Как составить семантическое ядро без помощи специалиста
Содержание:
Анализ конкуренции запросов для информационных сайтов
Собрав запросы и почистив их теперь нам надо проверить их конкуренцию, чтобы понимать в дальнейшем — какими запросами надо заниматься в первую очередь.
Конкуренция по количеству документов, title, главных страниц
Это все легко снимается через KEI в KeyCollector.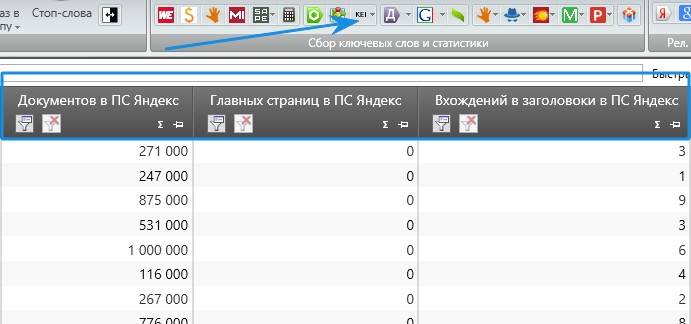 Получаем данные по каждому запросу, сколько документов найдено в поисковой системе, в нашем пример в Яндексе. Сколько главных страниц в выдаче по этому запросу и вхождений запроса в заголовок.
Получаем данные по каждому запросу, сколько документов найдено в поисковой системе, в нашем пример в Яндексе. Сколько главных страниц в выдаче по этому запросу и вхождений запроса в заголовок.
В интернете можно встретить различные формулы расчета этих показателей, даже вроде в свежем установленном KeyCollector по стандарту встроена какая-то формула расчета KEI. Но я им не следую, потому что надо понимать что каждый из этих факторов имеет разный вес. Например, самый главный, это наличие главных страниц в выдаче, потом уже заголовки и количество документов
Навряд ли эту важность факторов, как то можно учесть в формуле и если все-таки можно то без математика не обойтись, но тогда уже эта формула не сможет вписаться в возможности KeyCollector
Конкуренция по биржам ссылок
Здесь уже интереснее. У каждой биржи свои алгоритмы расчета конкуренции и можно предположить, что они учитывают не только наличие главных страниц в выдаче, но и возраст страниц, ссылочную массу и другие параметры. В основном эти биржи конечно же рассчитаны на коммерческие запросы, но все равно более менее какие то выводы можно сделать и по информационным запросам.
Собираем данные по биржам и выводим средние показатели и уже ориентируемся по ним. Я обычно собираю по 2-3 биржам. Главное чтобы все запросы были собраны по одним и тем же биржам и выведено среднее число только по ним. А не так, что какие то запросы собрали одними биржами, а другие другими и вывели среднее.
Я обычно собираю по 2-3 биржам. Главное чтобы все запросы были собраны по одним и тем же биржам и выведено среднее число только по ним. А не так, что какие то запросы собрали одними биржами, а другие другими и вывели среднее.
Для более наглядного вида можно применить формулу KEI, которая покажет стоимость одного посетителя исходя из параметров бирж:
KEI = AverageBudget / ( AverageTraffic +0.01)
Средний бюджет по биржам делить на средний прогноз трафика по биржам, получаем стоимость одного посетителя исходя из данных бирж.
Конкуренция по мутаген
Сервис мутаген создан специально для анализа конкуренции информационных запросов. Работает с 2011 года, принцип алгоритма не разглашается, но вполне себе годно рассчитывает. Конкуренция рассчитывается по 25 баллам. Чем больше балл, тем больше конкуренция: 1-7 низкая конкуренция, 8-15 средняя, 16 и выше, высокая. Сервис платный, но в день можно чекать 10 запросов бесплатно. Тут сразу показываются просмотры по вордстату, ключи хвосты, клики в яндекс директ. В KeyCollector есть возможность массового сбора по мутаген.
В KeyCollector есть возможность массового сбора по мутаген.
Выводы: Если у вас бюджет ограничен то вы можете использовать первые два способа проверки конкуренции в совокупности, если готовы тратиться на анализ, то можно использовать только Мутаген или Оверлид.
ДОБРО ПОЖАЛОВАТЬ В МИР SEO
Понимание того, что такое поисковая оптимизация и как вы можете использовать ее в своих интересах. Это то, что отделит вас от конкурентов и выведет ваш сайт на новый уровень. Чаще всего пользователи либо полностью ошеломлены концепцией SEO, либо просто считают, что это обман, который не стоит денег.
Оказывается, SEO не волшебство и не уловка. Это серия проверенных и достоверных методов, которые тщательно и спланировано используются на веб-сайте для последовательного увеличения объема трафика. Неизбежным побочным эффектом увеличения трафика на сайт является повышение рейтинга в поисковых системах.
Мы хотим прояснить одну вещь: все, о чем мы будем писать в этой серии, было не только проверено несколькими другими сайтами веб-разработки, но также использовалось и реализовывалось ими. Это практический совет, используемый реальными людьми на самом деле компании.
Это наша первая статья из серии, основная цель которой – научить вас всем тонкостям поисковой оптимизации. Мы советуем вам внимательно прочесть статьи этой серии, поскольку в них содержатся полезные советы и рекомендации, которые, если их точно соблюдать, принесут вам огромный успех в онлайн-маркетинге. Эта первая статья посвящена важнейшему аспекту SEO: семантическое ядро как правильно составить.
Как группировать запросы
Чтобы понять, как распределять ключевые слова по отдельным страницам, нужно сгруппировать запросы. Для этого надо создать семантические кластеры.
Чаще всего, ключевые слова из кластеров первого и второго уровней определяются еще на этапе мозгового штурма. Для этого просто нужно хорошо разбираться в своем продукте или ориентироваться на структуру сайтов-конкурентов. Семантика остальных подуровней определяется на этапе детального составления семантического ядра и его кластеризации
Еще одно важное условие — каждая группа запросов последнего уровня должна соответствовать одной потребности пользователя. Например, покупка конкретного вида детского белья
Используем Словоёб с уже известной нам функцией быстрого фильтра. С его помощью можно легко отсортировать фразы по категориям для дальнейшего внедрения на посадочных страницах.
1. Введите в поле быстрого фильтра базовое ключевое слово, которое может станет названием для категории/подкатегории/посадочной страницы (например, бренд детского постельного белья «Непоседа») и нажмите Enter.
2. Выделите нужные фразы и скопируйте их.
3. Удалите отмеченные строки правой кнопкой мыши.
4. Создайте в правом меню новую группу (например, с названием «Непоседы»).
5. Для добавления только что выбранных фраз в эту группу, перейдите во вкладку «Данные» — «Добавить фразы».
6. Вернитесь к прежнему списку нажатием клавиши Enter в поле поиска быстрого фильтра.
7. Повторите эту процедуру с другими запросами. Ключевые фразы автоматически выстроятся в алфавитном порядке, благодаря чему можно легко удалить лишние слова или выделить похожие фразы в отдельную группу.
Группировка вручную требует много времени (особенно в том случае, если семантика достаточно широкая). Для автоматизации этого процесса можно использовать платные Key Collector, Rush-Analytics, Just-Magic, или бесплатный скрипт Devaka.ru. Часто приходится объединять некоторые группы запросов. Например, такие:
Согласитесь, создавать две отдельные категории под фразы «красивое белье» и «стильное белье» неразумно 🙂 Для понимания важности фраз для каждой категории/посадочной страницы, скопируйте их в Планировщик ключевых слов Google в раздел «Получение статистики запросов и трендов»:
Так вы проверяете популярность (частотность) поискового запроса. В целом все поисковые запросы делятся на:
- ВЧ-запросы (высокочастотные).
- СЧ-запросы (среднечастотные).
- НЧ-запросы (низкочастотные).
- Микро НЧ-запросы.
При этом нет точных цифр, по которым можно с уверенностью сказать, что запрос принадлежит к определенной группе. Все зависит от тематики сайта. В одних тематиках фраза с частотностью 1000 запросов в месяц может быть низкочастотной (фильмы, музыка), в других — 200 запросов уже может быть признаком высокочастотной фразы (финансовая тематика). Соотношение этих групп: Наиболее высокочастотные запросы впоследствии вписывайте в метатеги. А под низкочастотные оптимизируйте страницы сайта. Как правило, они очень низкоконкурентны, и достаточно провести качественную работу с текстами, чтобы вывести соответствующие страницы в ТОП.
Читайте, как привлечь целевой трафик на сайт с помощью формирования максимально широкого семантического ядра.
После всех этих манипуляций вы получите подробную структуру сайта, состоящую из ключевых фраз для:
Облако запросов — расширение семантического ядра
Облако запросов — это все ключевые слова, полученные парсингом поисковых подсказок и Яндекс Wordstat по маркерным запросам.
По нашему опыту эффективнее всего получать расширения запросов из поисковых подсказок Яндекса + поисковые подсказки Google и левой колонки Яндекс Wordstat.
Почему?
Не потому, что в Rush Analytics есть парсинг только Яндекс Wordstat и поисковых подсказок 🙂
Потому, что эти источники семантики: а) Обладают максимальной полнотой б) Подсказки изначально трастовый источник семантики т.к. сам Яндекс исправляет орфографию и добавляет в подсказки ТОЛЬКО реальные запросы пользователей. Что нам и нужно.
Часто задаваемые вопросы по сбору облака запросов
Q: У меня есть база Пастухова, есть аккаунт в SeoPult и Sape — там тоже есть ключевые слова — чем они плохи?
A: Если говорить о готовых базах данных (например, База Пастухова), то плохи они вот чем а) непонятно откуда взяты эти запросы — реальные ли это запросы или же это «кривые» запросы горе-оптимизаторов б) Большинство запросов в готовых базах данных банального сгенерированы или уже потеряли актуальность.
SeoPult и Sape можно использовать, чтобы прикинуть свои маркеры — иногда там можно найти интересные ключевые слова
Таким образом, проще собрать свежие и актуальные ключевые слова для своей тематики, чем «копаться в мусоре».
Поверьте — все пригодные запросы этих баз данных есть в Яндекс Wordstat и поисковых подсказках. Мы проверяли.
Итак — у нас есть 2 потенциальных источника семантики — Яндекс Wordstat и поисковые подсказки.
Формируем финальное облако запросов:
Финальное облако запросов будет включать в себя:
а) Ключевые слова, собранные с левой колонки Wordstat
б) Ключевые слова, полученные из поисковых подсказок
Т.е. вам нужно объединить 2 массива данных (2 файла), которые мы получили из поисковых подсказок и из Яндекс Wordstat.Не забудьте проверить частотность собранных подсказок по Wordstat — это пригодится вам в дальнейшей работе.
Здесь вы должны иметь от нескольких тысяч до нескольких сотен тысяч целевых ключевых слов + знать их частотность по Wordstat. Уже на данном этапе понятно, что собранная база ключевых слов в 10-50 раз превышает то, что имеют конкуренты 🙂
2) Как расширить СЯ: три варианта
Первый этап относительно простой. Хотя и потребует от вас внимательности. Но второй – активной мозговой деятельности. Ведь каждая отдельно выбранная фраза – это основа будущей группы поисковых запросов, по которым вы будете продвигаться.
Чтобы собрать такую группу, необходимо использовать:
- синонимы;
- перефразирования.
Чтобы не «загрузнуть» в этом этапе, воспользуйтесь специальными приложениями или сервисами. Как это сделать – подробно описано ниже.
Как расширить СЯ с помощью планировщика ключевых слов Google
Переходим в тематический раздел (он называется Планировщик ключевых фраз) и набирает те фразы, которые наиболее точно характеризуются интересующую вас группу запросов. Прочие параметры не трогаете и кликаете по кнопке «Получить … ».
После этого просто скачиваете полученные результаты.
Как расширить СЯ с помощью Serpstat (ex. Prodvigator)
Вы также можете использовать другой подобный сервис, с помощью которого проводит анализ конкурентом. Ведь именно конкуренты представляют собой оптимальное место, где можно получить требуемые вам ключевые слова.
Сервис Serpstat (ex. Prodvigator) позволяет точно определить, по каким именно ключевым запросам ваши конкуренты выбились в лидеры поисковых систем. Хотя есть и другие сервисы – каким именно пользоваться, решайте сами.
Для того чтобы подобрать поисковые запросы, вам нужно:
- ввести один запрос;
- указать интересующий вас регион продвижения;
- кликнуть по кнопке «Поиск»;
- а когда он завершится – выбрать опцию «Поисковые запросы».
После этого кликните по кнопке «Экспорт таблицы».
Как составить семантическое ядро: как расширить СЯ с помощью Key Collector/Словоёб
У вас большой магазин с огромным количеством товаров? В такой ситуации вам понадобится сервис Key Collector.
Хотя если вы только начинаете познавать науку подбора ключевых слов и формирования семантического ядра, рекомендуем обратить внимание на другой сервис – с неблагозвучным названием Словоеб. Его преимущество состоит в том, что он полностью бесплатный
Скачайте приложение, перейдите в настройки Яндекс.Директ и введите логин/пароль от почтового ящика Яндекса.
После этого:
- откройте новый проект;
- кликните по вкладке Данные;
- там нажмите на опцию Добавить фразы;
- укажите интересующий вас регион продвижения;
- введите запросы, которые были сформированы ранее.
Рекомендуем под каждую отдельную группу ключевых слов создавать новый проект. (И под каждый домен тоже).
После этого приступайте к сбору СЯ из Wordstat.Yandex. Для этого:
- перейдите в раздел «Сбор данных»;
- затем – нужно выбрать раздел «Пакетный сбор слов из левой колонки»;
- перед вами на экране появится новое окно;
- в нем – сделайте так, как указано на скрине ниже;
Отметим, что Key Collector отличный инструмент для объемных, крупных проектов и с его помощью легко организовать сбор статистических данных по сервисам, анализирующим «работу» сайтов-конкурентов. Например, к таковым сервисам относятся следующие: SEMrush, SpyWords, Serpstat (ex. Prodvigator) и многие другие.
Маркерные запросы
Маркерные запросы — это запросы, которые наиболее точно описывают суть страницы. Такие запросы часто имею самую высокую частотность по Wordstat, от них происходит «хвост» запросов, например, такие как «купить», «отзывы» и т.д. Очень частно маркерным запросом выступает заголовок h1 на странице.
Производим мозговой штурм и собираем маркерные запросы по всем основным направлениям на нашем сайте. Например, мы продаем заточные, фрезерные и токарные станки, это разделы, сначала пишем их, после вписываем категории, которые входят в каждый из разделов, далее указываем подкатегории входящие в категории.
СЯ и поисковые алгоритмы: как это работает в 2021 году
Поисковики совершенствуют свои алгоритмы ранжирования, чтобы пользователи могли получать релевантную информацию. Они вводят элементы машинного обучения, позволяющие оценивать не отдельные слова, а целые смыслы. Поэтому наличие ключевых слов на веб-странице не является гарантией того, что поисковики её «заметят». Но в новых стратегиях ранжирования есть свои плюсы. В 2021 году не обязательно, чтобы ключевики полностью совпадали с поисковыми запросами. Алгоритмы учитывают синонимы и слова, которые соответствуют тематике.
- Google BERT – алгоритм с искусственным интеллектом, который работает с целыми предложениями и запросами с длинными хвостами;
- Google SMITH – появился в 2021 году, и будет работать эффективнее BERT. Если последний анализирует отдельные предложения и фразы, то новый алгоритм способен оценить смысл всего текста;
- Яндекс YATI – отечественный «трансформер» с машинным обучением способен оценить релевантность контента при отсутствии в нём конкретных поисковых запросов.
В 2021 году стала использоваться методика ранжирования пассажей – Google Passage Ranking. Поисковые роботы делят тексты на смысловые фрагменты (пассажи), а затем определяют их релевантность запросу. По интернет-запросам пользователей показываются материалы, где подсвечена только часть, в которой находится ответ на поставленный вопрос.
Что такое кластеризация семантического ядра
Кластеризацией семантического ядра называется распределение общего числа запросов на группы в соответствии с определёнными принципами. Представьте огромный склад с бытовой химией, где находится абсолютно всё: средства для ухода за телом, принадлежности для уборки, стирки, так же химические средства по борьбе с различными насекомыми.
Чтобы ориентироваться во всём этом и оперативно находится нужный товар, необходимо их рассортировать по назначению, ценовой категории, объёму, качеству и т.д. Так же и семантикой. Когда происходит сбор ключевых запросов, туда входит всё: коммерческие, информационные запросы, так же фразы, отдельные слова, и даже запросы с ошибками, в общем всё, чем когда-либо интересовался пользователь.

Человеческий мозг постоянно генерирует всё новые и новые запросы и фразы и в связи с этим семантическое ядро постоянно пополняется новыми «ключами» и сортируется в соответствии со спецификой. Пользователь, сам того не подозревая, когда ищет в интернете запрос информационного характера, может стать потенциальным клиентом, если правильно выстроить структуру запроса и сделать посадочные страницы, так же интересный сайт.
Стоит ли заказывать СЯ у специалистов?
По большому счету специалисты по составлению семантического ядра сделают вам только шаги 1 – 3 из нашей схемы. Иногда, за большую дополнительную плату, сделают и шаги 4-5 – (сбор хвостов и проверку конкурентности запросов).
После этого они выдадут вам несколько тысяч ключевых запросов, с которыми вам дальше надо будет работать.
И вопрос тут в том, собираетесь ли вы писать статьи самостоятельно, или наймете для этого копирайтеров. Если вы хотите делать упор на качество, а не на количество – то надо писать самим. Но тогда вам будет недостаточно просто получить список ключей. Вам надо будет выбрать те темы, в которых вы разбираетесь достаточно хорошо, чтобы написать качественную статью.
И вот тут встает вопрос – а зачем тогда собственно нужны специалисты по СЯ? Согласитесь, распарсить базовый ключ и собрать точные частотности (шаги #1-3) – это совсем не сложно. У вас уйдет на это буквально полчаса времени.
Самое сложное – это именно выбрать ВЧ запросы, у которых низкая конкуренция. А теперь еще, как выясняется, надо ВЧ-НК, на которые вы можете написать хорошую статью. Вот именно это займет у вас 99% времени работы над семантическим ядром. И этого вам не сделает ни один специалист. Ну и стОит ли тратиться на заказ таких услуг?
Когда услуги специалистов по СЯ полезны
Другое дело, если вы изначально планируете привлекать копирайтеров. Тогда вам необязательно разбираться в теме запроса. Копирайтеры ваши тоже не будут в ней разбираться. Они просто возьмут несколько статей по этой теме, и скомпилируют из них “свой” текст.
Такие статьи будут пустыми, убогими, почти бесполезными. Но их будет много. Самостоятельно вы сможете писать максимум 2-3 качественные статьи в неделю. А армия копирайтеров обеспечит вам 2-3 говнотекста в день. При этом они будут оптимизированы под запросы, а значит будут привлекать какой-то трафик.
В этом случае – да, спокойно нанимайте специалистов по СЯ. Пусть они вам еще и ТЗ для копирайтеров составят заодно. Но сами понимаете, это тоже будет стоить отдельных денег.
Группировка семантического ядра для информационного сайта
При группировке семантического ядра я руководствуюсь здравой логикой, сравнивая её с выдачей.
Для информационных сайтов я не вижу смысла прибегать к кластеризации и четко следовать её требованиям. Поисковая система постоянно обучается и совершенствуется. Сегодня она показывает, что запросы “черный хлеб” и “ржаной хлеб” это разные продукты, а завтра покажет правильно, что это одно и тоже.
Итак, в KeyCollector у нас есть чистенький список запросов и мы собрали по нему данные из поисковой выдачи. Чтобы облегчить работу, группируем ядро средствами KeyCollector.
Заходим в анализ групп, ставим по поисковой выдаче Яндекс, сила 2. Обновляем группировку и экспортируем результаты в Excel.Таким способом у нас получилась группировка исходя из данных поисковой системы Яндекс. Но, как я писал уже выше, что надо следовать преимущественно логике и свои предположения проверять в поисковой системе, поэтому в некоторых группах могут быть запросы, которые вообще никак к ней не относятся. Их надо все пересмотреть и доработать.
Чтобы легче было дорабатывать, лучше всего оставить несколько столбцов только с нужными данными. Обычно я оставляю: базовую частотность, точную, KEI по полноте охвата, конкуренцию.
Покажу группировку на примере, чтобы было наглядно. Например, мы создаем сайт посвященный рецептам блинов. Мы увидели, что есть множество запросов связанные с молоком. Решаем, что будем делать отдельную рубрику “Рецепты блинов на молоке”. На примере этой рубрики и рассмотрим группировку.
Смотрим первую группу:Видим, что в группу “простого рецепта” попал общий запрос “тесто для блинов на молоке рецепт” – этим запросом человек не обязательно хочет найти простой рецепт. По логике, лучше всего этот запрос перенести в общую группу, которая будет вести на категорию со всеми рецептами блинов на молоке.
Но так же следует и глянуть выдачу в яндексе, что там вообще находится. Смотрим и видим, что действительно в выдаче по этому запросу есть пара страниц, которые ведут не на один рецепт, а на множество. Так же видим, что в выдаче большинство страниц ведут на один рецепт, при этом на рецепты тонких блинов. Но это же тупо, человек не обязательно хочет тонкие блины. Если бы он хотел тонкие блины, то он ввёл это в запрос. А у нас общий запрос, мы должны показать ему общую страницу, а он уже на ней должен определиться какие блины он хочет на молоке – с простым рецептом или тонкие блины или в дырочку или еще какие-то. В общем я мыслю так.
Переносим лишний запрос в другую группу, а точнее создаем выше новую “Рубрика рецепты блинов на молоке” отмечаем её другим цветом, потому что это рубрика, а в неё уже будут входить рецепты в нашем случае “простой рецепт блинов на молоке”. Тем самым у нас создается структура внутри семантики.
Все данные по группе суммируем. Бюджет можно выводить средним числом, так как это взаимодополняемые запросы, вы все их продвигаете на одной странице, а не по отдельности.
KEI1 (полнота охвата) выводим по уже известной нам формуле:
/*100
Получается вот такая красота:Данные по «рубрике рецепты блинов на молоке» еще не суммируем, потому что скорее всего туда добавятся еще запросы. Но и не исключено, что в “простой рецепт блинов на молоке” тоже еще добавятся запросы.
К тому же тут еще и затесался запрос с “тонкие блины”. Его тоже отдельно, он будет страницей к рубрике “рецепт блинов на молоке и воде”
И таким вот способом перерабатываем все ядро, в итоге получается вот так:Красным шрифтом помечены дополнительные фразы, которые имеют приставки фото, видео. Для нас это не совсем актуальные фразы. Эти фразы конкурируют с сервисами поисковых систем и трафику по ним очень мало. Но эти фразы подходят по нашему смыслу, поэтому мы их добавляем в группу.
Каждая группа помечена своим цветом. Цвет является структурой сайта, то есть уровнем вложенности страницы.
Например, если бы у нас был запрос “простой рецепт блинов на скисшем молоке”. То он бы уже шёл, как подгруппа к группе “блины на скисшем молоке” и естественно был бы выделен другим цветом. Выглядело бы это вот так:Думаю, идея с цветом понятна. Вот так создается семантика и удобная, понятная структура сайта, где все логично и имеет свой уровень вложенности.
Новые или измененные рубрики добавляем в нашу структуру в xmind.
В общем, чтобы нормально разгруппировать ядро необходимо мыслить логически, вставать на место посетителя, отвечать на вопрос – что он хочет увидеть, введя этот запрос? А также смотреть выдачу по этому запросу и принимать решение, как поступить наилучшим образом.
Этапы работы с семантическим ядром
Теперь когда мы знаем, что такое семядро и для чего оно нужно, а также знакомы с основными классификациями запросов, давайте вкратце разберём основные этапы работы с ядром.
Сбор семантики
Подробные способы сбора семантики будут даны в части «», здесь же мы остановимся на основных моментах.
На этом этапе вы должны найти и выписать общие запросы (их ещё называют маркерными), которые характеризуют деятельность вашего бизнеса: как общие направления, так и отдельные услуги и товары.
Например, вы продаёте мотоциклы определённой компании. Вашими маркерными запросами могут являться «мотоциклы», «мотоциклы + бренд» , «как выбрать мотоцикл», «запчасти для мотоцикла + бренд», «как ухаживать за мотоциклом», «классические/спортивные/круизёры и другие типы мотоциклов», «ремонт мотоциклов + бренд» и т.д. То есть в зависимости от оказываемых услуг или имеющихся товаров выбираются соответствующие маркеры.
После определения маркерных запросов проверяйте собранные ключевые слова в основных сервисах статистики запросов: Яндекс.Вордстат или Google Ads Планировщик ключевых слов. В них вы найдёте как частотность запросов, так и варианты других ключевых слов по вашей тематике. Собирайте всё, что как-то связано с вашим бизнесом.
Принципиальная разница между обозначенными сервисами заключается в следующем:
- Статистика в каждом актуальна только для родной поисковой системы. То есть если запрос «юридические услуги» смотреть в Вордстате, то показов будет более 100 000 именно в Яндекс. В Планировщике ключевых слов значения соответственно будут отличаться в Google.
- Плюс Вордстата в том, что он показывает точное значение показов запроса. Если у вас новый аккаунт в Google Ads, вместо точных значений запроса вы получите диапазоны типа 10–100, 100–1000 и т.д.
- Плюс Планировщика ключевых слов в том, что он даёт множество вариантов ключей сразу, чтобы учесть все варианты запросов для вашего сайта в продвижении и рекламе.
Если денег на платные инструменты нет, советуем использовать сразу 2 сервиса при сборе семантики. Но всё же рекомендуем купить Key Collector. Его основная задача — это автоматический сбор (парсинг) ключевых слов не только с Вордстата и Планировщика, но и с других сервисов и баз. Это не реклама данного инструмента, но уточним, что, кроме парсинга, сервис удобен для чистки и кластеризации ядра. Для многих SEO-специалистов Key Collector как швейцарский нож.
Интерфейс KeyCollector
Очистка
Когда все варианты запросов пользователей собраны в одной таблице, наступает время чистки от лишнего.
Лишними являются запросы, которые:
- слишком общие,
- не относятся к деятельности вашего сайта,
- не подходят по географии,
- включают в себя неактуальные цифры и даты,
- имеют брендовые составляющие конкурентов,
- состоят из 8 слов и более,
- затруднительно использовать на одной странице.
В качестве примера приведём подобранные ключи для одной из компаний, которая занимается продажей электрических каминов в Санкт-Петербурге:
Кластеризация и выбор страниц
Кластеризация — это группировка запросов по общности их смысловых значений в иерархическом порядке. То есть в одном кластере, или группе, должны быть запросы, описывающие одну сущность в глазах пользователя и поисковой системы. Делается это либо вручную, либо с помощью специальных сервисов.
Вернёмся к нашим каминам и возьмём следующие запросы:
- камин электрический с эффектом пламени;
- камины электрические с эффектом живого пламени;
- камины электрические фото;
- купить камин электрический;
- камин электрический купить в спб;
- угловой камин электрический;
- угловые камины электрические купить.
Первые два запроса можно объединить в один кластер и продвигать на одной странице. 3-й предполагает галерею или каталог, 4 и 5-й маркерные и достаточно общие, поэтому для них подойдёт главная страница или каталог. 6 и 7-й описывают категорию электрокаминов и под них стоит создать отдельную страницу на сайте.
Это пример ручной кластеризации, но мы указали, что запросы должны описывать одну сущность и в глазах пользователя, и поисковика. И вот тут начинаются проблемы, потому что часто можно столкнуться с тем, что схожие на первый взгляд запросы формируют разную поисковую выдачу. Чтобы избежать таких ошибок, используются специальные сервисы кластеризации, которые сравнивают выдачу и группируют кластеры.
Мониторинг
Важно не просто собрать ключевые слова и использовать их в создании контента для сайта, но и отслеживать рост позиций и трафика по этим запросам. О том, как это делать и какие сервисы можно использовать, читайте в нашей статье про проверку позиций