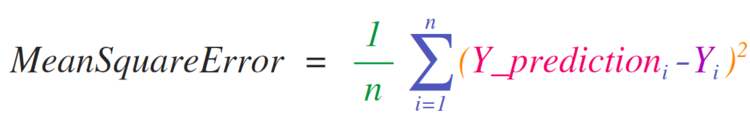Python sleep
Содержание:
Daemon потоки non-daemon
До этого момента примеры программ ожидали, пока все потоки не завершат свою работу. Иногда программы порождают такой поток, как демон. Он работает, не блокируя завершение основной программы.
Использование демона полезно, если не удается прервать поток или завершить его в середине работы, не потеряв и не повредив при этом данные.
Чтобы пометить поток как demon, вызовите метод setDaemon() с логическим аргументом. По умолчанию потоки не являются «демонами», поэтому передача в качестве аргумента значения True включает режим demon.
import threading
import time
import logging
logging.basicConfig(level=logging.DEBUG,
format='(%(threadName)-10s) %(message)s',
)
def daemon():
logging.debug('Starting')
time.sleep(2)
logging.debug('Exiting')
d = threading.Thread(name='daemon', target=daemon)
d.setDaemon(True)
def non_daemon():
logging.debug('Starting')
logging.debug('Exiting')
t = threading.Thread(name='non-daemon', target=non_daemon)
d.start()
t.start()
Обратите внимание, что в выводимых данных отсутствует сообщение «Exiting» от потока-демона. Все потоки, не являющиеся «демонами» (включая основной поток), завершают работу до того, как поток-демон выйдет из двухсекундного сна
$ python threading_daemon.py (daemon ) Starting (non-daemon) Starting (non-daemon) Exiting
Чтобы дождаться завершения работы потока-демона, используйте метод join().
import threading
import time
import logging
logging.basicConfig(level=logging.DEBUG,
format='(%(threadName)-10s) %(message)s',
)
def daemon():
logging.debug('Starting')
time.sleep(2)
logging.debug('Exiting')
d = threading.Thread(name='daemon', target=daemon)
d.setDaemon(True)
def non_daemon():
logging.debug('Starting')
logging.debug('Exiting')
t = threading.Thread(name='non-daemon', target=non_daemon)
d.start()
t.start()
d.join()
t.join()
Метод join() позволяет demon вывести сообщение «Exiting».
$ python threading_daemon_join.py (daemon ) Starting (non-daemon) Starting (non-daemon) Exiting (daemon ) Exiting
Также можно передать аргумент задержки (количество секунд, в течение которых поток будет неактивным).
import threading
import time
import logging
logging.basicConfig(level=logging.DEBUG,
format='(%(threadName)-10s) %(message)s',
)
def daemon():
logging.debug('Starting')
time.sleep(2)
logging.debug('Exiting')
d = threading.Thread(name='daemon', target=daemon)
d.setDaemon(True)
def non_daemon():
logging.debug('Starting')
logging.debug('Exiting')
t = threading.Thread(name='non-daemon', target=non_daemon)
d.start()
t.start()
d.join(1)
print 'd.isAlive()', d.isAlive()
t.join()
Истекшее время ожидания меньше, чем время, в течение которого поток-демон спит. Поэтому поток все еще «жив» после того, как метод join() продолжит свою работу.
$ python threading_daemon_join_timeout.py (daemon ) Starting (non-daemon) Starting (non-daemon) Exiting d.isAlive() True
Класс time.struct_time
Некоторые функции в модуле времени, такие как gmtime(), asctime() и т.д., либо принимают объект time.struct_time в качестве аргумента, либо возвращают его.
Вот пример объекта time.struct_time:
time.struct_time(tm_year=2018, tm_mon=12, tm_mday=27,
tm_hour=6, tm_min=35, tm_sec=17,
tm_wday=3, tm_yday=361, tm_isdst=0)
| Индекс | Атрибут | Значение |
|---|---|---|
| tm_year | 0000, …., 2018, …, 9999 | |
| 1 | tm_mon | 1, 2, …, 12 |
| 2 | tm_mday | 1, 2, …, 31 |
| 3 | tm_hour | 0, 1, …, 23 |
| 4 | tm_min | 0, 1, …, 59 |
| 5 | tm_sec | 0, 1, …, 61 |
| 6 | tm_wday | 0, 1, …, 6; Понедельник 0 |
| 7 | tm_yday | 1, 2, …, 366 |
| 8 | tm_isdst | 0, 1 или -1 |
Значения (элементы) объекта time.struct_time доступны как с помощью индексов, так и атрибутов.
Adding a Python sleep() Call With Threads
There are also times when you might want to add a Python call to a thread. Perhaps you’re running a migration script against a database with millions of records in production. You don’t want to cause any downtime, but you also don’t want to wait longer than necessary to finish the migration, so you decide to use threads.
Note: Threads are a method of doing concurrency in Python. You can run multiple threads at once to increase your application’s throughput. If you’re not familiar with threads in Python, then check out An Intro to Threading in Python.
To prevent customers from noticing any kind of slowdown, each thread needs to run for a short period and then sleep. There are two ways to do this:
- Use as before.
- Use from the module.
Let’s start by looking at .
Специфичные для потока данные
Некоторые ресурсы должны быть заблокированы, чтобы их могли использовать сразу несколько потоков. А другие должны быть защищены от просмотра в потоках, которые не «владеют» ими. Функция local() создает объект, способный скрывать значения для отдельных потоков.
import random
import threading
import logging
logging.basicConfig(level=logging.DEBUG,
format='(%(threadName)-10s) %(message)s',
)
def show_value(data):
try:
val = data.value
except AttributeError:
logging.debug('No value yet')
else:
logging.debug('value=%s', val)
def worker(data):
show_value(data)
data.value = random.randint(1, 100)
show_value(data)
local_data = threading.local()
show_value(local_data)
local_data.value = 1000
show_value(local_data)
for i in range(2):
t = threading.Thread(target=worker, args=(local_data,))
t.start()
Обратите внимание, что значение local_data.value не доступно ни для одного потока, пока не будет установлено
$ python threading_local.py (MainThread) No value yet (MainThread) value=1000 (Thread-1 ) No value yet (Thread-1 ) value=34 (Thread-2 ) No value yet (Thread-2 ) value=7
Чтобы все потоки начинались с одного и того же значения, используйте подкласс и установите атрибуты с помощью метода __init __() .
import random
import threading
import logging
logging.basicConfig(level=logging.DEBUG,
format='(%(threadName)-10s) %(message)s',
)
def show_value(data):
try:
val = data.value
except AttributeError:
logging.debug('No value yet')
else:
logging.debug('value=%s', val)
def worker(data):
show_value(data)
data.value = random.randint(1, 100)
show_value(data)
class MyLocal(threading.local):
def __init__(self, value):
logging.debug('Initializing %r', self)
self.value = value
local_data = MyLocal(1000)
show_value(local_data)
for i in range(2):
t = threading.Thread(target=worker, args=(local_data,))
t.start()
__init __() вызывается для каждого объекта (обратите внимание на значение id()) один раз в каждом потоке
$ python threading_local_defaults.py (MainThread) Initializing <__main__.MyLocal object at 0x100514390> (MainThread) value=1000 (Thread-1 ) Initializing <__main__.MyLocal object at 0x100514390> (Thread-1 ) value=1000 (Thread-2 ) Initializing <__main__.MyLocal object at 0x100514390> (Thread-1 ) value=81 (Thread-2 ) value=1000 (Thread-2 ) value=54
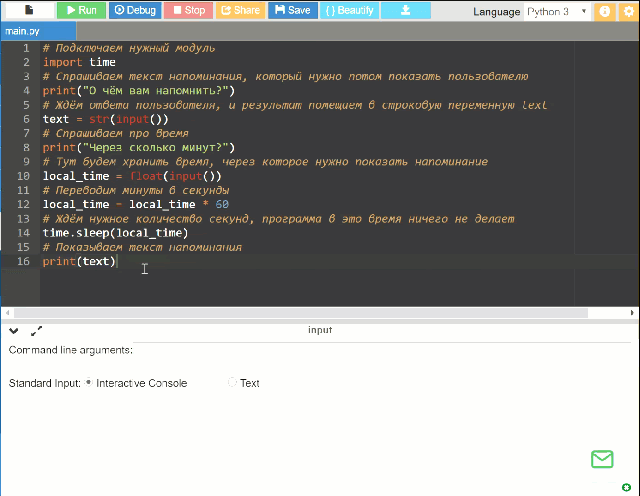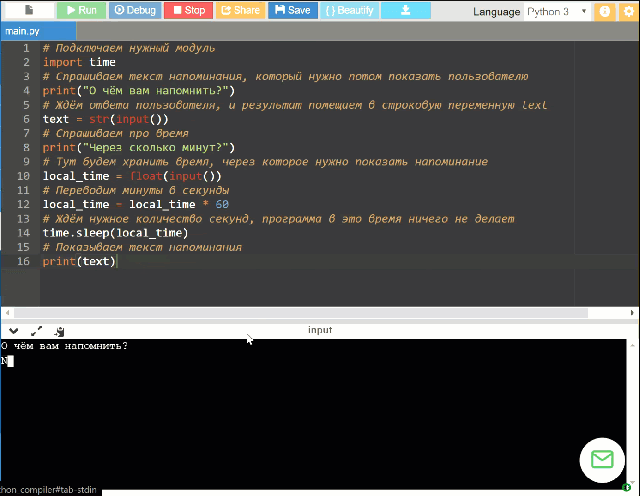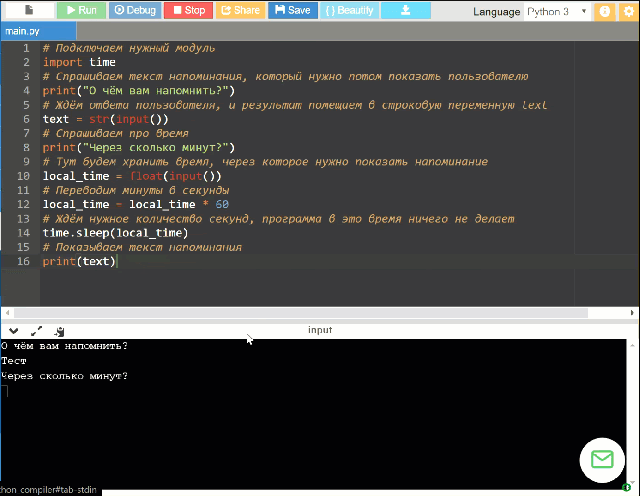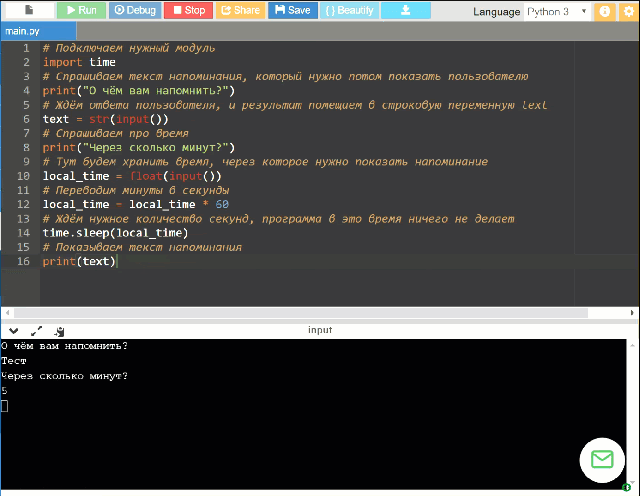
Вызов sleep() в потоках
Могут возникнуть ситуации, когда в Python требуется добавить вызов для потока. К примеру, запуск скрипта миграции для базы данных с миллионами записей
Здесь важно избежать простоя, а также не ждать дольше необходимого для завершения миграции, поэтому можно использовать потоки
На заметку: Потоки являются одним из методов использования конкурентности в Python. Можно запустить несколько потоков одновременно, чтобы увеличить производительность приложения.
Чтобы клиенты не замечали какого-либо замедления, каждый поток должен работать в течение короткого периода времени, а затем уходить в сон. Есть два способа сделать это:
- Использовать как ранее;
- Использовать из модуля ;
Начнем с разбора .
time.localtime()
Функция localtime() в Python принимает в качестве аргумента количество секунд, прошедших с начала эпохи, и возвращает struct_time по местному времени.
import time
result = time.localtime(1545925769)
print("result:", result)
print("\nyear:", result.tm_year)
print("tm_hour:", result.tm_hour)
Когда вы запустите программу, результат будет примерно таким:
result: time.struct_time(tm_year=2018, tm_mon=12, tm_mday=27, tm_hour=15, tm_min=49, tm_sec=29, tm_wday=3, tm_yday=361, tm_isdst=0) year: 2018 tm_hour: 15
Если в localtime() не передается аргумент или None, используется значение, возвращаемое функцией time().
The Cost of Sleep Deprivation
The irony of it all is that many of us are suffering from sleep deprivation so that we can work more, but the drop in performance ruins any potential benefits of working additional hours.
In the United States alone, studies have estimated that sleep deprivation is costing businesses over $100 billion each year in lost efficiency and performance.
As Gregory Belenky, Director of the Sleep and Performance Research Center at Washington State University, puts it: “Unless you’re doing work that doesn’t require much thought, you are trading time awake at the expense of performance.”
And this brings us to the important question: At what point does sleep debt start accumulating? When do performance declines start adding up? According to a wide range of studies, the tipping point is usually around the 7 or 7.5 hour mark. Generally speaking, experts agree that 95 percent of adults need to sleep 7 to 9 hours each night to function optimally. Most adults should be aiming for eight hours per night. Children, teenagers, and older adults typically need even more.
Here’s a useful analogy for why sleep is so important.
Важные заметки
Важно отметить, что при анализе временной сложности алгоритма с несколькими операциями нам необходимо описать алгоритм на основе наибольшей сложности среди всех операций. Например:
def my_function(data): first_element = data for value in data: print(value)for x in data: for y in data: print(x, y
Даже если операции в «my_function» не имеют смысла, мы видим, что он имеет несколько временных сложностей: O (1) + O (n) + O (n²). Таким образом, при увеличении размера входных данных узким местом этого алгоритма будет операция, которая принимает O (n²). Исходя из этого, мы можем описать временную сложность этого алгоритма как O (n²).
Sleep cycle
The sleep cycle is a natural internal system in humans. It is a combination of external conditions, such as light, personal behaviors, and lifestyle choices, and internal conditions, such as brain wave patterns and genetics.
A normal sleep cycle occurs in two distinct states: rapid eye movement (REM) sleep and nonrapid eye movement (NREM) sleep. The body moves between these states a few times a night.
The body cycles through these stages roughly every 90 minutes. Over more cycles, the NREM stages get lighter, and the REM stages get longer.
Ideally, the body will pass through four to five of these cycles each night. Waking up at the end of the cycle, when sleep is lightest, may be best to help the person wake feeling more rested and ready to start the day.
An alarm going off when a person is in one of the deeper stages of sleep may lead to grogginess or difficulty waking up.
Again, these stages vary from person to person, meaning that no single timing for sleep is right for everyone. Paying attention to how they feel in the morning and noting how many hours of sleep they got may help a person identify their sleep cycle and determine how much sleep they need.
Вызов sleep() с декораторами
В некоторых случаях нужно повторно запустить неудачно выполненную в первый раз функцию. Зачастую это происходит, когда требуется повторить загрузку файла ввиду ранней перегрузки сервера. Как правило, никто не хочет делать частые запросы на серверы, поэтому добавление в Python вызова между каждым запросом предпочтительно.
Другим возможным случаем использования является необходимость проверки состояния пользовательского интерфейса во время автоматического теста. В зависимости от компьютера, на котором запускается тест, пользовательский интерфейс может грузиться быстрее или медленнее обычного. Это может изменить отображаемое на экране во время проверки программой чего-то.
В данном случае можно указать программе, чтобы та погрузилась в сон на мгновенье и затем проверить все опять через несколько секунд. Это может означать разницу между прохождением или провалом теста.
Для добавления системного вызова в Python можно использовать декоратор в каждом из данных случаев. Разберем следующий пример:
Python
import time
import urllib.request
import urllib.error
def sleep(timeout, retry=3):
def the_real_decorator(function):
def wrapper(*args, **kwargs):
retries = 0
while retries < retry:
try:
value = function(*args, **kwargs)
if value is None:
return
except:
print(f’Сон на {timeout} секунд’)
time.sleep(timeout)
retries += 1
return wrapper
return the_real_decorator
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 |
importtime importurllib.request importurllib.error defsleep(timeout,retry=3) defthe_real_decorator(function) defwrapper(*args,**kwargs) retries= whileretries<retry try value=function(*args,**kwargs) ifvalue isNone return except print(f’Сон на {timeout} секунд’) time.sleep(timeout) retries+=1 returnwrapper returnthe_real_decorator |
является вашим декоратором. Он принимает значение и количество раз для повтора , что по умолчанию равняется 3. Внутри есть другая функция, , которая принимает декорируемую функцию.
В конечном итоге самая внутренняя функция принимает аргументы и ключевые слова, которые вы передаете декорируемой функции. Здесь все и происходит! Используется , чтобы повторить вызов функции. Если возникла ошибка, вызывается , увеличивается счетчик попыток и повторяется попытка запуска функции.
Теперь переписывается для использования нового декоратора:
Python
@sleep(3)
def uptime_bot(url):
try:
conn = urllib.request.urlopen(url)
except urllib.error.HTTPError as e:
# Отправка admin / log
print(f’HTTPError: {e.code} для {url}’)
# Повторное поднятие ошибки исключения для декоратора
raise urllib.error.HTTPError
except urllib.error.URLError as e:
# Отправка admin / log
print(f’URLError: {e.code} для {url}’)
# Повторное поднятие ошибки исключения для декоратора
raise urllib.error.URLError
else:
# Сайт поднят
print(f'{url} поднят’)
if __name__ == ‘__main__’:
url = ‘http://www.google.com/py’
uptime_bot(url)
|
2 |
defuptime_bot(url) try conn=urllib.request.urlopen(url) excepturllib.error.HTTPError ase # Отправка admin / log print(f’HTTPError: {e.code} для {url}’) # Повторное поднятие ошибки исключения для декоратора raiseurllib.error.HTTPError excepturllib.error.URLError ase # Отправка admin / log print(f’URLError: {e.code} для {url}’) # Повторное поднятие ошибки исключения для декоратора raiseurllib.error.URLError else # Сайт поднят print(f'{url} поднят’) if__name__==’__main__’ url=’http://www.google.com/py’ uptime_bot(url) |
Здесь вы декорируете с помощью в 3 секунды. Вы также удалили оригинальный цикл и старый вызов . Декоратор теперь позаботится об этом.
Другое изменение состоит в добавлении внутри блоков, отвечающих за обработку исключений. Это нужно для правильной работы декоратора. Можно также написать декоратор, чтобы он отвечал за ошибки, однако ввиду того, что исключения касаются только , может быть лучше сохранить декоратор в текущем состоянии. В таком случае он будет работать c более широким ассортиментом функций.
Декоратору можно добавить несколько улучшений. Если число попыток заканчивается, и он по-прежнему проваливается, тогда можно сделать так, чтобы он повторно вызвал последнюю ошибку. Декоратор подождет 3 секунды после последней неудачи, что не всегда нужно. Можете попробовать поэкспериментировать самостоятельно.
Нумерация потоков
Можно не сохранять дескрипторы всех потоков-демонов, чтобы убедиться в их завершении до выхода из основного процесса. enumerate() возвращает список активных экземпляров Thread. Список включает в себя текущий поток. Но присоединение к текущему потоку не разрешено (это приводит к ситуации взаимной блокировки), его необходимо пропустить.
import random
import threading
import time
import logging
logging.basicConfig(level=logging.DEBUG,
format='(%(threadName)-10s) %(message)s',
)
def worker():
"""thread worker function"""
t = threading.currentThread()
pause = random.randint(1,5)
logging.debug('sleeping %s', pause)
time.sleep(pause)
logging.debug('ending')
return
for i in range(3):
t = threading.Thread(target=worker)
t.setDaemon(True)
t.start()
main_thread = threading.currentThread()
for t in threading.enumerate():
if t is main_thread:
continue
logging.debug('joining %s', t.getName())
t.join()
Поскольку worker спит в течение случайного отрезка времени, выходные данные программы могут отличаться. Это должно выглядеть примерно так:
$ python threading_enumerate.py (Thread-1 ) sleeping 3 (Thread-2 ) sleeping 2 (Thread-3 ) sleeping 5 (MainThread) joining Thread-1 (Thread-2 ) ending (Thread-1 ) ending (MainThread) joining Thread-3 (Thread-3 ) ending (MainThread) joining Thread-2
Python time.sleep() Usage
This function is a part of the module hence we call it using the dot notation like time.sleep(). We must import the time module first.
import time
Now, to halt the execution of the program, we need to specify the number of seconds as an argument.
import time
num_seconds = 5
print('Going to sleep for', str(num_seconds), 'seconds')
time.sleep(num_seconds)
print('Woke up after', str(num_seconds), 'seconds')
Output
Going to sleep for 5 seconds Woke up after 5 seconds
If you try this out on your machine, your program will halt for 5 seconds between the two outputs, since it is sleeping for that time.
We can also specify the number of seconds as a floating-point number, so we can sleep for seconds (1 millisecond) or even seconds (1 microsecond).
This will make the delay as precise as possible, within the floating-point and clock precision limits.
import time
num_millis = 2
print('Going to sleep for', str(num_millis), 'milliseconds')
time.sleep(num_millis / 1000)
print('Woke up after', str(num_millis), 'milliseconds')
Output
Going to sleep for 2 milliseconds Woke up after 2 milliseconds
To measure the exact time of sleep, we can use the method to start a timer. The difference between the start value and the end value of the timer will be our execution time.
Let’s test out our actual sleeping time in the above program.
import time
num_millis = 2
print('Going to sleep for', str(num_millis), 'milliseconds')
# Start timer
start_time = time.time()
time.sleep(num_millis / 1000)
# End timer
end_time = time.time()
print('Woke up after', str(end_time - start_time), 'seconds')
Output
Going to sleep for 2 milliseconds Woke up after 0.0020711421966552734 seconds
Here, the time is not exactly 2 milliseconds, as you can see. It is about milliseconds, which is slightly greater than it.
This is due to some delays in allocating resources, process scheduling, etc from the Operating System, which may cause a slight delay.
The extent of this delay will differ since you don’t know the exact state of the Operating System at a particular instance of time.
Ограничение одновременного доступа к ресурсам
Как разрешить доступ к ресурсу нескольким worker одновременно, но при этом ограничить их количество. Например, пул соединений может поддерживать фиксированное число одновременных подключений, или сетевое приложение может поддерживать фиксированное количество одновременных загрузок. Semaphore является одним из способов управления соединениями.
import logging
import random
import threading
import time
logging.basicConfig(level=logging.DEBUG,
format='%(asctime)s (%(threadName)-2s) %(message)s',
)
class ActivePool(object):
def __init__(self):
super(ActivePool, self).__init__()
self.active = []
self.lock = threading.Lock()
def makeActive(self, name):
with self.lock:
self.active.append(name)
logging.debug('Running: %s', self.active)
def makeInactive(self, name):
with self.lock:
self.active.remove(name)
logging.debug('Running: %s', self.active)
def worker(s, pool):
logging.debug('Waiting to join the pool')
with s:
name = threading.currentThread().getName()
pool.makeActive(name)
time.sleep(0.1)
pool.makeInactive(name)
pool = ActivePool()
s = threading.Semaphore(2)
for i in range(4):
t = threading.Thread(target=worker, name=str(i), args=(s, pool))
t.start()
В этом примере класс ActivePool является удобным способом отслеживания того, какие потоки могут запускаться в данный момент. Реальный пул ресурсов будет выделять соединение для нового потока и восстанавливать значение, когда поток завершен. В данном случае он используется для хранения имен активных потоков, чтобы показать, что только пять из них работают одновременно.
$ python threading_semaphore.py 2013-02-21 06:37:53,629 (0 ) Waiting to join the pool 2013-02-21 06:37:53,629 (1 ) Waiting to join the pool 2013-02-21 06:37:53,629 (0 ) Running: 2013-02-21 06:37:53,629 (2 ) Waiting to join the pool 2013-02-21 06:37:53,630 (3 ) Waiting to join the pool 2013-02-21 06:37:53,630 (1 ) Running: 2013-02-21 06:37:53,730 (0 ) Running: 2013-02-21 06:37:53,731 (2 ) Running: 2013-02-21 06:37:53,731 (1 ) Running: 2013-02-21 06:37:53,732 (3 ) Running: 2013-02-21 06:37:53,831 (2 ) Running: 2013-02-21 06:37:53,833 (3 ) Running: []
Examples¶
It is possible to provide a setup statement that is executed only once at the beginning:
$ python -m timeit -s 'text = "sample string"; char = "g"' 'char in text' 5000000 loops, best of 5: 0.0877 usec per loop $ python -m timeit -s 'text = "sample string"; char = "g"' 'text.find(char)' 1000000 loops, best of 5: 0.342 usec per loop
>>> import timeit
>>> timeit.timeit('char in text', setup='text = "sample string"; char = "g"')
0.41440500499993504
>>> timeit.timeit('text.find(char)', setup='text = "sample string"; char = "g"')
1.7246671520006203
The same can be done using the class and its methods:
>>> import timeit
>>> t = timeit.Timer('char in text', setup='text = "sample string"; char = "g"')
>>> t.timeit()
0.3955516149999312
>>> t.repeat()
The following examples show how to time expressions that contain multiple lines.
Here we compare the cost of using vs. /
to test for missing and present object attributes:
$ python -m timeit 'try:' ' str.__bool__' 'except AttributeError:' ' pass' 20000 loops, best of 5: 15.7 usec per loop $ python -m timeit 'if hasattr(str, "__bool__"): pass' 50000 loops, best of 5: 4.26 usec per loop $ python -m timeit 'try:' ' int.__bool__' 'except AttributeError:' ' pass' 200000 loops, best of 5: 1.43 usec per loop $ python -m timeit 'if hasattr(int, "__bool__"): pass' 100000 loops, best of 5: 2.23 usec per loop
>>> import timeit >>> # attribute is missing >>> s = """\ ... try: ... str.__bool__ ... except AttributeError: ... pass ... """ >>> timeit.timeit(stmt=s, number=100000) 0.9138244460009446 >>> s = "if hasattr(str, '__bool__'): pass" >>> timeit.timeit(stmt=s, number=100000) 0.5829014980008651 >>> >>> # attribute is present >>> s = """\ ... try: ... int.__bool__ ... except AttributeError: ... pass ... """ >>> timeit.timeit(stmt=s, number=100000) 0.04215312199994514 >>> s = "if hasattr(int, '__bool__'): pass" >>> timeit.timeit(stmt=s, number=100000) 0.08588060699912603
To give the module access to functions you define, you can pass a
setup parameter which contains an import statement:
def test():
"""Stupid test function"""
L = i for i in range(100)]
if __name__ == '__main__'
import timeit
print(timeit.timeit("test()", setup="from __main__ import test"))
Another option is to pass to the globals parameter, which will cause the code
to be executed within your current global namespace. This can be more convenient
than individually specifying imports:
def f(x):
return x**2
def g(x):
return x**4
def h(x):
return x**8
import timeit
print(timeit.timeit('', globals=globals()))
Использование Python time.sleep() в потоке
Это полезная функция в контексте многопоточности, так как нескольким потокам может потребоваться дождаться освобождения определенного ресурса.
Приведенный ниже фрагмент показывает, как мы можем заставить несколько потоков ждать и печатать выходные данные, используя Python .
import time
from threading import Thread
class Worker(Thread):
# Entry point after thread.start() is invoked
def run(self):
for i in range(4):
print('Worker Thread', i)
time.sleep(i + 1)
class Waiter(Thread):
def run(self):
for i in range(10, 15):
print('Waiter thread', i)
time.sleep(i - 9)
print('Starting Worker Thread....')
Worker().start()
print('Starting Waiter Thread....')
Waiter().start()
print('Main thread finished!')
Выход
Starting Worker Thread.... Worker Thread 0 Starting Waiter Thread.... Waiter thread 10 Main thread finished! Worker Thread 1 Waiter thread 11 Worker Thread 2 Waiter thread 12 Worker Thread 3 Waiter thread 13 Waiter thread 14
Здесь выполнение основного потока (программы) не зависит от выполнения двух потоков. Итак, наша основная программа закончилась первой, прежде чем за ней последовали потоки и .
Что такое поток
В упрощённом виде потоки — это параллельно выполняемые задачи. По умолчанию используется один поток — это значит, что программа делает всё по очереди, линейно, без возможности делать несколько дел одновременно.
Но если мы сделаем в программе два потока задач, то они будут работать параллельно и независимо друг от друга. Одному потоку не нужно будет становиться на паузу, когда в другом что-то происходит.
Важно понимать, что поток — это высокоуровневое понятие из области программирования. На уровне вашего «железа» эти потоки всё ещё могут обсчитываться последовательно. Но благодаря тому, что они будут обсчитываться быстро, вам может показаться, что они работают параллельно.