядке, формируемом при создании таблицы. Таблица может не иметь ни одной строки, однако хотя бы один столбец должен быть обязательно;
— в таблице не может быть 2-х одинаковых строк. Если вспомнить математику, то такие таблицы называют отношениями (relation). Именно поэтому данные БД и считаются реляционными;
— каждый столбец в пределах таблицы имеет уникальное имя, а все значения в одном столбце должны быть одного типа (дата, текст, число и т. п.);
— на пересечении строки и столбца может быть только атомарное значение (значение, не состоящее из группы значений). Таблицы, которые удовлетворяют этим условиям, считаются нормализованными.
Основные этапы проектирования баз данных
Концептуальное (инфологическое) проектирование

Пример концептуальной схемы
Концептуальное (инфологическое) проектирование — построение семантической модели предметной области, то есть информационной модели наиболее высокого уровня абстракции. Такая модель создаётся без ориентации на какую-либо конкретную СУБД и модель данных. Термины «семантическая модель», «концептуальная модель» и «инфологическая модель» являются синонимами. Кроме того, в этом контексте равноправно могут использоваться слова «модель базы данных» и «модель предметной области» (например, «концептуальная модель базы данных» и «концептуальная модель предметной области»), поскольку такая модель является как образом реальности, так и образом проектируемой базы данных для этой реальности.
Конкретный вид и содержание концептуальной модели базы данных определяется выбранным для этого формальным аппаратом. Обычно используются графические нотации, подобные .
Чаще всего концептуальная модель базы данных включает в себя:
- описание информационных объектов или понятий предметной области и связей между ними.
- описание ограничений целостности, то есть требований к допустимым значениям данных и к связям между ними.
Логическое (даталогическое) проектирование
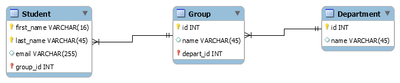
Пример логической схемы для реляционной модели данных.
Логическое (даталогическое) проектирование — создание схемы базы данных на основе конкретной модели данных, например, реляционной модели данных. Для реляционной модели данных даталогическая модель — набор схем отношений, обычно с указанием первичных ключей, а также «связей» между отношениями, представляющих собой внешние ключи.
Преобразование концептуальной модели в логическую модель, как правило, осуществляется по формальным правилам. Этот этап может быть в значительной степени автоматизирован.
На этапе логического проектирования учитывается специфика конкретной модели данных, но может не учитываться специфика конкретной СУБД.
Физическое проектирование
Физическое проектирование — создание схемы базы данных для конкретной СУБД. Специфика конкретной СУБД может включать в себя ограничения на именование объектов базы данных, ограничения на поддерживаемые типы данных и т. п. Кроме того, специфика конкретной СУБД при физическом проектировании включает выбор решений, связанных с физической средой хранения данных (выбор методов управления дисковой памятью, разделение БД по файлам и устройствам, методов доступа к данным), создание индексов и т. д.
Результатом физического проектирования логической схемы выше на языке SQL может являться следующий скрипт:
CREATE TABLE IF NOT EXISTS Department ( -- Факультет
id INT NOT NULL,
name VARCHAR(45),
PRIMARY KEY (id)
);
CREATE TABLE IF NOT EXISTS Group (
id INT NOT NULL,
name VARCHAR(45) ,
depart_id INT NOT NULL,
UNIQUE INDEX depart_id_UNIQUE (depart_id ASC),
PRIMARY KEY (id, depart_id),
CONSTRAINT depart_fk
FOREIGN KEY (depart_id)
REFERENCES Department (id)
);
CREATE TABLE IF NOT EXISTS Student (
first_name VARCHAR(16) NOT NULL,
last_name VARCHAR(45) NOT NULL,
email VARCHAR(255),
group_id INT NOT NULL,
PRIMARY KEY (last_name, first_name, group_id),
INDEX group_fk_idx (group_id ASC),
CONSTRAINT group_fk
FOREIGN KEY (group_id) REFERENCES Group (id)
);
[править] Основные шаги проектирования РБД с использованием объектного подхода
- Выделить объекты ПО и определить связи между ними (1:1, 1:М, М:N).
- Представить каждый объект ПО в виде таблицы, определив для нее первичный ключ и описав ограничения на значения данных.
- Представить каждую взаимосвязь вида 1:1 или 1:М с помощью внешнего ключа, добавив его в таблицу, находящуюся со стороны «многие».
- Представить каждую взаимосвязь вида М:N в виде отдельной таблицы с составным первичным ключом. Ввести в эту таблицу атрибуты, описывающие связь.
- Выполнить процедуру нормализации отношений (таблиц) в БД.
- Повторить перечисленные шаги пока не будет получен окончательный проект БД.
БД считается правильно спроектированной когда «один факт хранится один раз».
Создание связей между сущностями
Теперь, когда данные преобразованы в таблицы, нужно проанализировать связи между ними. Сложность базы данных определяется количеством элементов, взаимодействующих между двумя связанными таблицами. Определение сложности помогает убедиться, что вы разделили данные на таблицы наиболее эффективно.
Каждый объект может быть взаимосвязан с другим с помощью одного из трех типов связи:
Связь «один-к одному»
Когда существует только один экземпляр объекта A для каждого экземпляра объекта B, говорят, что между ними существует связь «один-к одному» (часто обозначается 1:1). Можно указать этот тип связи в ER-диаграмме линией с тире на каждом конце:
1:1
Но при определенных обстоятельствах целесообразнее создавать таблицы со связями 1:1. Если есть поле с необязательными данными, например «описание», которое не заполнено для многих записей, можно переместить все описания в отдельную таблицу, исключая пустые поля и улучшая производительность базы данных.
Чтобы гарантировать, что данные соотносятся правильно, в нужно будет включить, по крайней мере, один идентичный столбец в каждой таблице. Скорее всего, это будет первичный ключ.
Связь «один-ко-многим»
Эта связи возникают, когда запись в одной таблице связана с несколькими записями в другой. Например, один клиент мог разместить много заказов, или у читателя может быть сразу несколько книг, взятых в библиотеке. Связи «один- ко-многим» (1:M) обозначаются так называемой «меткой ноги вороны», как в этом примере:
1:Mодной1
Связь «многие-ко-многим»
Когда несколько объектов таблицы могут быть связаны с несколькими объектами другой. Говорят, что они имеют связь «многие-ко-многим» (M:N). Например, в случае студентов и курсов, поскольку студент может посещать много курсов, и каждый курс могут посещать много студентов.
На ER-диаграмме эти связи отображаются с помощью следующих строк:
один-ко-многим
Для этого нужно создать между этими двумя таблицами новую сущность. Если между продажами и продуктами существует связь M:N, можно назвать этот новый объект «sold_products», так как он будет содержать данные для каждой продажи. И таблица продаж, и таблица товаров будут иметь связь 1:M с sold_products. Этот вид промежуточного объекта в различных моделях называется таблицей ссылок, ассоциативным объектом или таблицей связей.
Каждая запись в таблице связей будет соответствовать двум сущностям из соседних таблиц. Например, таблица связей между студентами и курсами может выглядеть следующим образом:
Обязательно или нет?
Другим способом анализа связей является рассмотрение того, какая сторона связи должна существовать, чтобы существовала другая. Необязательная сторона может быть отмечена кружком на линии. Например, страна должна существовать для того, чтобы иметь представителя в Организации Объединенных Наций, а не наоборот:
один не может существовать без другого
Рекурсивные связи
Иногда при проектировании базы данных таблица указывает на себя саму. Например, таблица сотрудников может иметь атрибут «руководитель», который ссылается на другое лицо в этой же таблице. Это называется рекурсивными связями.
Лишние связи
Лишние связи — это те, которые выражены более одного раза
Как правило, можно удалить одну из таких связей без потери какой-либо важной информации. Например, если объект «ученики» имеет прямую связь с другим объектом, называемым «учителя», но также имеет косвенные отношения с учителями через «предметы», нужно удалить связь между «учениками» и «учителями»
Так как единственный способ, которым ученикам назначают учителей — это предметы.
Виды баз данных и их структура, примеры
Выделяют несколько видов баз данных. Основными из них являются:
- Фактографическая, с краткой информацией об объектах какой-то системы, формат которой строго фиксирован.
- Документальная, включает документы разного вида, в том числе текстовые, графические, звуковые, мультимедийные.
- Распределенная, является базой данных с разными частями, которые хранятся на различных компьютерах, объединенных в сеть.
- Централизованная, представляет собой базу данных, местом хранения которой является один компьютер.
- Реляционная, имеет табличную организацию данных.
- Неструктурированная (NoSQL), является базой данных, в которой делается попытка решить проблемы масштабируемости и доступности с помощью атомарности и согласованности данных без четкой структуры.
Базы данных разных систем обладают неодинаковой структурой. Для ПЭВМ характерно использование реляционных баз данных с файлами в виде таблиц, в которых столбцы являются полями, а строки – записями. В базе данных находятся данные определенного множества объектов. Для каждой записи характерна информация по одному объекту. Такую базу определяют:
- имя файла;
- список полей;
- ширина полей.
В качестве примера можно привести школьную базу с данными «Ученик», «Класс», «Адрес». Также базой данных является расписание движения поездов или автобусов. В этом случае каждой строке соответствует запись с данными конкретного объекта. Возможные поля: номер рейса, маршрут, время отправления и прибытия. Классической базой данных является телефонный справочник.
Определение
Запрос к базе данных – предписание с указанием на данные, которые необходимы пользователю.
Примечание
В случае некоторых запросов требуется составление сложной программы. К примеру, для выполнения запроса к базе в виде автобусного расписания необходимо вычислить разницу в среднем интервале отправления транспорта из одного города во второй и из второго пункта в третий.
Существует три звена для создания приложения, с помощью которого можно просматривать и редактировать базы данных:
- набор данных;
- источник информации;
- визуальные компоненты управления.
В случае Access роль таких звеньев выполняют:
- Table.
- DataSource.
- DBGrid.
Приложения базы данных является нитью, которая связывает базу и пользователя:
БД => набор данных –=> источник данных => визуальные компоненты => пользователь
Набор данных:
- Table, в виде таблицы, навигационного доступа;
- Query, включая запрос, реляционный доступ.
Визуальными компонентами являются:
- Сетки DBGrid, DBCtrlGrid.
- Навигатор DBNavigator.
- Разные аналоги Lable, Edit.
- Компоненты подстановки.
Access характеризуется наличием следующих типов полей:
- текстовый, в виде текстовой строки с максимальной длиной до 255, заданной параметром «размер»;
- поле МЕМО, является текстом длиной до 65535 символов;
- числовой, в параметре «Размер поля» можно задать поле: байт, целое, действительное и другие;
- дата/время, необходимо для записи данных о времени;
- денежный, является специальным форматом для решения финансовых задач;
- счетчик, в виде автоинкрементного поля, который предназначен для ключевого поля, увеличивается на единицу после добавления новой записи и сохраняется в данное поле новой записи, что гарантирует разные значения для неодинаковых записей;
- логический, в виде «да или нет», «правда или ложь», «включен или выключен»;
- объект OLE, предназначен для хранения документов, картинок, звуков и другой информации, представляет собой частный случай BLOB, то есть полей (Binary Large Object), которые можно встретить в разных базах данных;
- гиперссылка, необходима для хранения ссылок на ресурсы в Интернете, характерна не для всех форматов баз данных, например, отсутствует в dBase и Paradox;
- подстановка.
Благодаря связи с обеспечением целостности таблиц осуществляется контроль удаления и модификации данных. С помощью монопольного доступа к базам данных в них производят фундаментальные изменения.
Подводим итоги проектирования
Проектирование БД — процесс небыстрый и достаточно трудоёмкий. Во время проектирования надо хорошо знать предметную область, учитывать все нюансы. Вся информация должна отображаться в виде таких элементов, как объекты, атрибуты, связи, причём проектирование успешно лишь тогда, когда всё сделано максимально рационально.
Вообще, взгляды на проектирование среди разработчиков могут различаться. Некоторые игнорируют теорию, руководствуясь лишь опытом и здравым смыслом. Другие во время проектирования отводят главную роль интуиции, считая проектирование искусством, которым владеют далеко не все. Как бы там ни было, знания никогда не бывают лишними.
Да, реляционная база данных — это не более чем хранилище, где хранятся данные. Однако от того, как грамотно вы его организуете, будет зависеть стабильность работы всего приложения, где используются эти самые данные.
В заключение, добавим, что умение проектировать базы вам никогда не помешает. А научиться всему этому вы сможете на нашем курсе «Реляционные СУБД». Ждём вас!